Dashboards zur Optimierung der Abfrageleistung in BigQuery
Kaitlin Ardiff
Strategic Cloud Engineer
BigQuery ist das führende Datenanalyse-Tool von Google, mit dem Unternehmen jeder Größe Analyse-Workloads ausführen können. Damit Sie BigQuery optimal nutzen können und Ihre Anwendungen zuverlässig laufen, ist es wichtig, Ihre Workloads zu verstehen und im Blick zu behalten. Mit den INFORMATION_SCHEMA-Ansichten von Google ist es so einfach wie nie zuvor, die Nutzung von BigQuery im gesamten Unternehmen nachzuverfolgen. Heute zeigen wir Ihnen, wie Sie Ihre BigQuery-Reservierung überprüfen und die Abfrageleistung optimieren.
Workloads und Reservierungen
In einem ersten Schritt analysieren wir die bisherige Slot-Auslastung in Ihrem Unternehmen. Über Reservierungen können Sie bestimmten Gruppen von GCP-Projekten im Unternehmen Kapazitäten, sogenannte Slots, zuweisen. Sie sollten Projekte nach Workloads, Teams oder Abteilungen gruppieren. Es ist empfehlenswert, diese Projektgruppen bzw. spezifischen Workloads in voneinander getrennten Reservierungen zu isolieren. Dies erleichtert das Monitoring und die allgemeine Ressourcenplanung, um Wachstumstrends im Auge zu behalten.
In der Praxis kann dies so aussehen: Sie definieren Geschäftseinheiten wie Marketing oder Finanzen und trennen bekannte, dauerhafte Workloads wie ETL-Pipelines von eher kurzfristigen wie dem Erstellen von Dashboards. Durch das Isolieren von Workloads wirken sich Bursts bei der Ressourcennutzung in einer Reservierung nicht negativ auf eine andere Reservierung aus. Ein plötzlicher Anstieg aufgrund eines Dashboard-Jobs hat somit keinen Einfluss auf die ETL-Zeitpläne. Dadurch werden Störungen durch unerwartete Spitzen minimiert und Sie können die SLOs für Ihre Reservierungen einhalten, sodass Jobs pünktlich abgeschlossen werden.
Funktionsweise der Planung
Damit Sie verstehen, warum die Isolierung so wichtig ist, sollten Sie die Funktionsweise des BigQuery-Planers kennen. BigQuery geht bei der Zuweisung von Slots nach dem Prinzip der Fairness vor. Zuerst weist BigQuery Slots auf Reservierungsebene zu. In einer Reservierung werden die Slots dann gleichmäßig auf alle aktiven Projekte verteilt. Ein aktives Projekt ist eines, in dem aktuell eine Abfrage ausgeführt wird. Innerhalb der aktiven Projekte werden die Slots wiederum den laufenden Jobs zugewiesen, um deren Fortschritt sicherzustellen.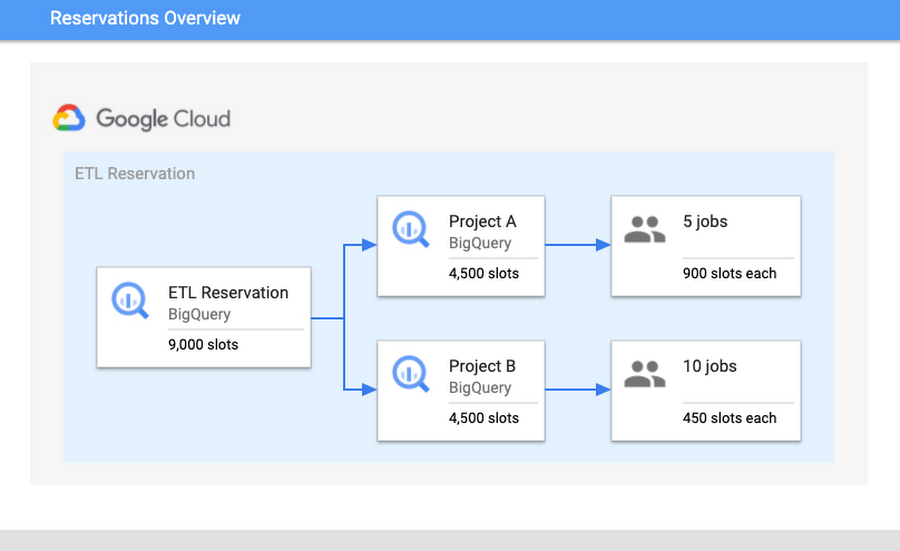
Nehmen wir folgendes Szenario: Die Reservierung „ETL“ hat 9.000 Slots und beinhaltet Projekt A und Projekt B. In Projekt A werden derzeit fünf Jobs ausgeführt und in Projekt B zehn. Wenn wir davon ausgehen, dass für jeden Job die maximal verfügbare Anzahl von Slots nötig ist, um diesen abzuschließen, erhält jedes Projekt 4.500 Slots. Den fünf Jobs in Projekt A werden also jeweils 900 Slots zugewiesen und den zehn Jobs in Projekt B jeweils 450 Slots. Damit Fortschritte erzielt werden, werden diese Slot-Zuweisungen auf Jobebene abhängig von den Anforderungen jedes Jobs und des aktuellen Status kontinuierlich neu berechnet.
Nachdem Sie die Isolierungskonfiguration optimiert haben, können Sie als Nächstes die Nutzung analysieren und die Slot-Zuweisung festlegen. Eine hohe Slot-Auslastung deutet auf eine gute Kosteneffizienz hin. Dies bedeutet, dass die Ressourcen, für die Sie bezahlen, nicht inaktiv sind. Allerdings sollten Sie keine Auslastung von nahezu 100 % anstreben, da Ihnen sonst kein Puffer mehr für mögliche Auslastungsspitzen bleibt. Falls es zu einer solchen Spitze kommt und die Auslastung über 100 % steigt, entsteht Konkurrenz um die verfügbaren Ressourcen, was zu einer Verlangsamung der Anwendungen für Ihre Nutzerinnen und Nutzer führt.
Abfrageleistung steigern und überwachen
Für die Überwachung der Abfrageleistung zeigen wir Ihnen, worauf Sie achten sollten, welche gängigen Ursachen für Probleme es gibt und wie Sie diese beheben können – um schließlich die Abfrageleistung für Ihre Jobs zu steigern.
Wir beginnen mit einem Vergleich der Daten aus den INFORMATION_SCHEMA-Ansichten. Damit die Unterschiede in der Abfrageleistung deutlich werden, nehmen wir zwei ähnliche Abfragen und vergleichen deren INFORMATION_SCHEMA-Jobdaten. Hinweis: Es ist wichtig, dass die Jobs ähnlich sind und voraussichtlich vergleichbare Ausgaben haben. Sie können z. B. die Ausführung desselben Jobs in Stunde A und Stunde B vergleichen oder die Ergebnisse eines Jobs, mit dem Partitionen an Datum A und Datum B gelesen wurden.
