Machine Learning à la Volkswagen: Entwicklung energieeffizienterer Autos in der Google Cloud
Ahmad Ayad & Henrik Bohlke
Data Scientists, Volkswagen
Dr. Michael Menzel
ML Specialist Customer Engineer, Google Cloud
Volkswagen ist danach bestrebt, nicht nur ästhetische und leistungsstarke, sondern auch energieeffiziente Fahrzeuge zu entwickeln. Dies geschieht in einem iterativen Prozess, bei dem die Designer*innen viele Designentwürfe durchgehen, jeden einzelnen bewerten, das Feedback integrieren und verfeinern.
Der Luftwiderstandsbeiwert eines Fahrzeugs ist dabei einer der wichtigsten Faktoren für die Energieeffizienz. Schätzungen des Luftwiderstandsbeiwerts für mehrere Entwürfe helfen den Konstrukteurinnen und Konstrukteuren, sich beim Experimentieren auf energieeffizientere Lösungen zu einigen. Das Problem ist, dass die Schätzung des Luftwiderstandsbeiwerts ein teurer und zeitaufwändiger Vorgang ist, der entweder einen physischen Windkanal oder eine rechenintensive Simulation erfordert, was zu Engpässen im Feedback-Zyklus führen kann.
Volkswagen und Google Cloud haben deshalb beschlossen, in einem gemeinsamen Forschungsprojekt zu untersuchen, wie Machine Learning zu schnellen und kostengünstigen Schätzungen des Luftwiderstandsbeiwerts eingesetzt werden kann. In diesem Beitrag geht es um die Herausforderungen und Lösungsansätze bei diesem Projekt.
Als Grundvoraussetzung mussten wir zunächst einen Datensatz mit bestehenden Fahrzeugdesigns und ihren Luftwiderstandsbeiwerten sammeln. Dann mussten wir eine geeignete Darstellung der verschiedenen Autos für Machine Learning erstellen. Schließlich begannen wir damit, ein Deep-Learning-Modell darin zu trainieren, den Luftwiderstandsbeiwert vorherzusagen, und dieses Modell dann zu verwenden, um den Luftwiderstand für jedes neue Design effizient zu schätzen.
Darstellung dreidimensionaler Autodesigns
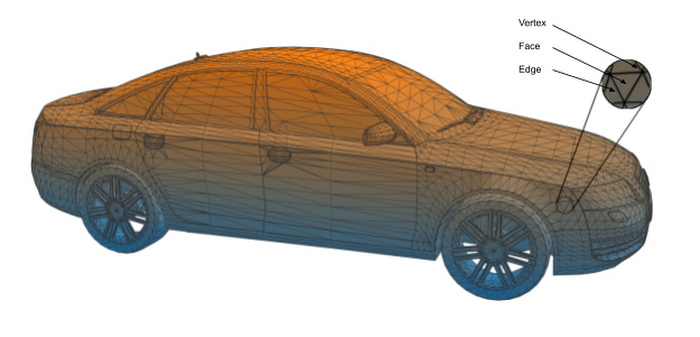
Die verwendete Konstruktionssoftware stellt Automobile als dreidimensionale Dreiecksnetze dar, die aus drei Arten von Objekten bestehen: Flächen, Kanten und Scheitelpunkte. Abbildung 1 zeigt ein solches Netz für einen Audi S6 und hebt die drei Netzkomponenten hervor. Flächen sind flache Oberflächen, wie zum Beispiel das Fenster in einer Autotür. Eine Kante ist die Stelle, an der sich zwei Flächen treffen (etwa die Seite der Tür), und ein Scheitelpunkt ist die Stelle, an der sich zwei oder mehr Kanten treffen, wie zum Beispiel die Ecke der Tür.
Autokarosserien gibt es jedoch in allen Formen und Größen. Ein Volkswagen Golf unterscheidet sich stark von einem Tiguan SUV, und Fahrzeuge können sowohl große glatte Flächen als auch Bereiche mit vielen fein gezeichneten Merkmalen aufweisen, was zu einer Vielfalt zwischen den einzelnen Polygonnetzen führt.
Modelle für Machine Learning benötigen eine einheitliche Darstellung der Automobile, um robuste verallgemeinerte Regeln zu bilden: Bei einer zu großen Varianz zwischen den einzelnen Polygonnetzen könnten die Ergebnisse sonst eine große Fehlerspanne aufweisen.
