The Prompt: Takeaways from hundreds of conversations about generative AI — part 2

Kevin Tsai
Head of Generative AI Solutions Architecture, Google Cloud
Donna Schut
Head of Technical Solutions, Applied AI Engineering
Business leaders are buzzing about generative AI. To help you keep up with this fast-moving, transformative topic, each week in “The Prompt,” we’ll bring you observations from our work with customers and partners, as well as the newest AI happenings at Google. In this edition, we continue our look at themes from hundreds of customer conversations, this time focusing on technical details.
Last week, we summarized hundreds of our conversations with customers about generative AI, why it represents a new era, trending use cases, democratization of the technology, and the role of responsible AI. In this follow-up, we share additional technical learnings from these conversations, addressing new development approaches, scalability and cost optimization, and the evolution of MLOps.
New AI development approaches
The large models that power generative AI are typically prepared in multiple stages that give them the ability to perform a variety of tasks without additional training. At a high level, the process starts with pre-training a model on a large, generic dataset. This step is often followed by instruction tuning on a mixture of labeled task datasets, and possibly domain-specific data sets for creating domain-specific foundation models.
To be used for a specific task, a model is adapted with task-specific examples and ranges from prompt engineering (including zero-shot, one-shot, and few-shot approaches) to tune the model on a larger labeled dataset. As a result, models can perform well on many downstream tasks, such as summarization, classification, and generation. A simplified depiction of this process is below.
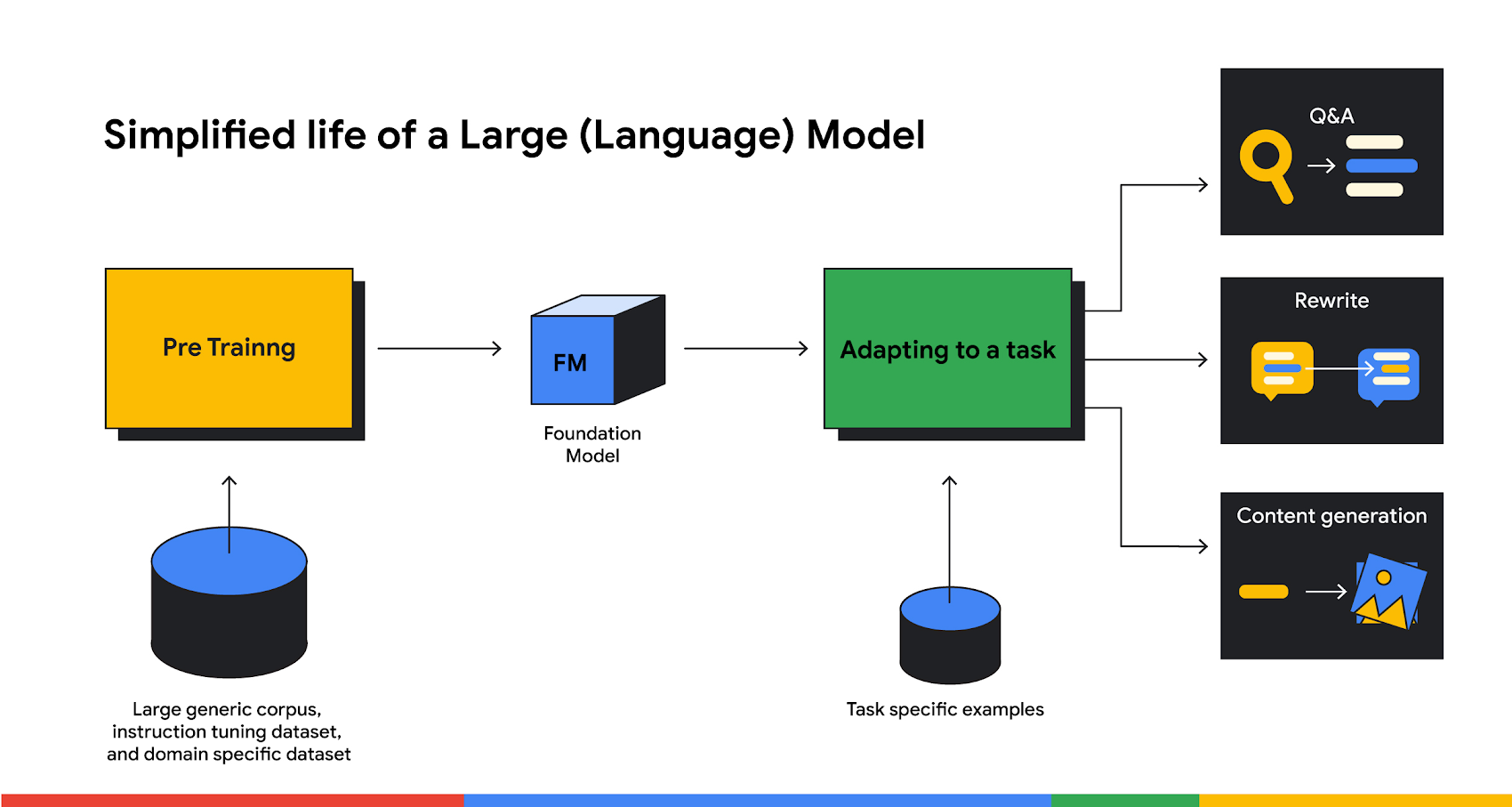
For some use cases, such as drafting sales emails or marketing content, organizations don't need to do the typical tasks of data preparation and cleansing before they start experimentation—they may be able to expect decent results just by inputting a prompt to a task-adapted model without the pre-training and adaptation, possibly with a few examples. For other cases, the process may be more complex, such as chaining together prompts. Depending on the use case, to operationalize large language models (LLMs) and other foundation models, organizations may not need the complex continuous training and data engineering pipelines that are typical of traditional machine learning (ML) practices.
Although LLMs possess a tremendous amount of knowledge from their training data, they have a limited context window, no memory, and no access to information that's external to their trained parameters. This external information can include search, database data, or knowledge from other corpora that the LLM was not not trained on.
To increase the value of LLMs, organizations should view them as one component of an intelligent application. Creating this type of application involves the following new development approaches.
Augmenting LLMs with information retrieval
