| title | description | author | tags | date_published |
|---|---|---|---|---|
Use Cloud Run and Go to create a customizable serverless proxy for Cloud Storage |
Customize this Go proxy for Cloud Storage to transform, compress, or translate objects in Cloud Storage. |
domz |
Serverless, GCS, Cloud Storage, Cloud Run, Golang, Go, Translate |
2021-06-24 |
Dom Zippilli | Solutions Architect | Google
Contributed by Google employees.
This document shows you how to use Cloud Run to host a streaming proxy for Cloud Storage, which you can use to do custom protocol translation to HTTP and transform responses with relatively little decrease in performance compared to standard Cloud Storage APIs.
The idea of having serverless compute send media to HTTP clients isn't new, but the addition of streaming responses from Cloud Run makes the performance and resource utilization for such services much different. Before this feature, bytes were only sent from Cloud Run and Cloud Functions to clients when the function's response stream to the control plane was closed. This had limitations for some use cases:
- Because the response had to be completely read and then forwarded to the client, there could be significant delays for TTFB (time to first byte). Effectively, the first byte wasn't sent until the function sent its last byte to the control plane.
- There was a limit of 32 MB on responses, which makes sense because the control plane had to hold the entire response in memory in order to forward it.
Streaming responses alleviate both of these concerns. Bytes are sent back to the client as soon as the function writes them. This means that the delay in the delivery of the first byte is not tied to the overall run time of the function, and the responses don't need to sit in control plane memory at all, so they can be any size and put little to no memory pressure on the control plane.
With this change, you can start to imagine serverless, high-performance, low-TTFB proxies for all kinds of services. Anything that could be streamed would have a new performance profile in a serverless system: transcoded video, BigQuery result sets, and so on. This document starts with a simple but useful implementation: an HTTP proxy for Cloud Storage.
You do not need to use the solution described in this document to serve static content from Cloud Storage buckets. There's already an established way to do that, which involves no code and very little management. However, the existing method for serving static content from Cloud Storage buckets has two important limitations:
- It makes the content public. At the time of this writing, it's not really feasible to host a private static website (for example, on a VPC subnet, for intranet purposes) using this feature.
- You can't dynamically modify the content.
In response to customers who could not work within those limitations, the author of this document created
gcs-proxy-cloud-run in
Go as a proof of concept to show the way. The design is simple, and it resembles most HTTP-to-HTTP proxies:
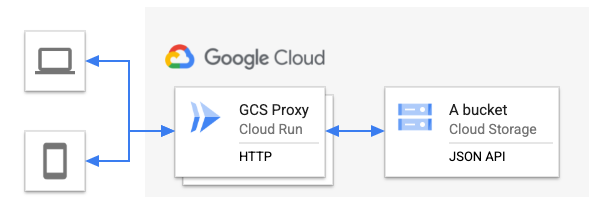
This is not an HTTP-to-HTTP proxy. The backend is the Cloud Storage JSON API. This means that any Cloud Storage operations can be used, abstracted
away from the end-user, who can just use GET to request items.
You can use Cloud IAM for authentication to the bucket. Only the Cloud Run service can access this bucket, and only with the permissions granted. You can use various means to secure the Cloud Run service, such as Cloud Armor or Cloud IAP. This means that this endpoint is not necessarily public, and neither is the data in the bucket.
The gcs-proxy-cloud-run code shows how to write streaming responses and transformations (where possible), so that you can do many kinds of things to the
media that you're serving from Cloud Storage.
Because Cloud Run just runs a container, there are a lot of options for software that could be a proxy to Cloud Storage. The following are some alternatives that were considered:
- Proxies like HAProxy, Nginx, and Envoy: There are several proxies with features like load balancing, caching, and powerful domain-specific languages (DSLs) for configuration. These will work in cases where you like the proxy, and you don't need to do a lot of transformation (or you do, and you're good at Lua). Besides customization, the main problem with these alternatives is that they are typically used with HTTP backends, and the solution described in this document uses the Google Cloud Client SDK for the backend.
net/http/httpproxy: This is a proxy built into Go, and it's useful for HTTP backends. But because the solution described in this document uses the Google Cloud Client SDK for the backend and has some specific requirements for customizations, thegcs-proxy-cloud-runproxy is built on thenet/httplibrary instead.
