Securing the AI Pipeline
Mandiant
Written by: Dan Browne, Muhammad Muneer
Artificial intelligence (AI) is a hot topic these days, and for good reason. AI is a powerful tool. In fact, Mandiant analysts and responders are already using Bard in their workflows to identify threats faster, eliminate toil, and better scale talent and expertise. Organizations are keen to understand how best to integrate it into their own existing business processes, technology stacks, and delivery pipelines, and ultimately drive business value.
In this blog post we will look briefly at the current state of AI, and then explore perhaps the most important question of them all: How do we secure it?
SAIF
Google recently published the Secure AI Framework (SAIF), a conceptual framework for secure AI systems. SAIF is inspired by security best practices incorporating an understanding of security mega-trends and risks specific to AI systems. SAIF consists of the following six core elements:
- Expand strong security foundations to the AI ecosystem
- Extend detection and response to bring AI into an organization’s threat universe
- Automate defenses to keep pace with existing and new threats
- Harmonize platform level controls to ensure consistent security across the organization
- Adapt controls to adjust mitigations and create faster feedback loops for AI deployment
- Contextualize AI system risks in surrounding business processes
Our approach to securing the AI pipeline is built on these SAIF principles. As you read through this blog post, we will reference where our approach aligns with the six core elements. We encourage you to read through the quick guide to implementing SAIF to learn more about adopting AI in a bold and responsible way.
Beginning With AI
AI typically refers to a type of technology called machine learning, which is composed of a knowledge model that has been trained on some information, along with some additional software code to provide questions to the model and respond with answers. The original machine learning models were used to "classify" and respond with a "label". An example of this would be to feed a photograph to the model where you would essentially be answering the question "what is in this photograph?". Early examples of this technology were used for recognizing handwriting or checks.
Another version of this early form of machine learning would be to take some input, and transform that input into something else. For example, taking an audio file with a person speaking and transcribing what the person said. In other words, speech to text. The more recent versions of this technology are called "generative AI". When a human types in a question or instruction (called a prompt), the model reads it and produces an output.
The two most common types of generative AI are image generation (generating photographs based on a description) and chatbot type dialog response. In this case you would type a prompt and the chatbot would transform your prompt into some text such as a story. Most users typically access these generative AI systems through a web interface or mobile app, which provide access to a cloud type service. It is possible, however, to host, build, or train your own AI models. For the purposes of this blog post, we will focus on hosting your own model when discussing "securing the AI pipeline".
How Do We Secure the AI Pipeline?
Relevant SAIF core elements:
1. Expand strong security foundations to the AI ecosystem
2. Extend detection and response to bring AI into an organization’s threat universe
When asking the question "how do we secure the AI pipeline?", we first need to ask a couple other questions:
- What does the AI pipeline look like?
- What are the most likely attacks we would see targeting the AI pipeline?
To address the first question we designed a conceptual model of what we consider to be a typical AI pipeline. This pipeline consists of six components and is detailed in the AI Pipeline section that follows. Next, to address the second question, we performed a threat modeling assessment against the AI pipeline. Having done that, we came up with a set of 10 most likely attacks or vulnerabilities in context of the threat model that could be used to design controls for the pipeline. We have chosen to call this list of attacks and vulnerabilities the GAIA Top 10, where GAIA stands for “Good AI Assessment”. There are other types of lists that focus on various aspects of security such as the OWASP top 10, which looks at web application attack vectors. OWASP also has a list for securing LLMs specifically. The MITRE ATLAS is another good resource for attack paths against the AI/ML pipeline. GAIA is built around what we consider to be the most likely attack paths for the generalized AI pipeline, and has been developed for the purposes of this blog post. It is not an exhaustive list of possible attack paths.
Here is a simplified diagram of the AI pipeline we used:
AI Pipeline
As you can see there are six components:
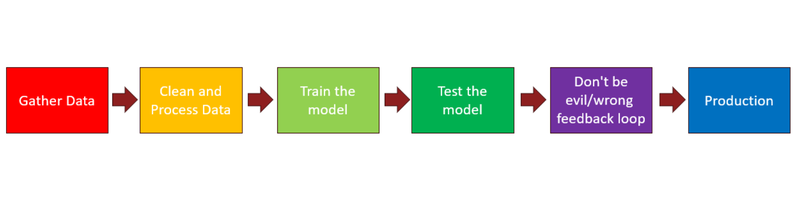
Data Gathering
In this stage of the pipeline, typically data scientists have already figured out a predictive model they want to build, and what data they will need to train the model and test it. For example, in the case of a dog breeds model, the data scientists might want to gather together lots of examples of pictures of different breeds of dogs, taken from different angles, and in different lighting conditions. Additionally, they might want to gather some counterexamples to test the model on; say, pictures of cats, pictures of the sky, pictures of trains, and pictures of people. In other words, pictures of anything but dogs.