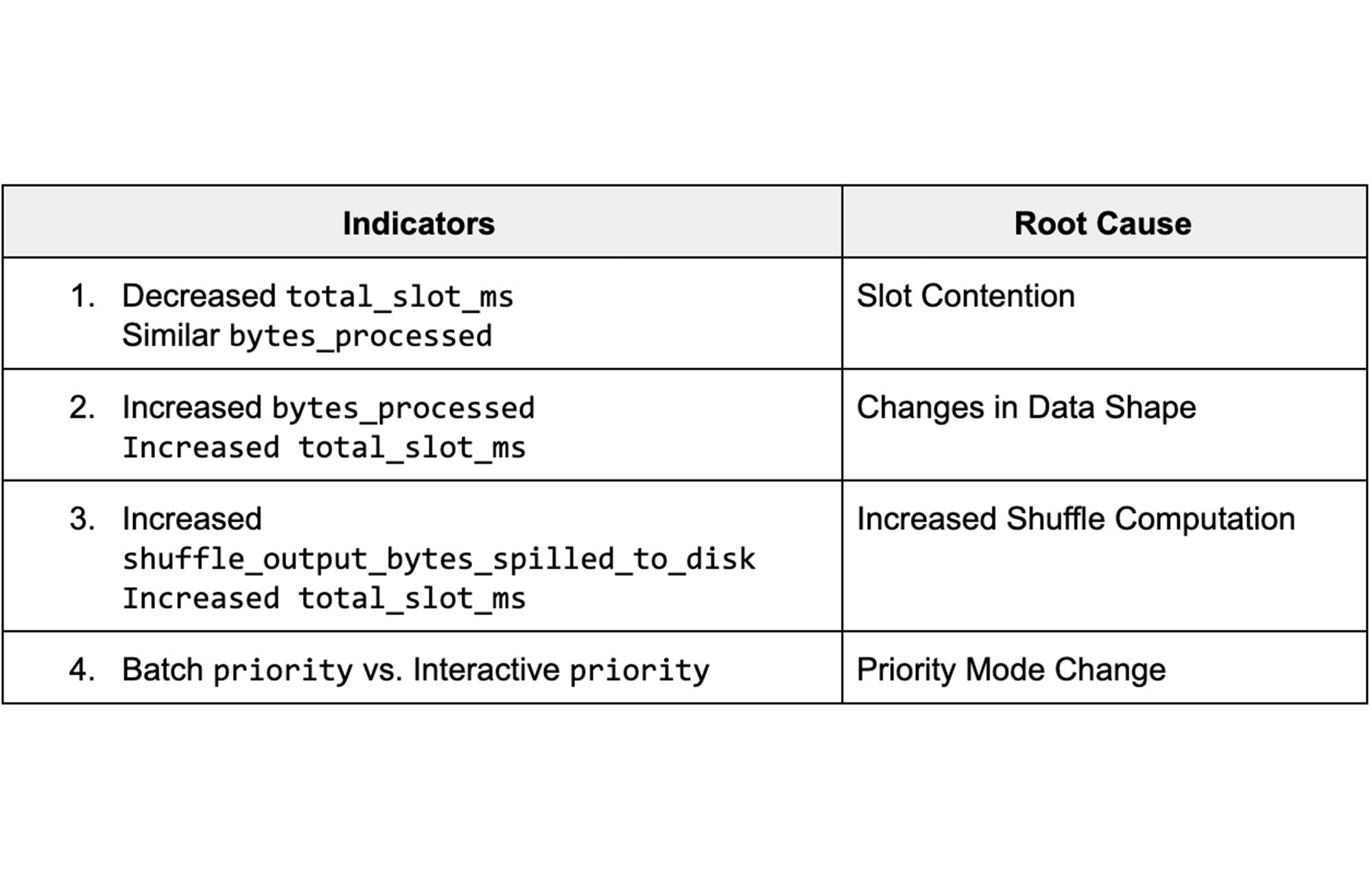
Die Daten aus den Ansichten liefern verschiedene Jobstatistiken, die sich auf die Abfrageleistung auswirken. Wenn wir verstehen, wie die Statistiken zwischen verschiedenen Ausführungen variieren, können wir potenzielle Ursachen für Verzögerungen erkennen und herausfinden, wie sich diese beheben lassen. In der folgenden Tabelle sind die wichtigsten Schlüsselindikatoren und die zugehörigen Ursachen aufgeführt.
Dashboard „Query Job Comparison“
Wir beginnen mit unserem öffentlichen Dashboard, das INFORMATION_SCHEMA-Testdaten von Google zum Vergleich der Abfrageleistung von Jobs enthält.
Sehen wir uns die einzelnen Ursachen und die Möglichkeiten, sie mit dem „System Tables“-Dashboard zu diagnostizieren, einmal genauer an. Zuerst geben wir die ID eines langsamen und eines schnellen Jobs ein, um die Jobstatistiken miteinander zu vergleichen.
1. Slot-Konflikte
Hintergrund
Slot-Konflikte können entstehen, wenn die Nachfrage nach Slots höher ist als die Anzahl der Slots, die der Reservierung zugeteilt sind. Da sich Projekte/Jobs in einer Reservierung die vorhandenen Slots gleichberechtigt teilen, erhält jedes Projekt bzw. jeder Job weniger Slots, wenn mehr Projekte/Jobs aktiv sind. Zur Diagnose von Slot-Konflikten können Sie die INFORMATION_SCHEMA-Zeitleistenansichten verwenden. Damit lässt sich die Gleichzeitigkeit auf Projekt- und Jobebene analysieren.
Monitoring
Wir sehen uns bei diesem Anwendungsfall verschiedene Szenarien an: Zuerst prüfen wir, ob total_slot_ms bei den Abfragen unterschiedliche Werte aufweist. Wenn ein Job langsamer ausgeführt wurde und deutlich weniger Slots genutzt hat als der andere, bedeutet dies in der Regel, dass er auf weniger Ressourcen zugreifen konnte, da er mit anderen aktiven Jobs in Konkurrenz stand. Bevor wir diese Annahme überprüfen können, befassen wir uns mit dem Thema Nebenläufigkeit:
1. Nebenläufige Projekte: Wenn sich der Job in einer Reservierung befindet, verwenden wir die Zeitleistenansicht JOBS_BY_ORGANIZATION, um die Anzahl der aktiven Projekte während der langsamen und schnellen Abfrage zu berechnen. Abfragejobs werden langsamer ausgeführt, wenn die Anzahl der aktiven Projekte in einer Reservierung steigt. Dies lässt sich mathematisch so darstellen: Wenn es Y Projekte in einer Reservierung gibt, erhält jedes Projekt 1/Y der gesamten Slots dieser Reservierung. Dies liegt an dem bereits beschriebenen BigQuery-Algorithmus für die faire Planung.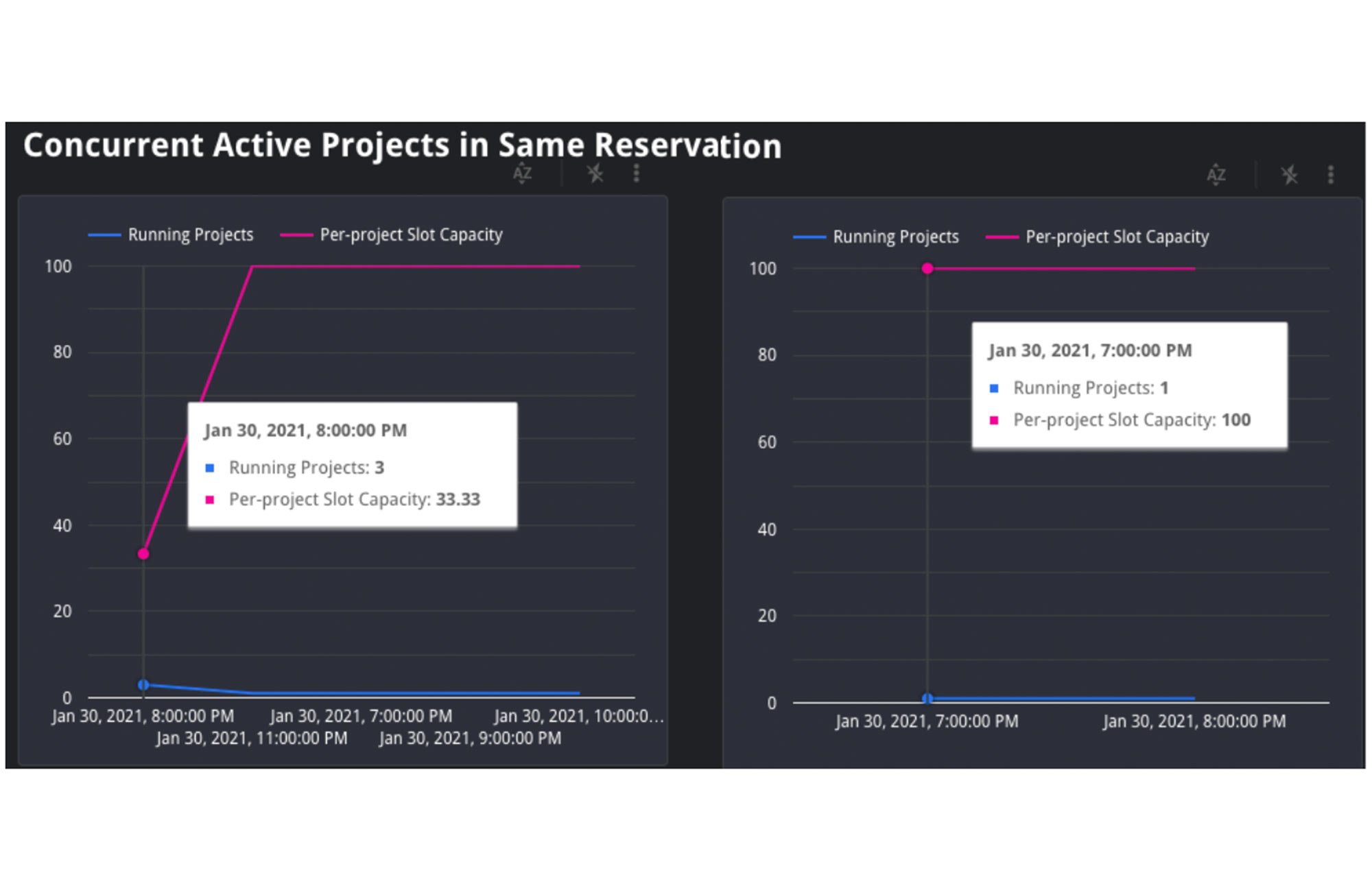
An dem Diagramm oben lässt sich ablesen, dass es beim Start des linken Jobs drei aktive Projekte gab, die gleichzeitig um die 35 Slots der Reservierung konkurrierten. In diesem Szenario erhielt jedes Projekt 1/3 der 35 Slots der Reservierung, also etwa 12 Slots. Das Diagramm rechts zeigt jedoch nur ein aktives Projekt. Der Job erhielt also alle 35 Slots.
2. Nebenläufige Jobs: Anhand der Zeitleistenansicht JOBS_BY_PROJECT können wir das Verhalten innerhalb eines Projekts analysieren. Wenn die Anzahl der nebenläufigen Jobs hoch ist, bedeutet dies, dass all diese Jobs zur selben Zeit um Ressourcen konkurrieren. Da die Nachfrage hoch ist, stehen für jeden einzelnen Job weniger Slot-Ressourcen zur Verfügung, was dazu führen kann, dass Abfragen langsamer als üblich ausgeführt werden.
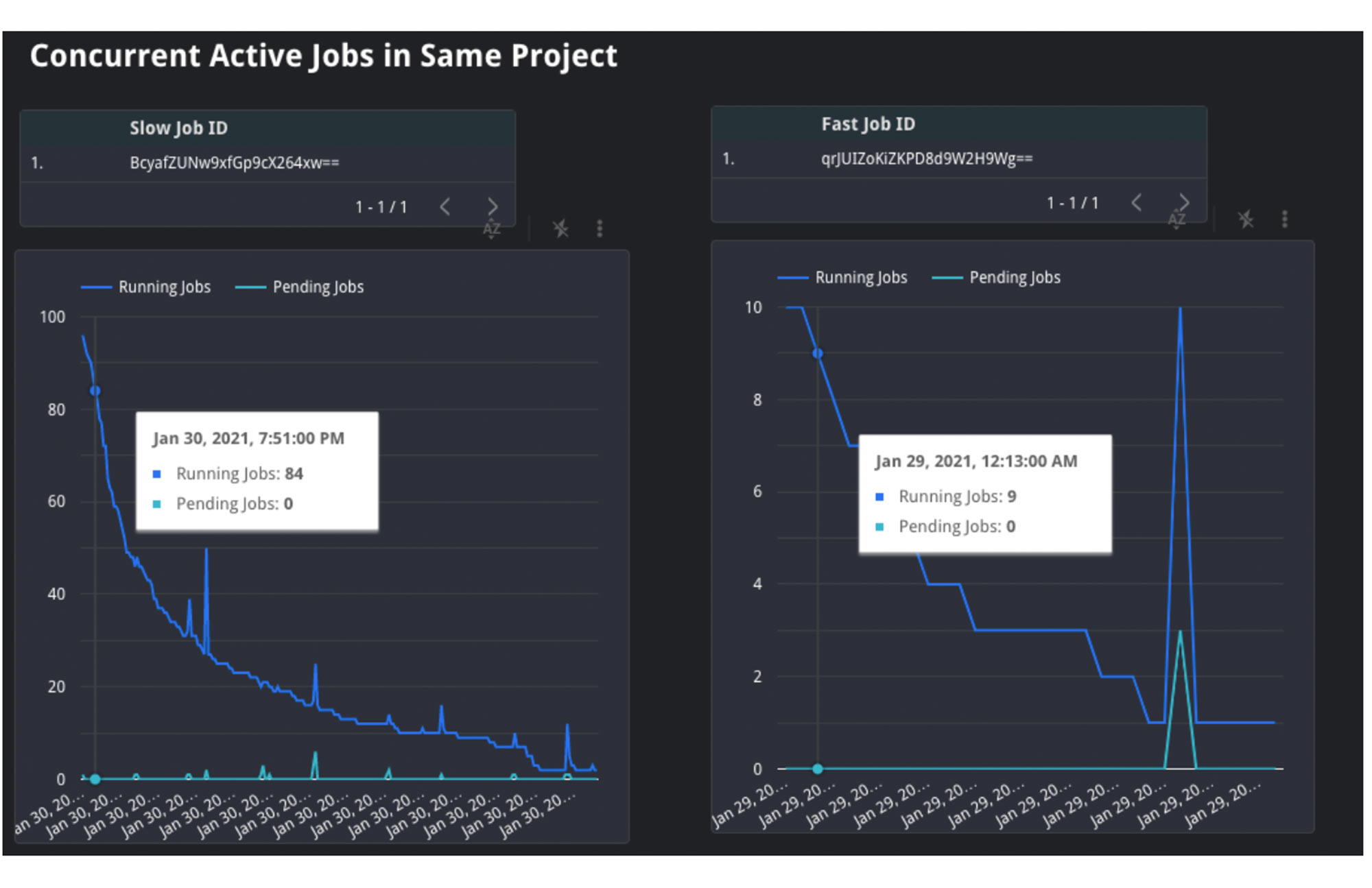
An dem Diagramm oben können Sie ablesen, dass die langsam ausgeführte Abfrage links während der Ausführung mit 20 bis 100 anderen Jobs um Ressourcen konkurrierte. Die schnell ausgeführte Abfrage auf der rechten Seite hatte dagegen während ihrer Ausführung nur zwischen 4 und 26 „Konkurrenten“. Daraus lässt sich schließen, dass die Menge der gleichzeitigen aktiven Jobs links vermutlich der Grund für die geringe Geschwindigkeit und lange Dauer war.