For your use case, Cloud Run combined with any of the above could be a powerful, low-toil, low-risk way to get the job done.
Go has excellent built-in support for server functionality. From the rich io library that has everything that you need for streaming, to
the http library that makes HTTP server writing easy, to simple concurrency with goroutines, a lot of the gcs-proxy-cloud-run proxy is just glue code. The
real work has been done by the Go developers.
Besides the aforementioned glue code, there are two substantial pieces of code to look at, both of which are optional:
-
config/config.goThis file is where you configure the proxy. Yes, in this case, we recommend that you hard-code the configuration into the binary. When you write expressive Go code that compiles into a configured binary, you get compile-time analysis that catches a lot of mistakes. And with CI/CD, particularly in serverless systems, there's not much difference operationally between configuration in a statically linked binary and a more stable binary that reads a configuration file. Either way, you deploy a new container image when things change. Plus, you don't need to invest in some mini-DSL of a configuration file; just write Go, and extend it however you need to.
You don't need to change this configuration file to use the proxy to just serve static content from Cloud Storage. The bucket name is taken from an environment variable, and the rest of the configuration that you can do with Cloud Run is adequate for both public and private proxies.
-
filter/*.goThis package contains example (and in some cases, rather workable) filters for responses. Wherever possible, these are written as streaming filters, so they add minimal latency and memory pressure to the proxy. These enable you to do such things as logging and filling caches, blocking regular expressions from being served, and translating languages. These filters are optional; the proxy is useful without them. These filters are discussed in more detail later in this document.
If you choose to use filters, take a look at config/pipelines.go for examples of how to chain them together into useful combinations.
Multiple filters combine together into a pipeline, in which the Cloud Storage object media stream is the input, and the client response
stream is the output.
This is the default configuration of gcs-proxy-cloud-run. It simply serves
HTTP GET requests by mapping the GET URL to an object path in a bucket. The
only filter applied is a logging filter, which emits information about the
request and response into the log.
The
Quickstart Deployment
section of the README.md file shows exactly how to do this. To make it easy, the repository
provides shell scripts that build and deploy the service using the gcloud
command line.
To use the scripts to build and deploy the service, do the following:
-
Clone the repository locally.
-
From the repository root directory, run the script:
./build.sh && ./deploy.sh mybucket us-central1Replace
mybucketwith the bucket you want to serve content from. Replaceus-central1with the region where you want the proxy to run.
If everything works and all of the APIs are enabled, you should see the
service named gcs-mybucket in the
Cloud Console.
To see a link to a public endpoint for the service, click the service name in the Cloud Console.
For the service to do anything interesting, you need something at
index.html in your bucket. For example, here is the author's very simple demonstration page loaded in the browser:

This is very straightforward, and returns with acceptable latency. When the author tested this setup, it was from a home internet connection, and the data needed to travel to the Oregon region.

During development, the author ran this proxy in a Docker container on a development workstation. For some workloads, some of the filter configurations—particularly those with caching—might make a proxy like this a good sidecar. Running locally during development, the latency for cached responses was on the order of 2 ms.
Logging messages are available in Logs Explorer for this service, and they show the usual information for an HTTP server.

You could take this configuration a step further and use the proxy to support a static intranet site hosted on Cloud Storage that is secured by using one of the restricted ingress settings. These can be combined with IAM invoker permissions to restrict where requests can ingress to your service, and thus request the content in your Cloud Storage bucket. You could even add dynamic content.
To understand this example of a more complex usage of a Cloud Run proxy for Cloud Storage, it's useful to take a look at the configuration file. The default configuration for the previous example looks like this:
// This function will be called in main.go for GET requests
func GET(ctx context.Context, output http.ResponseWriter, input *http.Request) {
gcs.Read(ctx, output, input, LoggingOnly)
}Here's what this is saying: When a GET request is sent to the Cloud Run service,
the config.GET function is called. You could do whatever you want in this function. You
could write your own code to just print "Hello World!". You could even return
405 -- Method Not Allowed. The function in the default configuration, however, calls the
Read function from the gcs package, which reads a Cloud Storage object and returns it in the response.