Cleaning and Processing the Data
At this stage the data scientists would be looking at the training data to make sure it is clean and useful. In the case of the dog-breed-prediction model, they might want to make sure there are no duplicate photos, and no pictures of cartoon dogs or toy dogs. Then they would build the appropriate software scripts to feed the pictures into the blank model in batches, with corresponding labels saying which breed the particular picture is. Note: there is a way to do this without labeling the data, but we won’t talk about this here in great detail.
Training the Model
At this stage the blank model is ready to be trained. Here, the data scientists would start the process that would run the data-loading scripts into the model over and over until the model learns and its forecasts have minimal loss. For example, if the model is being trained to identify different types of dog breeds, then the model would be trained on the corresponding names of dog breeds.
Testing the Model
At this stage the model is trained and ready to be tested. The data scientists build test scripts, which load in examples of test data that the model has never seen before. If the model has worked correctly, it will produce outputs that label the test data (in this case dog pictures or not-dog-pictures) as either “dog-breed” or “not-dog”. In standard software testing, this stage would often be called functional testing.
Testing Whether the Feedback Loop of the Model Gives Unacceptable Results (“Don’t be Evil/Wrong”)
At this stage we want to identify scenarios that would be considered to be wrong and/or bad/evil. In the case of a dog-breed classifier model, it is difficult to come up with examples of how this model could produce bad/evil outputs, but an inadequately or incorrectly trained dog-breed-classifier model could provide inaccurate responses. For example, predicting that a dog picture isn’t a dog would be wrong. Likewise saying that a panda is a type of dog would be wrong.
For bad/evil scenarios, we could think of an example where a self-driving car model is being trained to recognize street signs. Identifying a stop sign as a speed limit sign could be considered bad or evil depending on the reasons why the system is misidentifying the stop sign.
In standard software testing, this stage would be called “abuse case testing” or “security testing”.
Final Production
At this stage, the pipeline is complete. The model is fully trained and fully tested, and specific test cases have been identified that test the model functions correctly, and that the identified abuse cases do not affect the model. The model is now ready to be delivered to the users.
Wait a Minute: There’s Something Familiar About This…
The AI pipeline diagram and aforementioned descriptions are for a standardized conceptual AI pipeline where you would train your model from scratch. In some cases an organization may be using either a pre-trained model from some third party with no training needed or else they may be taking a pre-trained model and performing some re-training of the model (which in machine learning is called “fine-tuning”).
To some of you all this is likely to seem really familiar. In fact, it looks just like another pipeline we’ve been using for over a decade: the Business Intelligence (BI) pipeline.
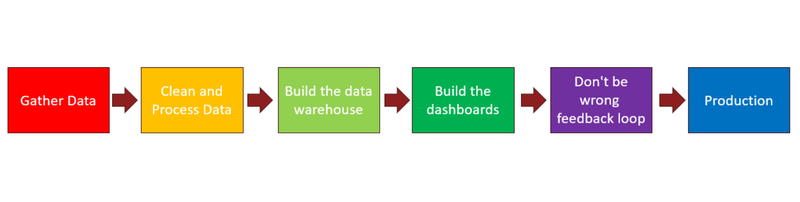
Why are we showing you the BI pipeline when we’re talking about AI? That’s because the BI Pipeline is built on known tech.
And so is the AI pipeline. For the most part, the tech is super familiar. That’s a point we strongly want to drive home. While AI itself has some interesting and brand new cutting-edge features, the technology stack on which it is built and in which it lives, is using familiar technology. Threat models have been developed leveraging known attack vectors. Detective and preventive controls have also been designed for the known attack vectors. You will see later on in the blog post that this is a recurring theme.
Now that we have defined the AI pipeline and have developed an approach to map attack paths against the pipeline, let's take a look at the risk approach in the context of AI.
Risk Approach
Relevant SAIF core element:
6. Contextualize AI system risks in surrounding business processes
Adopt AI
Should we adopt AI? That’s the big question being asked by all organizations today. Like any other business problem, the decision to adopt or develop AI capabilities depends on a cost-benefit analysis that is informed by risk. Ask yourself:
- Will our employees or customers be at risk?
- Will our network be at risk?
- Will our data be at risk?
When determining security controls for the AI pipeline, the organization needs to have clarity on the type of AI they will be using at the organization:
- Do we develop the model and corresponding technology in-house?
- Do we use a third party developed model and host in-house or in the cloud?
- Do we use an as-a-service API type solution?