3. Inaktive Slots: Außerdem können wir noch versuchen herauszufinden, ob inaktive Slots verwendet wurden. Inaktive Slots sind eine optionale Konfigurationsmöglichkeit für Reservierungen. Wenn Sie diese Option aktivieren, können sich Reservierungen verfügbare Slots teilen. Auf diese Weise werden Slots nicht durch nicht inaktive Reservierungen verbraucht. Wenn ein Job bei der Ausführung Zugriff auf inaktive Slots hat, kann er voraussichtlich schneller ausgeführt werden, da er dank der inaktiven Slots zusätzlich zur normalen Zuteilung der Reservierung mehr Ressourcen zur Verfügung hat. Leider lässt sich dies derzeit nicht an den INFORMATION_SCHEMA-Daten ablesen. Allerdings ist der Auslastungsprozentsatz der Reservierung während der Ausführung ein guter Hinweis darauf, ob inaktive Slots verfügbar waren. Falls die Auslastung der Reservierung über 100 % lag, müssen Slots einer anderen Reservierung genutzt worden sein.
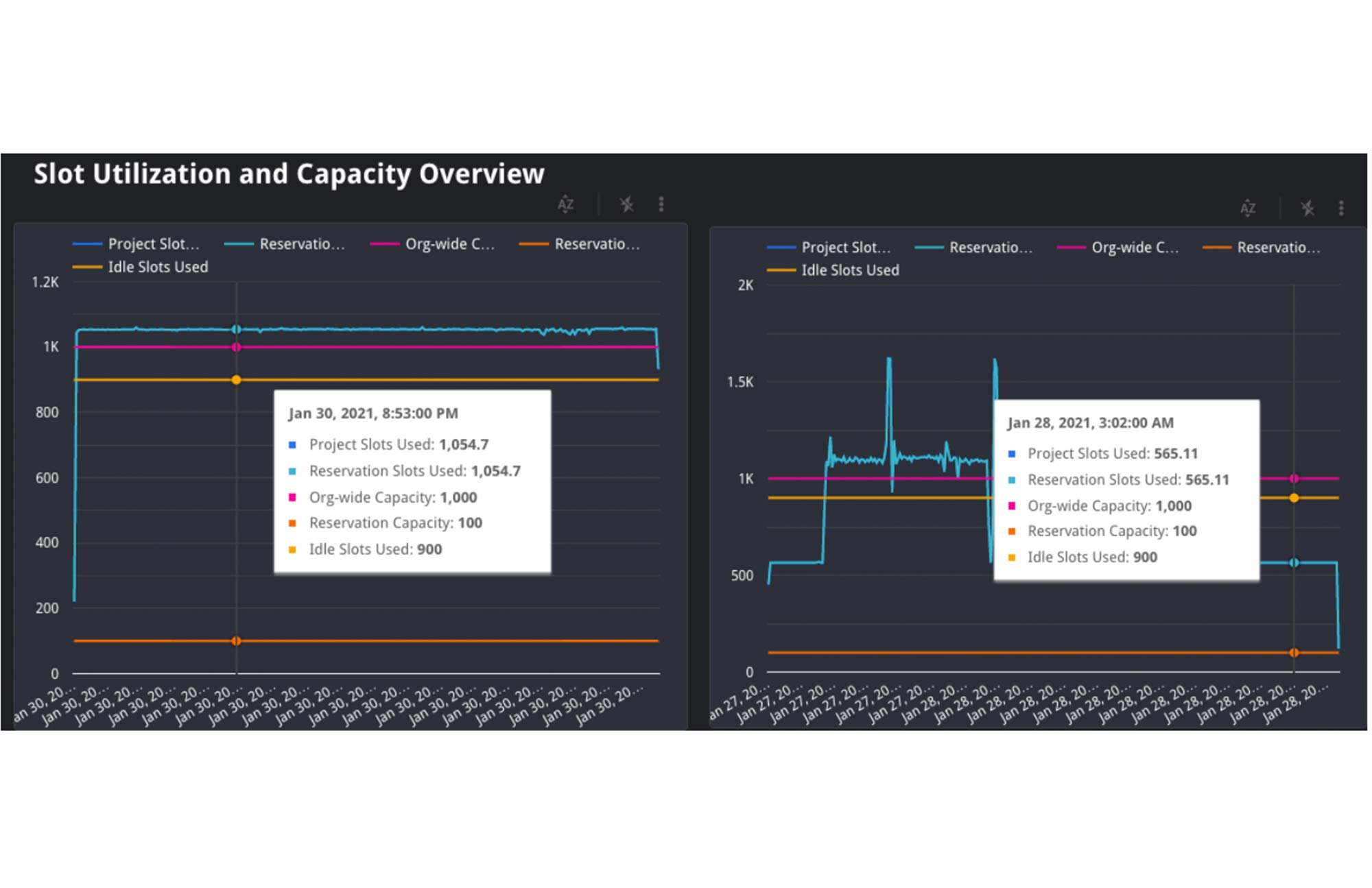
In dem Diagramm oben sehen Sie die Kapazität des Unternehmens und der Reservierung sowie die Menge der von der Reservierung genutzten Slots. In diesem Fall haben die Jobs der Reservierung links 1.055 Slots genutzt, was deutlich über der Kapazität von 100 liegt. Da das Unternehmen eine Kapazität von 1.000 hat und die Reservierung nur eine Kapazität von 100, muss sie 900 inaktive Slots einer anderen Reservierung innerhalb des Unternehmens verwendet haben. Hinweis: In seltenen Fällen kann es vorkommen, dass ein Unternehmen bei Migrationen innerhalb des Rechenzentrums oder bei Projekten, die zusätzliche On-Demand-Slots verwenden, mehr als die erworbene Kapazität nutzt.
Möglichkeiten zur Behebung des Problems
Wenn die Ursache ein Slot-Konflikt ist, benötigen Sie eine Möglichkeit, dem Job Zugriff auf mehr Slots zu verschaffen. Dafür haben Sie mehrere Optionen:
1. Mehr Slots erwerben: Dies ist die einfachste Option. Sie können eine neue Zusicherung für Slots in der Reservierung kaufen, um garantiert mehr Ressourcen zur Verfügung zu haben. Je nach prognostiziertem Bedarf können Sie jährliche bzw. monatliche Zusicherungen oder Flex-Slots erwerben.
2. Slot-Mengen pro Reservierung neu zuweisen: Wenn der Kauf von mehr Slots für Ihr Unternehmen keine Option ist, können Sie die vorhandenen Slots den Reservierungen prioritätsabhängig neu zuweisen. Sie können beispielsweise eine bestimmte Menge von Slots aus Reservierung A der Reservierung B zuteilen. Durch die Vergrößerung der Zuweisung für Reservierung B werden Jobs dort schneller ausgeführt als bisher, da die Kapazität jetzt höher ist. Die Jobs in Reservierung A werden dann allerdings vermutlich langsamer ausgeführt.
3. Jobs umplanen, um die Anzahl nebenläufiger Jobs zu minimieren: Wenn es nicht möglich ist, Ressourcen zwischen Reservierungen zu verschieben, können Sie möglicherweise den zeitlichen Ablauf der Jobs ändern, um die Kapazitätsauslastung der Reservierung im Tagesverlauf zu optimieren. Führen Sie nicht dringende Jobs außerhalb der Spitzenzeiten aus, z. B. an Wochenenden oder über Nacht. Wenn Sie die Last über den ganzen Tag verteilen, gibt es zu Spitzenzeiten weniger Konkurrenz um die Slots. Informationen zu Auslastungstrends finden Sie im Hourly Usage Report.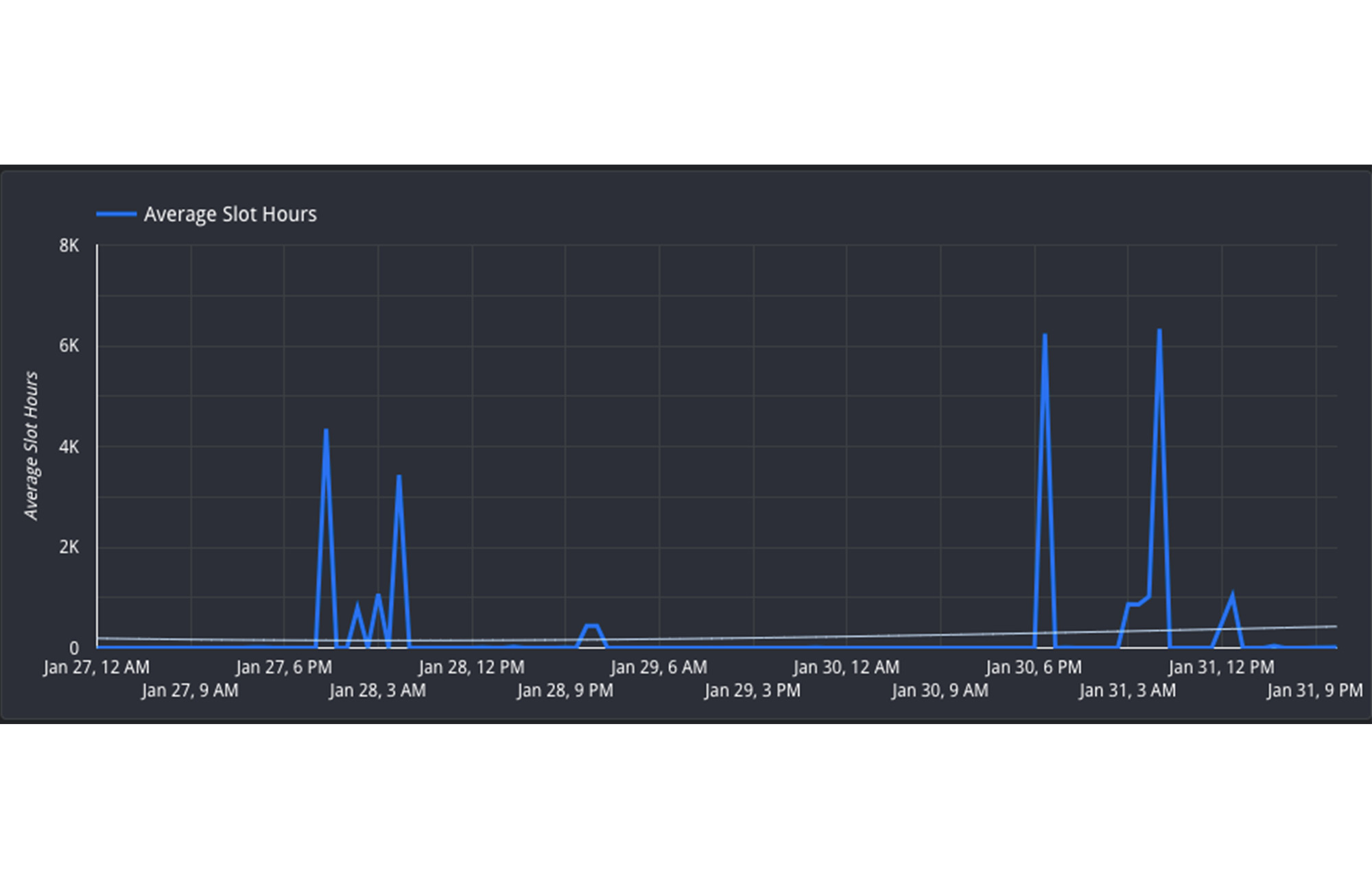
In dieser Ansicht sehen Sie, dass die Reservierung am 27. und 30. Januar jeweils zwischen 16:00 Uhr und 8:00 Uhr (UTC) aktiv ist. In der Zeit von 8:00 Uhr bis 16:00 Uhr (UTC) ist die Auslastung jedoch geringer. Dieser Zeitraum liegt außerhalb der Spitzenzeit. Daher wäre es sinnvoll, Jobs umzuplanen und zwischen 8:00 Uhr und 16:00 Uhr ausführen zu lassen, um die Ressourcenauslastung zu optimieren.
2. Änderungen der Datenform
Hintergrund
Ein weiterer Grund für unerwartete Änderungen bei der Dauer können die zugrunde liegenden Daten selbst sein. Hier gibt es zwei Möglichkeiten: Entweder die zugrunde liegenden Quelltabellen enthalten mehr Daten als bei früheren Ausführungen oder zwischenzeitliche Unterabfragen führen dazu, dass bei Ausführung der Abfrage mehr Daten verarbeitet werden.
Monitoring
Zuerst können Sie überprüfen, ob das Feld total bytes processed aufgrund von Änderungen in der Abfrage einen höheren Wert enthält. Wenn der Wert zwischen dem schnellen und dem langsamen Job gestiegen ist, bedeutet dies, dass mehr Daten als üblich verarbeitet wurden. Die Ursache lässt sich auf zwei Wegen ermitteln:
1. Wenn der Wert höher ist, waren in der Abfrage mehr Daten zu analysieren. Prüfen Sie, ob der Abfragetext selbst unverändert geblieben ist. Wenn eine JOIN-Anweisung verschoben oder die Filterung durch eine WHERE-Klausel aktualisiert wurde, kann dies bedeuten, dass mehr Daten gelesen werden mussten.
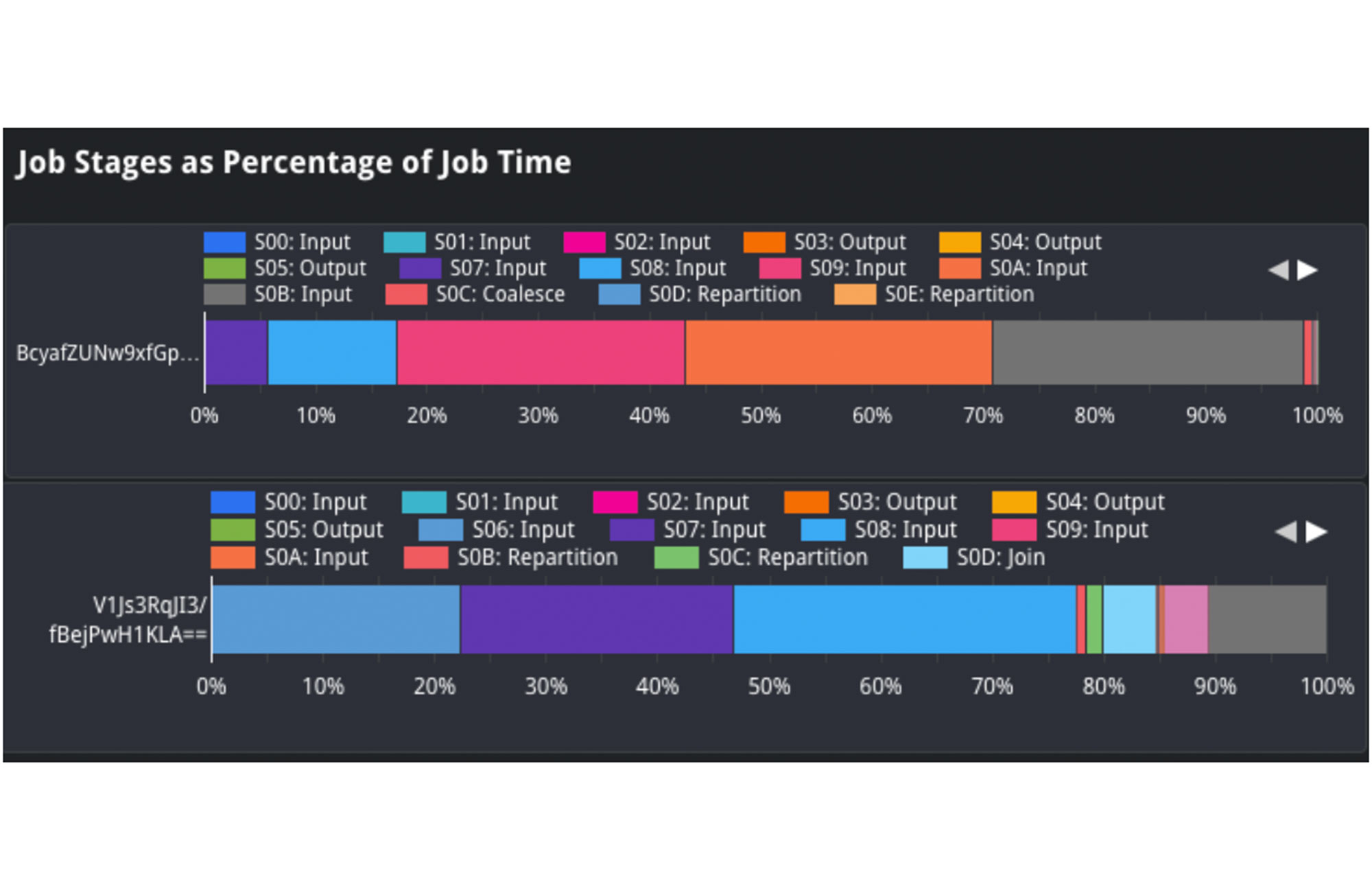
In der Ansicht „Job Stages as Percentage of Job Time“ können wir die Form der Eingabedaten analysieren und zwischen verschiedenen Abfragen vergleichen. Wir können beispielsweise den Prozentsatz der Eingabedaten des langsamen und des schnellen Jobs vergleichen und so sehen, wie viele Daten aufgenommen wurden. Wenn wir uns die Eingabe in Phase 2 ansehen, stellen wir fest, dass auf diese bei dem oberen Job etwa 25 % der Verarbeitungszeit entfiel. Bei dem unteren Job erforderte sie dagegen nur 1–2 % der Verarbeitungszeit. Dies deutet darauf hin, dass die in Phase 2 aufgenommene Quelltabelle vermutlich größer geworden ist, was der Grund für die langsamere Ausführung des Jobs sein könnte.