The arguments to the Read function are as follows:
- The
contextvalue for the request, established by theProxyHTTPGCSfunction inmain.go. - The
outputandinput, which are required in the entrypoint for a Cloud Run HTTP service. These arguments are passed through without modification to the backend code. LoggingOnly, which is defined in thepipelines.gofile. It is a filter pipeline that simply logs requests.
The LoggingOnly pipeline definition is simple:
// DEFAULT: A proxy that simply logs requests.
var LoggingOnly = filter.Pipeline{
filter.LogRequest,
}This means that responses are run through one filter, filter.LogRequest, which
is a function defined in filter/logging.go.
You can add multiple filters to the pipeline, and they are run in the order in which they appear in the pipeline. So, a pipeline for a proxy that transforms everything to lowercase looks like this:
// EXAMPLE: Send everything lowercase. Undefined behavior with binaries.
var LowercasingProxy = filter.Pipeline{
filter.ToLower,
filter.LogRequest,
}This pipeline runs all of the bytes through bytes.ToLower() and then logs the requests.
Here is the result of deploying the service using the same scripts as in the first demonstration, making no changes to the bucket, and then reloading the webpage:
The filter has transformed Lake Washington to lake washington, and Google Cloud to google cloud.
Network performance and TTFB are unchanged because this filter is a streaming filter.
Here's an example of a streaming filter:
// ToLower applies bytes.ToLower to the media.
//
// This is an example of a streaming filter. This will use very little memory
// and add very little latency to responses.
func ToLower(ctx context.Context, handle MediaFilterHandle) error {
defer handle.input.Close()
defer handle.output.Close()
buf := make([]byte, 4096)
for {
_, err := handle.input.Read(buf)
buf = bytes.ToLower(buf)
handle.output.Write(buf)
if err == io.EOF {
break
} else if err != nil {
return FilterError(handle, http.StatusInternalServerError, "lower filter: %v", err)
}
}
return nil
}The function is of a MediaFilter type, defined in filter/filter.go. A
MediaFilter accepts a MediaFilterHandle, which includes references to
all of the pieces needed to do media filtering:
- the
input, which is either the object media itself or the previous filter's output - the
output, which is either the response stream itself or the next filter's input
The chaining together of filters is taken care of by a pipeline builder
function, also in filter/filter.go.
This filter reads the input 4096 bytes at a time, calls bytes.ToLower on the read bytes, and then sends them along. This is
repeated until the input is exhausted. That's all there is to it.
Without streaming responses, this would still work as it is, but
handle.output.Write wouldn't actually write to the client. For example, if you
ran this function in Cloud Functions, you would find that the writes would be
buffered until the entrypoint function returned, and you would be limited to
32 MB. Effectively, it wouldn't be much different from just reading the entire
object into memory, running ToLower on the whole thing, and then writing it.
Streaming responses make this behave like it was running on a conventional server.
Cloud Storage has built-in decompressive transcoding, which lets you store compressed files and serve them to readers in decompressed form. This compression is great for saving on storage and retrieval costs.
You can also go the other way, to conserve bandwidth by serving compressed objects to clients on mobile or other constrained internet connections. Using a proxy, you can do streaming compressive transcoding.
Begin by editing config/config.go and redeploying the service. This time, you use
ZippingProxy:
// EXAMPLE: Send everything compressed.