A common misconception is that organizations can build an information retrieval system by fine-tuning knowledge into LLMs as a method of grounding the model in facts, and that these fine-tuned LLMs can be used as the source of truth. Fine-tuned models can still hallucinate, or produce non-factual outputs. And hallucinations aside, knowledge is only as recent as the last fine-tuning, and frequent fine-tuning can be cost-prohibitive.
Instead, a pattern that's gaining popularity involves conditioning LLMs to reason based on non-parametric information, or information external to the model itself. Embeddings, which are vector representations of unstructured data such as text or images, are used to retrieve information from these external sources, such as corporate data. This way, results are always grounded in the search corpus, and updates to the search corpus can show up in search results in near real time. Implementing downstream tasks such as multi-document summarization and Q&As is then relatively straightforward.
Reasoning and action
The complexity of an LLM’s desired behavior also affects the complexity of the prompts. Straightforward, fact-based questions can translate into simple prompts, such as “What is the pressure ratio of the J79 engine?” The LLM will probably get the answer right, but hallucinations are still possible, especially if the model has not been grounded via augmentation from information retrieval techniques.
Questions that are more complex might require one-shot or few-shot learning prompts, in which a few examples are inputted in the prompt so the model can learn in the context of the task. Complex tasks may also require chain-of-thought prompting, which helps the model break down a task into smaller steps.
Even more complex questions, especially those that require explicit external steps, such as accessing a database or making an API call, need to be broken down into smaller tasks, each with reasoning and action sequences that the LLM can handle. Langchain, a popular framework for building LLM-driven applications, has two advanced capabilities: agents for planning and execution, and tools to interact with the outside world. These capabilities enable the development of rich, LLM-powered applications.
Building on top of vendor services
The large generative AI opportunity has created a market for vendors to offer LLMs and other foundation models, as well as AI-driven products and services. These offerings pose a build-versus-buy decision for organizations.
A platform is important in this fast-evolving market. New use cases and requirements drive innovation quickly in open-source, build-your-own services—more quickly than a vendor can build product features. An extensible platform allows quick time-to-market for a set of base functionalities while also letting organizations build custom capabilities on top.
For example, Enterprise Search on Generative AI App Builder is an LLM-powered search service with built-in semantic search and summarization capabilities. As a platform, it allows functional extensions with frameworks such as Langchain, augmenting Enterprise Search with complex Q&A and summarization beyond out-of the box functionality, and with rich agent capabilities.
Scalability and cost optimization
Model sizes in generative AI are typically very large, so organizations should expect the operating cost of these models to be higher than those of smaller models used in traditional ML. LLMs and other large models rely heavily on matrix operations, for which hardware accelerators are particularly well-suited. Therefore, organizations should consider using GPUs and TPUs for cost effectiveness and performance.
Applications that leverage large models commonly interface with humans—for example, applications like information retrieval and chatbots. These use cases tend to be latency-sensitive. To ensure that these applications meet service level objectives (SLOs) for latency, organizations typically need to provision extra compute resources to account for the transient nature of requests. If an application supports users globally, an organization may need to deploy models in multiple locations to meet latency expectations. These requirements for extra resources can multiply the already-expensive cost of running inference on large models.
With this cost in mind, leaders should think about cost-reduction opportunities, especially for use cases at scale. For example, an organization should consider whether it needs to use generative AI to respond to each user query for something like a customized ad. It might instead pre-generate 20, 30, or more different ads using an LLM for design, then treat serving these ads as a more inexpensive recommendation-system problem at runtime.
If it’s not clear beforehand what data an application needs to pre-generate, organizations can also explore using generative AI online for partial queries, then reusing generated content. This approach avoids the cost of running LLMs for every single query. And if an LLM is required for each use request, organizations should consider whether they can use a smaller model, or whether they can reduce runtime costs via distillation, where knowledge from a larger model can be learned by a smaller model. Much research is being done (e.g., with Flan and Chinchilla) to increase performance while reducing model parameters and therefore runtime costs. As indicated earlier, because generative AI can result in much higher runtime costs than traditional ML, organizations should perform a cost/benefit analysis of one approach over the other.
'Don’t train the model if you don’t have to' is a good rule in generative AI cost-optimization.
“Don’t train the model if you don’t have to” is a good rule in generative AI cost-optimization. If model training is required, organizations should train as infrequently as possible, and when they do train, they should move as few parameters as possible.
Application architecture can significantly impact whether a model needs training. Take the earlier information-retrieval use case. By relying on fine-tuning to instill knowledge, an organization risks results that include hallucinations, and the LLM’s knowledge freshness will be limited by the frequency of fine-tuning. The more current the knowledge needs to be, the more money the organization will need to spend on fine-tuning. Contrast that to LLM-augmented information retrieval. If available models don't support the application’s domain, organizations may be able to use an existing LLM to generate embeddings, letting it keep the application’s outputs up-to-date without ever training or retraining a model. Even if it is necessary to adapt a model to a given domain, a strong architecture can help ensure this task remains infrequent.
Evolution of MLOps
We're in the very early moment of generative AI, with many customers still in experimental stages. Automation is an advanced characteristic of mature technology development, and thus it's not yet a common topic in our customer conversations. However, we expect generative AI to take a trajectory similar to traditional ML, with emerging ML efforts maturing into ML engineering.
For example, we currently see a lot of ad hoc prompt engineering and rudimentary or non-existent prompt-evaluation and prompt-management processes. We see this same experimental approach applied to other methods of model adaptation, like model tuning. This is similar to the early stages of traditional ML workflow implementations, before the introduction of frameworks such as TFX and Kubeflow.
At the same time, we're already seeing established MLOps practices evolve for generative AI. Organizations are recognizing they need additional guardrails on top of traditional model monitoring, such as safety filters, safety scores, recitation checks, data-loss prevention, and human feedback.
Pre-training LLMs is complex and computationally expensive, and therefore is within the capabilities of very few organizations. Organizations that need to adapt foundation models to their tasks will likely use prompt engineering or optimized tuning techniques such as Parameter Efficient Fine Tuning (PEFT) or, to incorporate human feedback to deeply customize and improve model performance, Reinforcement Learning from Human Feedback (RLHF). Distillation will likely become an important aspect of preparing models for efficient deployment and serving. As these trends continue to advance and other trends emerge, organizations will need to evolve their MLOps processes and tooling to better accommodate new techniques.
Where do you go next with generative AI?
Although traditional change-management and solution strategies still apply, we encourage leaders to consider the following questions:
For your use case, which approach delivers the best ROI: traditional ML, generative AI, or simple heuristics?
For your use case, are you planning to build your own models, adapt foundational models, or leverage out-of-the-box functionality?
Does your team have the right skills to build and use generative AI solutions?
Do you need to use generative AI to respond to every user query, or can you use generative AI online for partial queries and then reuse generated content?
Can you eliminate or reduce the need for training and fine-tuning by using an alternative architecture?