Wir mussten einen Weg finden, um einfache, für ML-Lernmodelle geeignete Netze zu erstellen, die die Form des Autos korrekt erfassen.
Darstellung eines Autos mit digitaler Schrumpffolie
Anstatt die 3D-Netze jedes Autos von Grund auf neu zu erstellen, wendeten wir die Methode des "Shrink-Wrapping" an – ähnlich wie beim Einschweißen einer Gurke (Abbildung 2). Die Gurke wird dabei in eine Plastiktüte gesteckt, aus der dann nach und nach die Luft entzogen wird, bis die Tüte die Gurke fest umschließt und ihre Form annimmt.
In unserem Ansatz beginnen wir mit einem Grundnetz, wie die Plastiktüte in unserem Beispiel. Wir verformen es, bis es die Form des Zielnetzes – der Gurke – entspricht. Für unsere Zwecke ist das Basisnetz eine vereinfachte Darstellung eines Autos und das Zielnetz ist das spezifische Auto, das wir gerade entwerfen. Solche Meshes können mit den Tensorflow Graphics- und trimesh-Bibliotheken definiert, verwaltet und ML-Lernmodellen zum Training vorgelegt werden.

Unsere "Schrumpffolien"-Methode (oder auch Shrink Wrapping Algorithmus) funktioniert hauptsächlich durch die iterative Minimierung eines Abstandsmaßes (zum Beispiel Fasenabstand) zwischen den Polygonnetzen. Zusätzlich können wir unser Netz regulieren, um bestimmte Eigenschaften wie etwa die Glattheit des resultierenden Netzes zu erhalten. Diese iterative Optimierung ähnelt der Vakuumpumpe, die die Scheitelpunkte des Netzes allmählich schrumpft und es so eng wie möglich an die komplexe Form des Fahrzeugs anpasst. Durch das Schrumpfen können wir exaktere Netze erzeugen, die für unsere Schätzaufgabe besser geeignet sind. Ein Beispiel für dieses Verfahren ist in Abbildung 3 dargestellt.

Wie man ein Modell trainiert
Das Einschrumpfen der 3D-Automodelle war ein wichtiger erster Schritt, doch die Arbeit war noch lange nicht beendet. Unsere nächste Herausforderung bestand darin, die Algorithmen für das Machine Learning zu entwickeln und zu testen.
Wir wollten, dass unsere Algorithmen in der Lage sind, ein neues Design zu betrachten und den Luftwiderstandsbeiwert so genau und schnell wie möglich zu schätzen. Zu diesem Zweck mussten wir das ML-Lernmodell mit den uns vorliegenden Daten trainieren.
Aus öffentlich zugänglichen Datensätzen berechneten wir die Luftwiderstandsbeiwerte für 800 verschiedene Fahrzeugpolygonnetze, mit denen wir die Modelle trainierten. Dann bewerteten wir die trainierten Modelle an weiteren 100 Polygonnetze, um zu sehen, wie genau ihre Schätzungen bei neuen Daten ausfielen.
Im Laufe des Trainings haben wir unseren Ansatz verfeinert. Zunächst testeten wir Modelle auf der Grundlage von faltenden neuronalen Netzen – ähnlich wie PointNet –, die nur die Scheitelpunkte, also die festen Punkte in jedem Netz, beobachteten. Als wir jedoch Modelle mit faltenden neuronalen Netzen für Polygonnetze – ähnlich wie bei FeastNet – testeten, stellten wir fest, dass ein etwas anderer Fokus die Genauigkeit der Schätzungen verbesserte. Diese Modelle konzentrierten sich nicht nur auf die Scheitelpunkte, sondern betrachteten ein Netz von Scheitelpunkten und deren Beziehung zueinander. Diese Modelle setzten jeden Scheitelpunkt in einen umfassenderen Kontext, was zu genaueren Schätzungen führte, wenn die Luftströmung auf besonders fein detaillierte Designmerkmale traf.
Paralleles Arbeiten in großem Maßstab
Für die Zusammenarbeit über Zeitzonen und zwei Organisationen hinweg – nämlich Volkswagen und Google – nutzen wir die Google Cloud Vertex AI-Plattform.
Vertex AI Workbench dient als zentraler Knotenpunkt für die Interaktion mit anderen Diensten und der Infrastruktur auf der Vertex AI-Plattform. Sie hilft beim schnellen Experimentieren sowie bei der Vorbereitung von Programmcode für ressourcenintensive ML-Modell-Trainingsaufträge, und basiert auf einer Python-Notebook-Umgebung, die sofortige Ausführungen von Code erlaubt. Die Notebook-Umgebungen machen eine codebasierte Interaktion mit anderen Diensten auf Google Cloud und ML-Tools wie Vertex AI Training und Vertex AI Pipelines möglich.