var ZippingProxy = filter.Pipeline{
filter.GZip,
filter.LogRequest,
}Your configuration should look like this:
// This function will be called in main.go for GET requests
func GET(ctx context.Context, output http.ResponseWriter, input *http.Request) {
gcs.Read(ctx, output, input, ZippingProxy)
}When the webpage is reloaded, the content is the original, unchanged content, but
the size of the download has changed. As you can see in the logs screenshots, the
size of index.html has gone from 1113 bytes to only 531 bytes:
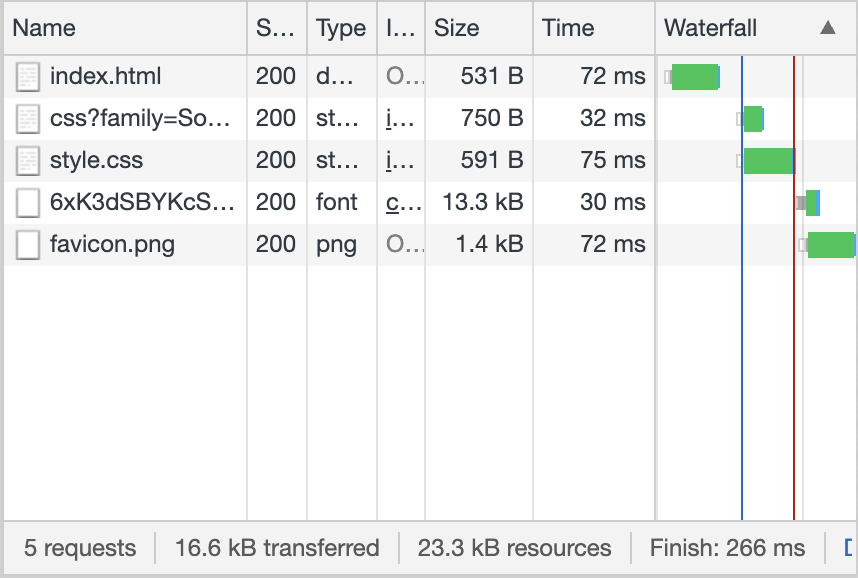
The file style.css is also compressed, from 1185 bytes to 591 bytes. Overall,
transfer decreased from 18.0 kB to 16.6 kB. For these files, the absolute difference
is small, because the files are small, but ~50% compression is not bad.
More important, this illustrates that by adding a simple filter to
the configuration, you can add a useful feature to your Cloud Storage content serving.
The filter is mostly glue code, applied to ensure a streaming response:
// GZip applies gzip encoding to the media.
//
// This is an example of a streaming filter. This will use very little memory
// and add very little latency to responses.
func GZip(ctx context.Context, handle MediaFilterHandle) error {
defer handle.input.Close()
defer handle.output.Close()
// delete content-length header. It is no longer accurate.
handle.response.Header().Del("Content-Length")
// add a content-encoding
handle.response.Header().Set("Content-Encoding", "gzip")
// zip the content
gz, err := gzip.NewWriterLevel(handle.output, 6)
if err != nil {
return FilterError(handle, http.StatusInternalServerError, "zip filter: %v", err)
}
defer gz.Close()
io.Copy(gz, handle.input)
return nil
}Though it has to do some header modification, this filter is even simpler than
the ToLower filter when it comes to handling the bytes. It simply creates a
gzip.Writer that targets the output, and then uses the io.Copy function to
write the input to that. This is just glue code.
Suppose that you want to be able to translate your webpage on demand. Perhaps
you have multiple domain names for the page, and you would like to check the request URI to determine
which one the caller used and direct them to an appropriate translation (French
for .fr, Chinese for .cn, Spanish for .mx, and so on).
Here is are some options for approaches that you could take to do this:
-
Automated translation, with a copy saved of each language:
You would have many copies to store, and you would need to run a batch update job for any changes to the website. You would not benefit from any changes to the translation machine learning model unless you ran a batch re-translation.
-
Client-side code to translate:
This is good, but you would need to have JavaScript code in your site, and hope that clients run it properly. This would also add a delay for the time that it would take between users downloading the English source, making a Translate API call on the client side, and then finally rendering the translated content.
-
Dynamic server-side translation:
This way, you only store one copy of the website (your source English copy), but clients only ever see static content, no JavaScript. When your page is updated, the translations change. As the translation machine learning models improve, you automatically get the improvements. This could be slow and expensive if you make a translation each time, but you can add some caching or CDN, so that the translation is only made on cache fills.
This dynamic server-side approach is the one that is described in this section.
