Memvisualisasikan grafik menggunakan BigQuery DataFrames
Dokumen ini menunjukkan cara memetakan berbagai jenis grafik menggunakan library visualisasi BigQuery DataFrames.
bigframes.pandas API
menyediakan ekosistem alat lengkap untuk Python. API ini mendukung operasi statistik lanjutan, dan Anda dapat memvisualisasikan agregasi yang dihasilkan dari DataFrame BigQuery. Anda juga dapat beralih dari
DataFrame BigQuery ke DataFrame pandas dengan operasi pengambilan sampel bawaan.
Histogram
Contoh berikut membaca data dari tabel bigquery-public-data.ml_datasets.penguins untuk memetakan histogram pada distribusi kedalaman culmen penguin:
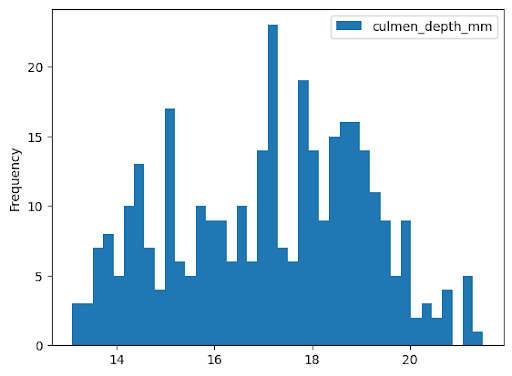
Diagram garis
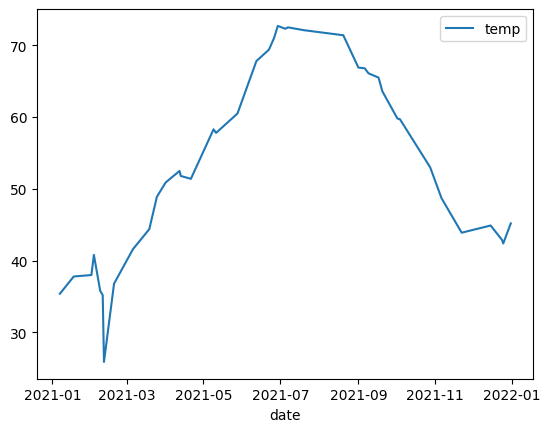
Contoh berikut menggunakan data dari tabel bigquery-public-data.noaa_gsod.gsod2021
untuk memetakan diagram garis perubahan suhu median sepanjang tahun:

Diagram area
Contoh berikut menggunakan tabel bigquery-public-data.usa_names.usa_1910_2013 untuk melacak popularitas nama dalam sejarah AS dan berfokus pada nama Mary, Emily, dan Lisa:

Diagram batang
Contoh berikut menggunakan tabel bigquery-public-data.ml_datasets.penguins untuk memvisualisasikan distribusi jenis kelamin penguin:
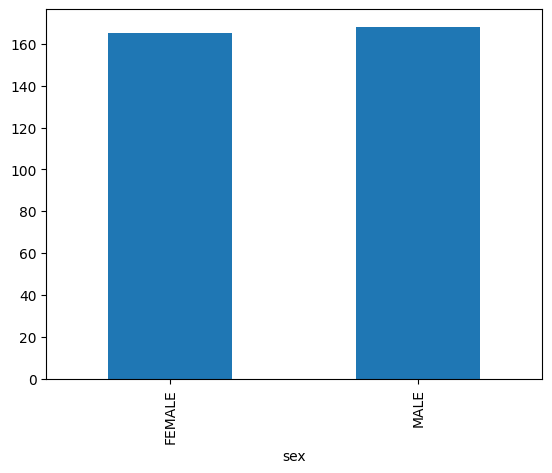
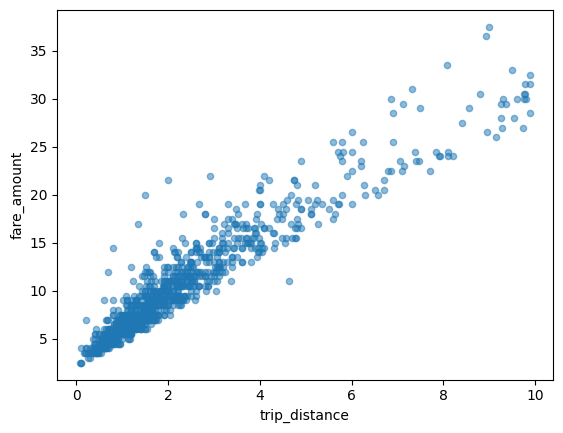
Diagram sebar
Contoh berikut menggunakan
tabel bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2021 untuk
menjelajahi hubungan antara jumlah tarif taksi dan jarak perjalanan:
Memvisualisasikan set data besar
BigQuery DataFrame mendownload data ke mesin lokal Anda untuk visualisasi. Jumlah titik data yang akan didownload dibatasi hingga 1.000 secara default. Jika jumlah titik data melebihi batas, BigQuery DataFrames akan mengambil sampel secara acak sejumlah titik data yang sama dengan batas.
Anda dapat mengganti batas ini dengan menyetel parameter sampling_n saat memetakan
grafik, seperti yang ditunjukkan pada contoh berikut:
Plotting lanjutan dengan parameter pandas dan Matplotlib
Anda dapat meneruskan lebih banyak parameter untuk menyesuaikan grafik seperti yang dapat Anda lakukan dengan pandas, karena library pembuatan grafik BigQuery DataFrames didukung oleh pandas dan Matplotlib. Bagian berikut menjelaskan contohnya.
Tren popularitas nama dengan sub-plot
Dengan menggunakan data histori nama dari contoh diagram area, contoh berikut membuat grafik individual untuk setiap nama dengan menetapkan
subplots=True dalam panggilan fungsi plot.area():
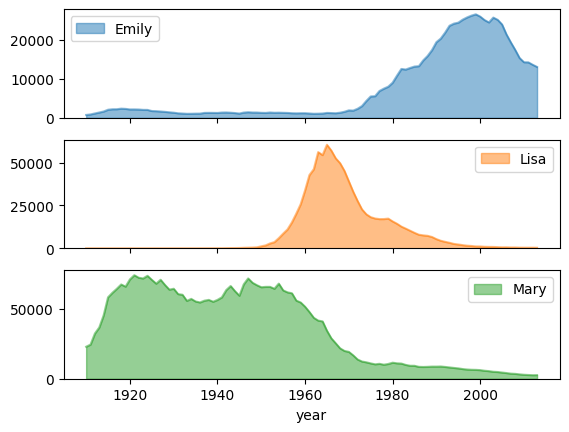
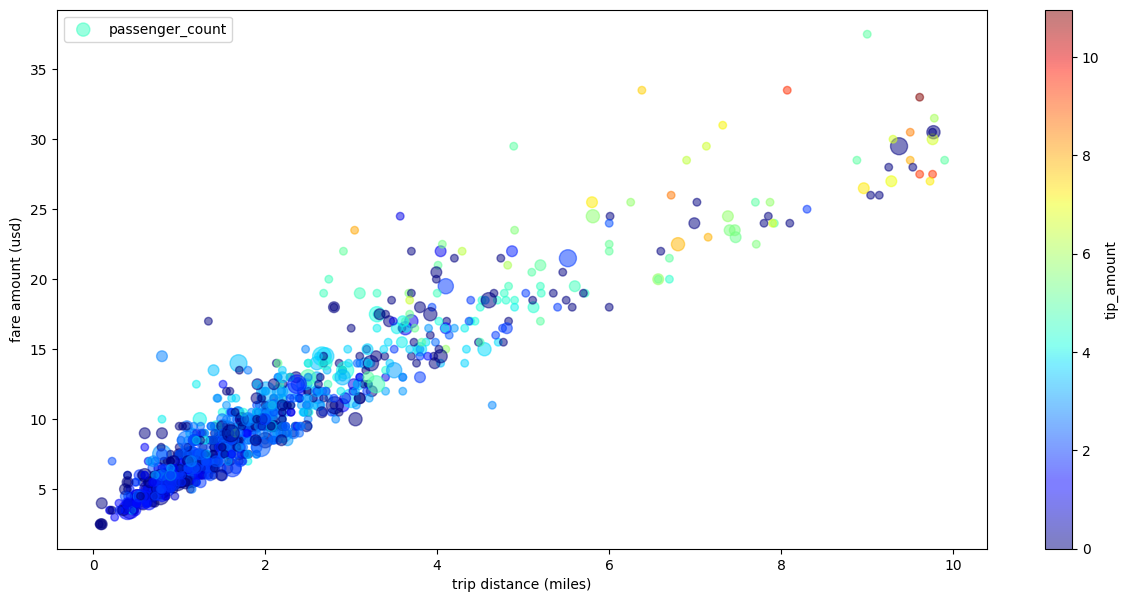
Diagram sebar perjalanan taksi dengan beberapa dimensi
Dengan menggunakan data dari contoh diagram pencar, contoh berikut mengganti nama label untuk sumbu x dan sumbu y, menggunakan parameter passenger_count untuk ukuran titik, menggunakan titik warna dengan parameter tip_amount, dan mengubah ukuran gambar:
Langkah berikutnya
- Pelajari cara menggunakan DataFrame BigQuery.
- Pelajari cara menggunakan DataFrame BigQuery di dbt.
- Jelajahi referensi BigQuery DataFrames API.