2. Außerdem sollten wir die Größe der Quelltabellen für die Abfrage analysieren. Im Feld referenced_tables sehen wir alle Quelltabellen, die von der Abfrage verwendet werden. Wir vergleichen die Größe der Quelldaten zum Zeitpunkt der Abfrage. Sollte die Größe signifikant zugenommen haben, ist dies vermutlich ein Grund für die langsame Ausführung.
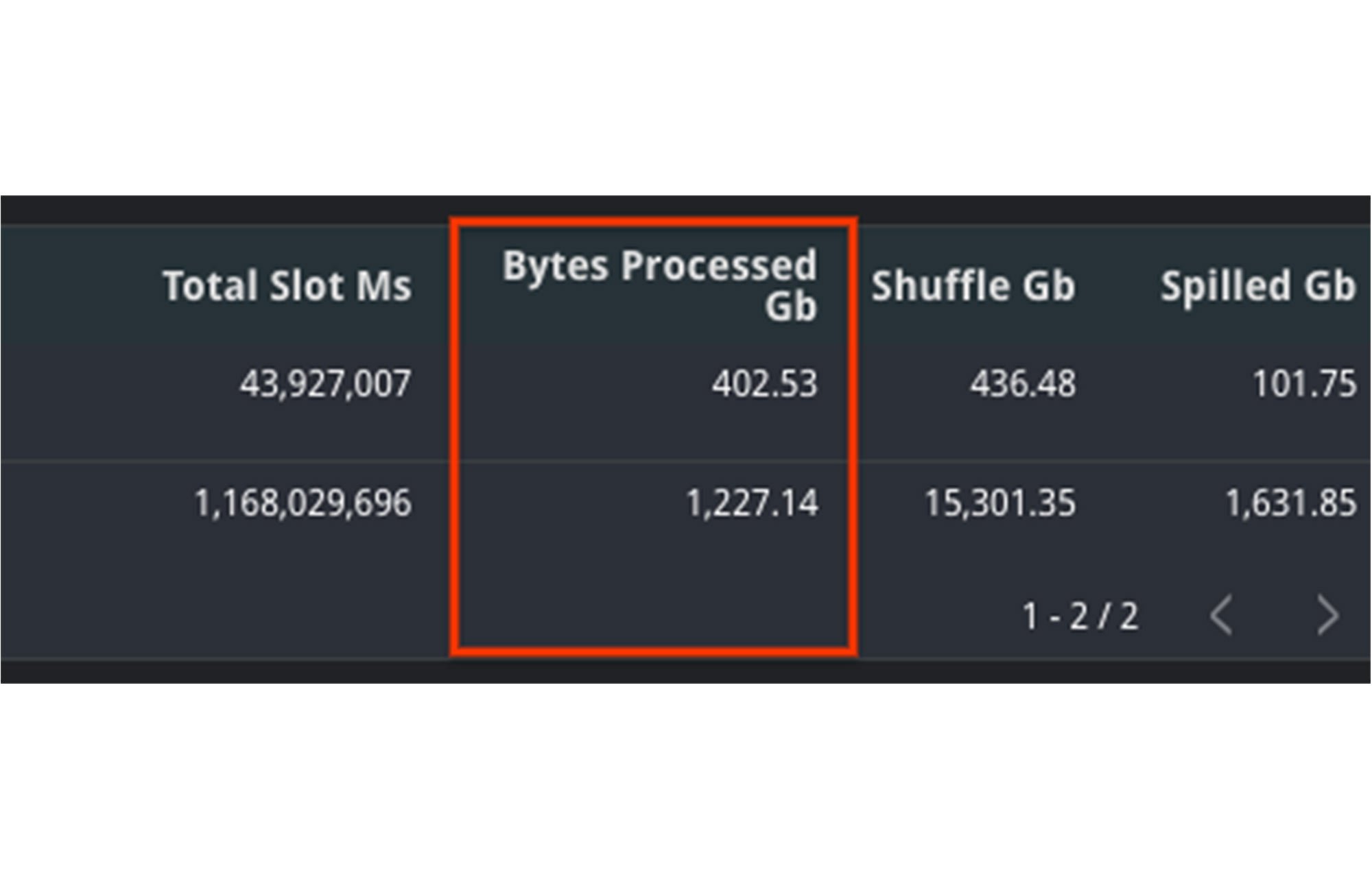
In diesem Beispiel sehen wir, dass die Menge an verarbeiteten Byte zwischen den beiden Jobs deutlich gestiegen ist. Dies sorgte wahrscheinlich für die langsamere Ausführung des zweiten Jobs. Darauf deutet auch die Tatsache hin, dass der Wert im Feld „total_slot_ms“ ebenfalls höher ist. Obwohl mehr Slots verfügbar waren, dauerte die Abfrage trotzdem länger.
Möglichkeiten zur Behebung des Problems
1. Clustering: Je nach Abfrage können Sie die Abfrageleistung möglicherweise durch Clustering steigern. Clustering eignet sich für Abfragen, die Filter und Zusammenfassungen verwenden, da dabei ähnliche Spalten zusammen gruppiert werden. Dadurch reduziert sich die Menge der gescannten Daten, jedoch lassen sich deutliche Steigerungen in der Abfrageleistung nur bei Tabellen mit einer Größe von mehr als einem Gigabyte beobachten.
2. Menge der Eingabedaten verringern: Versuchen Sie herauszufinden, ob es eine Möglichkeit gibt, den Abfragetext zu optimieren, damit nur die erforderlichen Daten gelesen werden. Sie könnten zum Beispiel früher filtern und dafür WHERE-Anweisungen an den Anfang der Abfrage stellen, um unnötige Datensätze herauszufiltern. Alternativ können Sie die SELECT-Anweisung ändern, um nur erforderliche Spalten einzubeziehen, anstatt „SELECT *“ zu verwenden.
3. Daten denormalisieren: Wenn Ihre Daten über- und untergeordnete Elemente oder andere hierarchische Beziehungen beinhalten, ergänzen Sie das Schema um verschachtelte und wiederkehrende Felder. So kann BigQuery die Ausführung parallelisieren und schneller abschließen.
3. Größerer Shuffle-Arbeitsspeicher
Hintergrund
Jobs verwenden Slots als Computing-Ressourcen sowie Shuffle-Arbeitsspeicher, um den Zustand eines Jobs zu überwachen und Daten im Verlauf der Abfrage von einer Ausführungsphase in die nächste zu verschieben. Dieser geteilte Zustand ermöglicht die parallele Verarbeitung und Optimierung der Abfrage. Die Größe des Shuffle-Arbeitsspeichers hängt von der Menge der verfügbaren Slots in einer Reservierung ab.
Da Shuffle ein speicherinterner Vorgang ist, steht nur eine begrenzte Arbeitsspeichermenge für jede Phase der Abfrage zur Verfügung. Wenn zu einem bestimmten Zeitpunkt zu viele Daten verarbeitet werden, z. B. bei einem großen Join, oder wenn es zu einer starken Datenverzerrung zwischen Joins kommt, kann es sein, dass eine Phase zu viele Ressourcen benötigt und ihr Shuffle-Arbeitsspeicherkontingent überschreitet. An diesem Punkt werden Shuffle-Byte an das Laufwerk übergeben, wodurch Abfragen langsamer ausgeführt werden.
Monitoring
Für die Diagnose sollten Sie sich zwei verschiedene Messwerte ansehen: den vom Job verbrauchten Shuffle-Arbeitsspeicher sowie die Anzahl der verwendeten Slots. Das Shuffle-Arbeitsspeicherkontingent hängt von der Slot-Kapazität ab. Eine gleichbleibende Slot-Menge sowie eine steigende Shuffle-Verarbeitung im Laufwerk deuten darauf hin, dass dies die Ursache der Verlangsamung ist.
Vergleichen Sie den aggregierten Wert von shuffle_output_bytes_spilled_to_disk aus der TIMELINE-Ansicht. Wenn mehr Byte an das Laufwerk übergeben werden, deutet dies darauf hin, dass die Jobs nicht mehr richtig ausgeführt werden. Die Ausführung erfolgt also nicht schnell genug, um sie rechtzeitig zu beenden.
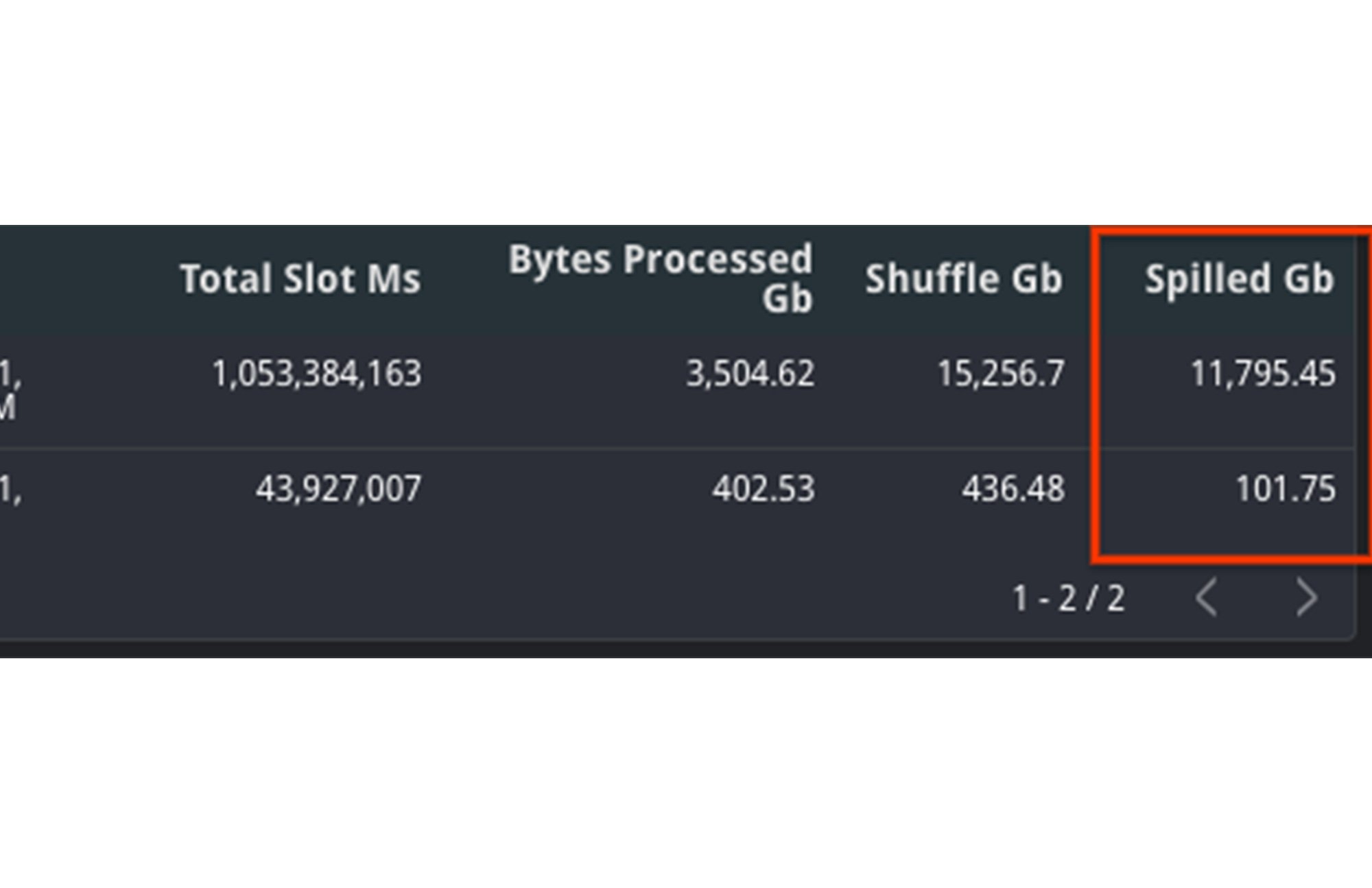
In diesem Beispiel sehen Sie, dass die an das Laufwerk übergebene Datenmenge bei der langsamen Abfrage deutlich höher ist. Zusätzlich ist auch die Gesamtmenge der Slots gestiegen. Obwohl mehr Ressourcen verfügbar waren, dauerte die Abfrage dennoch länger.
Möglichkeiten zur Behebung des Problems
Eine Zunahme der an das Laufwerk übergebenen Byte bedeutet, dass es in BigQuery Probleme gibt, den Zustand zwischen den Ausführungsphasen einer Abfrage aufrechtzuerhalten. Sie sollten daher versuchen, den Abfrageplan selbst zu optimieren, damit zwischen den Phasen weniger Byte übergeben werden.
1. Daten früh filtern: Reduzieren Sie die von der Abfrage aufgenommene Datenmenge durch frühes Filtern mit WHERE-Klauseln vor dem Verknüpfen von Tabellen. Verwenden Sie außerdem nicht „SELECT *“, sondern wählen Sie nur die notwendigen Spalten aus.
2. Partitionierte Tabellen anstatt fragmentierter Tabellen verwenden: Versuchen Sie es anstatt mit fragmentierten Tabellen lieber mit partitionierten Tabellen. Bei fragmentierten Tabellen muss in BigQuery zusätzlich zur Zustandspflege eine Kopie des Schemas und der Metadaten verwaltet werden, was die Abfrageleistung beeinträchtigen kann.
3. Anzahl der Slots erhöhen: Da die Größe des Shuffle-Arbeitsspeichers von der Menge der Slots abhängt, lässt sich durch eine Erhöhung der Slot-Anzahl die Menge der vom Arbeitsspeicher an das Laufwerk übergebenen Byte verringern. Wie bereits im Abschnitt zur Problembehebung eines Slot-Konflikts erwähnt, können Sie entweder eine neue Zusicherung erwerben oder dieser Reservierung mehr Slots zuweisen.
4. Abfrage neu schreiben: Da der Job den Zustand der Daten zwischen den Phasen nicht aufrechterhalten kann, können Sie das Problem auch beheben, indem Sie die Abfrage neu schreiben. Dies kann bedeuten, den SQL-Code so zu optimieren, dass Anti-Patterns vermieden werden. Reduzieren Sie zum Beispiel die Anzahl der Unterabfragen oder eliminieren Sie CROSS JOINs. Eine weitere Möglichkeit wäre, die Abfrage in mehrere verkettete Abfragen zu unterteilen, deren Ausgabedaten zwischen den einzelnen Abfragen in temporären Tabellen gespeichert werden.
4. Prioritätsmodus
Hintergrund
In BigQuery werden Abfragen in zwei Prioritätsmodi ausgeführt: interaktiv oder als Batch. Standardmäßig führt BigQuery Jobs im interaktiven Modus aus, also sobald Ressourcen verfügbar sind.
Monitoring
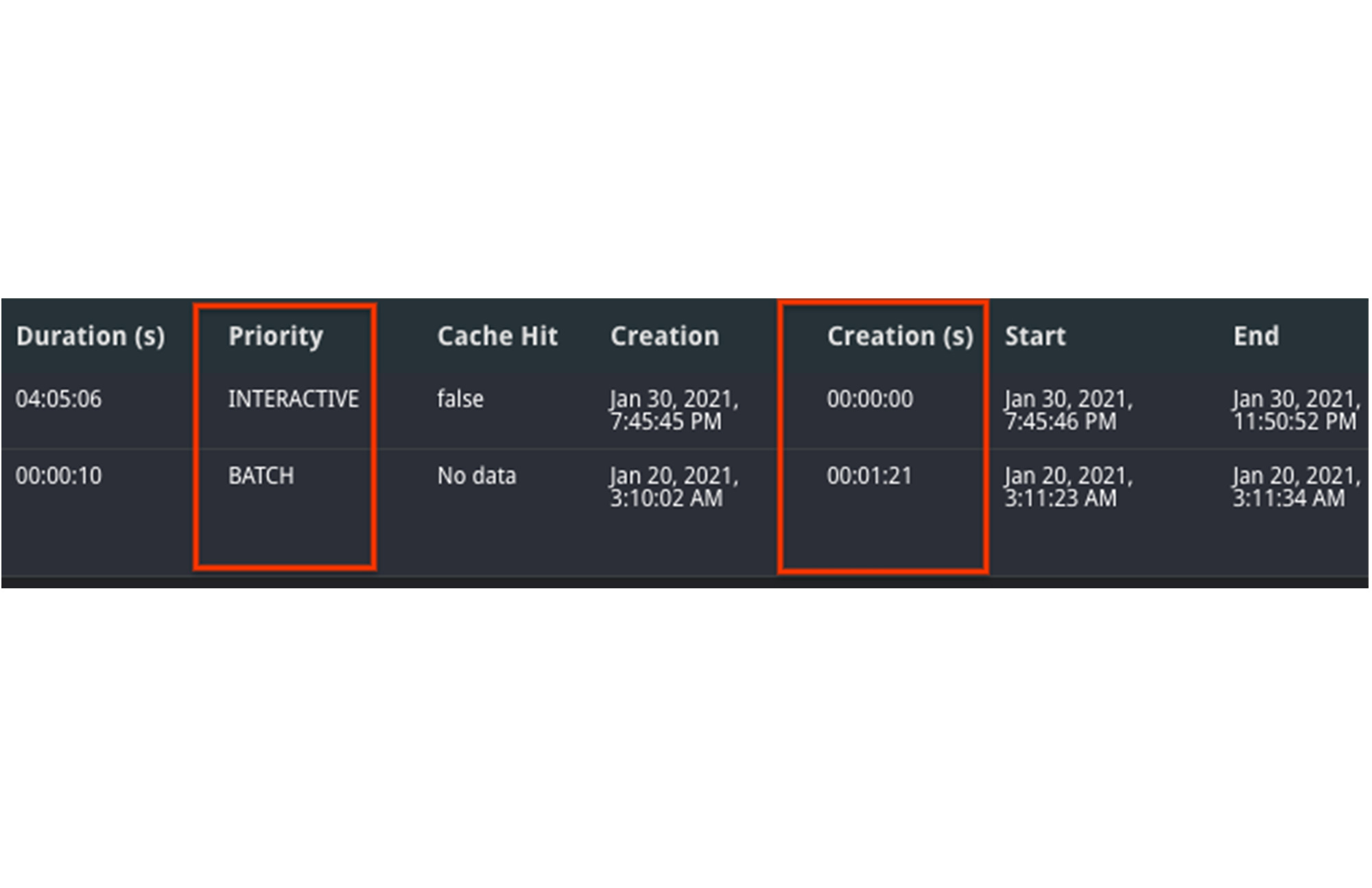
1. Den Modus finden Sie in der Spalte „Priority“ des Jobs. Batchjobs werden möglicherweise langsamer ausgeführt als interaktive Jobs.
2. Wenn beide Jobs im Batchmodus ausgeführt wurden, vergleichen Sie den Zustand im Zeitverlauf. Möglicherweise befand sich ein Job längere Zeit im Zustand PENDING in der Warteschlange, da bei der Erstellung keine Ressourcen verfügbar waren, um ihn auszuführen. Dies sehen Sie an dem Wert in der Spalte Creation (s). Er gibt an, wie lange sich der Job in der Warteschlange befand, bevor er gestartet wurde.
Möglichkeiten zur Behebung des Problems
1. Sehen Sie sich die verschiedenen Prioritäten und SLOs der Jobs an. Wenn Ihr Unternehmen weniger wichtige Jobs hat, lassen Sie diese im Batchmodus ausführen, damit wichtigere Jobs zuerst erledigt werden. Die Batchjobs werden in die Warteschlange gestellt, bis die interaktiven Jobs beendet sind bzw. inaktive Slots verfügbar werden.
2. Finden Sie heraus, wie groß die Differenz des Kontingents für gleichzeitige Abfragen zwischen Batch- und interaktiven Jobs ist. Batch- und interaktive Jobs haben unterschiedliche Kontingente für gleichzeitige Abfragen. Standardmäßig sind Projekte auf 100 gleichzeitige interaktive Abfragen begrenzt. Sie können sich an unser Vertriebsteam oder den Support wenden, um dieses Limit bei Bedarf zu erhöhen. Batchjobs werden außerdem ggf. in die Warteschlange gestellt, damit interaktive Jobs sicher innerhalb des vorgegebenen Zeitfensters von sechs Stunden beendet werden.
3. Wie bereits im Abschnitt zu Slot-Konflikten erwähnt, können Sie auch mehr Slots für die Reservierung erwerben oder Jobs außerhalb von Spitzenzeiten ausführen lassen, wenn der Ressourcenbedarf nicht so groß ist.
Wie Sie sehen, gibt es viele Möglichkeiten, Herausforderungen mit Abfragejobs anhand der Daten in INFORMATION_SCHEMA zu beheben. Probieren Sie es hier selbst aus, indem Sie zwei beliebige Job-IDs verwenden.