Change the config.go contents to the following:
// This function will be called in main.go for GET requests
func GET(ctx context.Context, output http.ResponseWriter, input *http.Request) {
gcs.Read(ctx, output, input, DynamicTranslationFromEnToEs)
}DynamicTranslationFromEnToEs is a pipeline included in the sample configuration:
// EXAMPLE: Translate HTML files from English to Spanish dynamically.
var DynamicTranslationFromEnToEs = filter.Pipeline{
htmlEnglishToSpanish,
filter.LogRequest,
}
// htmlEnglishToSpanish applies the EnglishToSpanish filter, but only if the
// isHTML test is true.
func htmlEnglishToSpanish(c context.Context, mfh filter.MediaFilterHandle) error {
return filter.FilterIf(c, mfh, isHTML, englishToSpanish)
}
// englishToSpanish is MediaFilter that translates media from English to Spanish,
// using the MIME type of the source in the call to Translate API. This uses
// a translate API best for content under 30k code points.
func englishToSpanish(c context.Context, mfh filter.MediaFilterHandle) error {
return filter.Translate(c, mfh, language.English, language.Spanish)
}
// isHTML tests whether a file ends with "html".
func isHTML(r http.Request) bool {
url := r.URL.String()
return strings.HasSuffix(common.NormalizeURL(url), "html")
}The Translate filter requires arguments for source and target language, so englishToSpanish applies those
arguments as English and Spanish within the context of a private function that conforms to the MediaFilter type.
htmlEnglishToSpanish is similarly emulating partial application with the
FilterIf filter, here applying a test that examines the request (isHTML)
and a filter to run if that test is true, englishToSpanish. If the test is
false, FilterIf runs a no-op filter instead.
You can compose filters to make pipelines that suit your needs, even writing little bits of code to customize behaviors.
After deploying with this new configuration, here is the result when loading the webpage:

Just like that, the webpage is in Spanish. This filter uses the Cloud Translation basic API, but there are lots of ways to use Cloud Translation with varying degrees of sophistication.
There is one small disadvantage to this solution, which is the 128 ms that it takes to receive index.html:
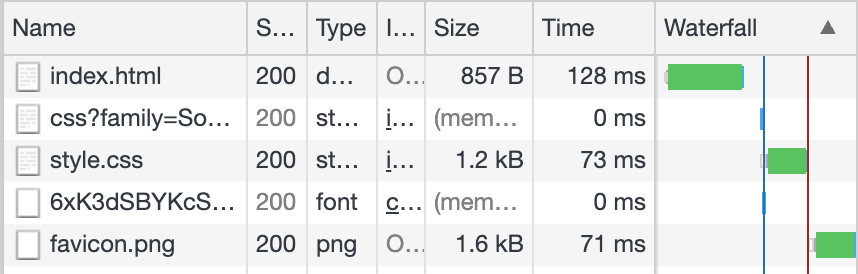
This latency makes sense, because there are a couple of factors that add time for this translation filter:
- It's not streaming. It could probably be optimized to use less RAM, but because it needs to make a remote API call for translation with the complete document included, it just loads the whole page into a byte array before sending. It then waits for a response, and streams the response back as it reads it.
- It uses a whole other remote API. This system is not just reading from Cloud Storage; it's taking the content to a translation model and getting new text back. This involves time-intensive network trips, computation time, and overhead. No matter what you do with input and output streams, there's nothing that you can really do about this.
An easy way to solve this is with caching. A CDN would work particularly well here; re-translation and the ~120ms latency penalty would only be incurred when the CDN has to fill the cache. Most, if not all, requests would be very fast using cached data.
In fact, you could easily achieve this using a Cloud External HTTP(S) Load Balancer with Cloud Run, which is in turn used as an origin for Cloud CDN.
The gcs-proxy-cloud-run repository contains even more filters, and demonstrations of capability. This is
really a "Hello, World!" for what you can do with a combination of Cloud Run, streaming responses, and Cloud Storage. For example, check out
config/pipelines.go for a pipeline that blocks sending of any data that matches a certain regular expression pattern:
// BlockSSNs will block content that matches SSN regex.
func blockSSNs(c context.Context, mfh filter.MediaFilterHandle) error {
regexes := []*regexp.Regexp{
// TODO: A better regex, but without lookarounds
regexp.MustCompile("\\b([0-9]{3}-[0-9]{2}-[0-9]{4})\\b"),
}
return filter.BlockRegex(c, mfh, regexes)
}This, too, is implemented as a streaming filter. Go to the gcs-proxy-cloud-run repository
to explore this and other filters.
You can use the ideas from this document to build all sorts of combinations and use cases for a serverless proxy for object storage.