Beim Training eines neuen Modells wird zunächst ein Datensatz vorbereitet und in Google Cloud Storage gespeichert, normalerweise mit Hilfe von Tensorflow Datasets. Dann verpacken und speichern wir für jedes ML-Lernmodell, das wir testen wollen, den Trainingscode als Container-Image mit Google Cloud Build und Container Registry. Dadurch wird sichergestellt, dass jeder Auftrag vollständig dokumentiert ist, einschließlich der bereitgestellten Parameter, des Trainingscode-Pakets, der Protokolle der Trainingsaufgabe, und der resultierenden Artefakte wie Metriken und Modelldateien.
Von dort aus übermitteln wir das Modell an den Vertex AI Training Service, der einen einfachen Zugang zu großer Infrastruktur und Hardware-Beschleunigern wie GPUs und TPUs bietet, indem wir einfach den Ressourcenbedarf bei der Übermittlung eines Auftrags definieren. Mit Hilfe der Hyperparameter-Tuning-Funktion von Vertex AI Training können wir Experimente parallel mit mehreren neuronalen Netzen vornehmen, um das richtige für unsere Zwecke zu finden.
Mit Vertex AI Tensorboard können wir Metriken erfassen und die Ergebnisse unserer Experimente visualisieren. Diese sind für jedes Teammitglied, egal wo auf der Welt, für eine breitere Diskussion leicht zugänglich.
Der erste Meilenstein
Die gemeinsame Forschungsarbeit von Volkswagen und Google hat mit Hilfe der KI-Plattform Vertex vielversprechende Ergebnisse hervorgebracht. Mit unserem ersten Meilenstein ist es dem Team gelungen, die jüngsten KI-Forschungsergebnisse einen Schritt näher an die praktische Anwendung für das Autodesign heranzuführen. Die erste Iteration des Algorithmus kann nun innerhalb einer Sekunde eine Schätzung des Luftwiderstandsbeiwerts mit einem durchschnittlichen Fehler von nur 4 Prozent erstellen.
Eine Varianz von 4 Prozent ist zwar nicht ganz so genau wie ein physikalischer Windkanaltest, aber gut genug, um eine große Auswahl an Designkandidaten auf eine kleine Shortlist einzugrenzen. Und wenn man bedenkt, wie schnell die Schätzungen erscheinen, haben wir eine wesentliche Verbesserung gegenüber den bisherigen Methoden erzielt, die Tage oder Wochen benötigen. Mit dem von uns entwickelten Algorithmus können Designer mehr Effizienzprüfungen durchführen, mehr Kandidaten einreichen und in einem Bruchteil der Zeit, die sie früher benötigten, zu detailreicheren und effektiveren Designs übergehen.
Schnellere und genauere Schätzungen könnten in Zukunft sogar eine automatisierte Suche nach effizienten Entwürfen bereitstellen, was sowohl den Ingenieur*innen als auch den Designer*innen helfen würde, sich auf die Bereiche der Fahrzeugkarosserie zu konzentrieren, in denen sie die größten Verbesserungen erzielen können. Ein wichtiger nächster Schritt wird die Integration der Ergebnisse in 3D-Konstruktionssoftware sein, damit die Konstrukteur*innen von ihnen profitieren und Feedback geben können.
Im weiteren Verlauf konzentrieren wir uns auf die Verbesserung der Genauigkeit der Modelle. Dazu werden wir einen größeren Datensatz mit besserer Qualität erstellen und damit unseren Shrink Wrapping Algorithmus optimieren, um mehr Details zu erfassen. Schließlich werden wir unsere bestehenden Modelle verbessern, indem wir mit Vertex AI Neural Architecture Search experimentieren, um verschiedene Optionen für die neuronale Architektur zu erforschen und zu testen.
Unsere Ergebnisse für die Schätzung des Luftwiderstandsbeiwerts sind lediglich ein Ausgangspunkt für weitere Untersuchungen. Es könnte zahlreiche Anwendungsfälle im Bereich der physikalischen Simulationen und Betrachtungen geben, bei denen Kosten- und Zeiteinsparungen durch ML-basierte Schätzungen erzielt werden könnten.