Each of these questions may have different threat models applicable to them, and as a result, it is possible that they will have different security controls—prevention and detection—that would be relevant. Knowing the path the organization is going to take for AI adoption, and the type of models that will be used, will help an organization assess risk and develop controls.
In addition to deployment options, there are some general risk type questions that management should be considering:
- What is the organization’s stance on using AI?
- This question will help the organization determine its overall approach to AI, including developing its own capabilities versus relying on third-party providers.
- Do we need to use AI?
- AI can be a complex and expensive technology. The organization should carefully consider whether AI is the best solution for its needs.
- How will AI impact the workforce?
- The organization should consider how AI will impact its workforce, and develop plans to mitigate any negative impacts.
- Are we already using AI in-house?
- Many organizations are already using AI, even if they don’t realize it. The organization should identify all of the ways in which it is using AI, and assess the risks associated with each use.
- How do we know we are using AI in-house?
- The organization should develop a process for identifying AI in their environment and tracking its use.
- Does the organization have supply-side AI exposure?
- The organization should assess its exposure to supply-side AI risks and develop plans to mitigate them. This is especially important for organizations that are heavily reliant on AI for data handling.
- Have we considered KPIs and ROI?
- The organization should set clear KPIs (key performance indicators) and ROI (return on investment) goals for its AI initiatives. This will help the organization measure the success of its AI efforts.
- Have the users/implementers considered security?
- AI systems can be vulnerable to security risks. The organization should ensure that its AI systems are properly secured.
- Have we as an organization considered the implications of using AI (without the hype)?
- AI is a powerful technology that has the potential to transform many industries. It also brings with it some security considerations.
- Has our security team reached out to experts for advice?
- The organization's security team should partner with leading security experts for advice on how to mitigate the security risks associated with AI.
- Are there any legal considerations with the data that may be used.
- Privacy-sensitive data and other controlled data-types may have regulatory and legal requirements around how it is stored and processed, even in AI.
Now that we’ve reviewed some risks to consider, let's take a look at how to threat model for AI.
Threat Model for AI/ML Pipeline
Relevant SAIF core element:
5. Adapt controls to adjust mitigations and create faster feedback loops for AI deployment
Overview of Threat Modeling
Threat modeling is a systematic approach to identifying, analyzing, and mitigating potential security threats to a digital asset. Threat modeling is essential for securing AI pipelines. The logical next question is how to threat model for AI. The process is similar to what you would do for any other digital asset such as a web application or a critical system. To break the process down into a few steps:
- Identify the components of the AI pipeline
- Identify threats to the components
- Develop plausible attack scenarios and attack paths that threat actors may leverage to target the components
- Identify and map existing security controls
- Determine gaps in existing security controls by identifying areas where there are no controls or where the controls are inadequate
- Plan and execute remediations by identifying and implementing controls to close the gaps.
Threat modeling can seem straightforward when broken down into six steps. However, as is the case with most technology, it is not quite as straightforward in practice. There are a number of challenges that can make threat modeling difficult, including:
- Lack of expertise
- Time constraints
- Cultural challenges (reactive mindset versus proactive mindset)
- Lack of cyber threat intelligence
When threat modeling for AI, it is important to consider the following:
- The type of AI being used. There are different types of AI, each with its own unique risks. For example, classification models can be vulnerable to data poisoning attacks, while natural language processing models can be vulnerable to adversarial examples.
- The data used to train and deploy AI models. If the data is not properly secured, it could be used to train malicious models.
- The environment in which AI models are deployed. AI models can be deployed in a variety of environments, and each environment will have its own unique risks. For example, models deployed in the cloud are vulnerable to cloud-based attacks, while models deployed on-premises are vulnerable to on-premises attacks.
- The software used to develop and serve the AI models. Like other software, supply-chain risks are still part of the threat model. For example, using obscure third-party libraries as part of your clean and process data process could introduce risks.
To mitigate these risks, organizations should consider strategies that address the following:
- Data security. The data used to train and deploy the models should be properly secured.
- Model security. AI models should be properly secured using measures such as input validation, output sanitization, and model monitoring.
- Environment security. The environment in which AI models are deployed should be properly secured using measures such as software security and verification, network segmentation and access controls.
One of the primary challenges we see organizations struggle with is coming up with plausible scenarios and attack paths when threat modeling. There needs to be an understanding for how an attack may be executed in order to develop an effective threat model. To help on this front, we have curated the GAIA Top 10.
Introduction to GAIA Top 10
The following is what we believe to be the most common list of attacks and weaknesses for AI that attackers might use against the conceptual AI pipeline and resulting GenAI Model.
- G01 – