To stay informed about the health of Google Cloud products, check the following:
Personalized Service Health - provides a personalized view of Google Cloud products and regions used by your projects or across your organization. Check Personalized Service Health for communications about active and past Google Cloud incidents that might impact your projects and resources.
You can access Personalized Service Health through the following:
- Console dashboard, accessible through the Google Cloud console.
- Alerts
- Service Health API
Google Cloud Service Health - provides the following:
- A platform-wide view of the health of all Google Cloud products across Google Cloud regions.
- Google Cloud incidents with widespread impact.
Google Cloud Service Health is available to everyone through the following:
- Google Cloud Service Health dashboard
- RSS Feed
Use Personalized Service Health as the first stop when facing a service disruption for specific products, as Personalized Service Health will always have the most information available to Google Cloud customers. Read more about Personalized Service Health and how to integrate it into your incident management workflow.
You can also check for active disruptions in the Google Cloud console Support page. The known issues displayed in the Google Cloud console Support page also include minor and limited-scope incidents. The known issues page lets you create a case from a posted incident so that you get regular updates and can talk to support staff. Support cases are appropriate for issues that don't qualify as incidents or where a one-to-one human touch is needed. If you have Premium, Enhanced, or Standard Support, you can report an incident by creating a support case in the Google Cloud console. Otherwise, you can use this form.
This document focuses on Google Cloud Service Health.
What is Google Cloud Service Health
Google Cloud Service Health provides information on ongoing widespread incidents that meet certain criteria and the status of Google Cloud products organized by region and global locale. This information can include product disruptions, outages, or informational messages about a temporary issue.
Google Cloud Service Health is designed to be available in the rare event Personalized Service Health itself is unavailable or affected by a disruption, or the impacted product has not yet onboarded to Personalized Service Health.
When does an incident appear in Google Cloud Service Health
For most Google Cloud incidents, impacted customers receive incident communications directly through Personalized Service Health in the Google Cloud console. If they meet the alert conditions, these incidents also trigger Service Health alerts that you configured.
Incidents that meet any of the following criteria appear in Google Cloud Service Health:
- Major, public incidents
- Incidents for Google Cloud products that are not yet available in Personalized Service Health
- Incidents that occur when the Personalized Service Health dashboard is unavailable
Major incident
Google Cloud defines an incident as a major incident if it meets all of the following conditions:
- High scope - The incident has global impact or is affecting a significant percentage of customer projects across one or more regions.
- High severity - One or more products are unavailable or severely degraded.
In the rare instance a major incident occurs, we act with urgency to resolve any issues.
During a major incident, the status of the issue is communicated through the Google Cloud Service Health Dashboard. A major incident is marked as Service outage on the status dashboards. After the issue is resolved, we publish a public incident report that includes the details of the factors that contributed to the incident and the steps we plan to take to prevent such incidents from reoccurring.
In the case of smaller-scoped incidents, a nonpublic report might be made available to customers.
Lifecycle of an incident
When a product degradation is detected, the Google Cloud Support team and product engineering team work together to resolve the incident and provide you with updates.
The following diagram shows the responsibilities of the product engineering and support teams:

You can read more about each of these responsibilities in the following sections.
Detection
Google Cloud uses internal and black box monitoring to detect incidents. For more information, see Chapter 6 of the Site Reliability Engineering book.
Initial response
When an incident is detected, the Google Cloud Customer Care team manages customer communications. Initial notification of an incident is often sparse, frequently only mentioning the product in question. This is because we prioritize fast notification over detail. Detail can be provided in subsequent updates.
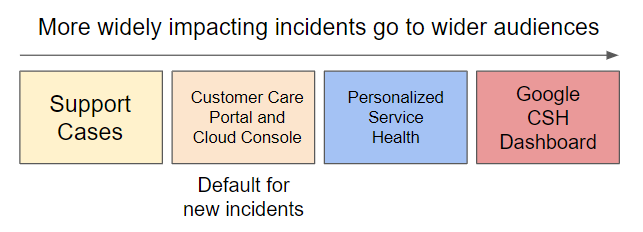
To provide you as much information as possible without overwhelming you with issues that don't affect you, different communication channels are used depending on the scope and severity of an issue:
Investigate
Product engineering teams are responsible for investigating the root cause of incidents. Incident management is often done by Site Reliability Engineers but might be done by software engineers or others, depending on the situation and product. For more information, see Chapter 12 of the Site Reliability Engineering Book.
Mitigation and Fix
An issue is considered fixed only when changes have been made that Google is confident will end the impact indefinitely. For example, the fix could be rolling back a change that triggered an incident.
While an incident is in progress, Customer Care and the product team attempt to mitigate the issue. Mitigation is when the impact or scope of an issue can be reduced, for example, by temporarily providing additional resources to a product suffering overload.
If no mitigation has been found, when possible, the Customer Care team finds and communicates workarounds. Workarounds are steps that you can take to solve the underlying need despite the incident. A workaround might be to use different settings for an API call to avoid a problematic code path.
Follow up
While an incident is ongoing, the Customer Care team provides regular updates. Updates typically provide:
More information about the incident, such as error messages, zones or regions affected, which features are affected, or percentages of impact.
Progress towards mitigation, including any workarounds.
Timelines for communication, tailored to the incident.
Changes in status, such as when an incident is fixed.
Postmortem
All incidents have a postmortem internally to fully understand the incident and identify reliability improvements that Google can make. These improvements are then tracked and implemented. For more information on postmortems at Google, see Chapter 15 of the Site Reliability Engineering Book.
Incident report
When incidents have very wide and serious impact, Google provides incident reports that outline the symptoms, impact, root cause, remediation, and future prevention of incidents. As with postmortems, we pay particular attention to the steps that we take to learn from the issue and improve reliability. Google's goal in writing and releasing postmortems is to be transparent and demonstrate our commitment to building stable products for our customers.
Incident data model
An incident impact one or more products in one or more locations. Incidents have a start time and an end time, and an overall severity. An incident has updates that describe how the incident changes over time, including its status and the then impacted locations. The incident information is made available through a JSON schema.
The JSON schema has fields marked Stable and Unstable. In general, ID fields are considered Stable whereas fields such as display names are considered Unstable and may be changed without warning. Use Stable fields only when integrating with an external system or building automation. See Can I build integrations to consume the data displayed on the Google Cloud Service Health Dashboard programmatically?.
FAQ
Where can I find information about past product disruptions and outages?
Google Cloud Service Health keeps a record of disruptions and outages for the Google Cloud products for up to five years. The Overview tab of the dashboard shows the current status of the products by locale. To view information about product disruptions and outages in the last year, click View history on the dashboard. To view a product's outage history for the last five years, click See more for that product.
How can I view regionalized status information for Google Cloud products?
Google Cloud Service Health displays the status of all Google Cloud products organized by region and global locale. To view the status for a multi-region, select the region-specific tab.
Can I build integrations to consume the data displayed in Google Google Cloud Service Health programmatically?
Yes, you can consume the data displayed on the Google Cloud Service Health in the following ways:
- Through an RSS feed
Through a JSON History file
You can download the schema for JSON file here.
The RSS feed and JSON History file provide incident status information which can be consumed through integrations.
Use the fields marked Stable in the JSON History file, instead of the fields
marked Unstable. Example: if you're trying to programmatically identify
incidents impacting a particular set of products, use the product IDs
(affected_products>id), not their display names.
Product IDs versus product names
Historically, Google Cloud Service Health didn't provide a mechanism for locating the ID for a given product. Since early 2023, Google Cloud Service Health made available a product catalog which provides this mapping for all products. A product ID provides a stable field to key off while allowing the display name of a product to change. Prefer referencing the product ID when programmatically identifying incidents impacting a set of products.
What if I have prebuilt integrations based on the Google Cloud Service Health prior to the introduction of regionalized status reporting and name change to Google Cloud Service Health Dashboard?
In both the RSS feed and the JSON file, the regional status information is additive to the information that was already being published prior to the introduction of regionalized status reporting and change in the name of Google Cloud Service Health. Therefore, we expect your existing integrations to continue working. However, if you want to consume the regional status information through your integrations, then you need to modify them.
Here's a detailed description of how regional information is presented in both RSS feed and JSON file:
RSS feed
The regional status information is a new addition to the feed information that was provided prior to the introduction of regionalized status. Any locations that are reported as affected are appended to the RSS message.
JSON file
Prior to the regional status update, Google Cloud published a stream of incidents where each incident contained a list of affected products and a list of status updates for each, if any. These status updates contained an unstructured string field that did or did not contain the location information.
Now, Google Cloud publishes a stream of incidents just as it did before. However, for every incident, each status update contains the following new fields:
updates.affected_locations: contains a structured list of affected locations at the time the update was posted. Every update record and themost_recent_updaterecord contain this field.currently_affected_locations: contains the most recent information on the locations that are actively impacted by the incident. Unlikeupdates.affected_locations, this list becomes empty after the incident is resolved (that is, whenendis set to a non-empty value).previously_affected_locations: contains a list of locations that were previously impacted during an incident, but aren't currently. As the incident progresses, some locations might have an outage resolution. These locations will still exist in thepreviously_affected_locations field. Once the incident is resolved (that is, whenendis set to a non-empty value), this field contains a list of all locations that were impacted during this incident.
What if I am experiencing an issue, but it is not listed on the dashboard?
The Google Cloud Service Health dashboard provides current and historical status information for any major incident that affects Google Cloud products and services. If you are experiencing an issue that is not listed on the dashboard, the issue may be isolated to your projects or instances, or it may be impacting a limited number of customers. Incidents that have less scope may be listed on the Customer Care Portal. You can contact Customer Care about any issues you are experiencing that are not listed on the dashboard.
If you are already using the Personalized Service Health dashboard, check if the issue is listed there to determine if your project or instance is affected.
If you are using Google Cloud console, you can click the Send feedback tool in the upper right corner to report problems.
Who updates the dashboard?
The global Customer Care team monitors the status of products using many different types of signals and updates the dashboard in the event of a widespread issue. If needed, they will post a detailed incident analysis report after an incident has been resolved.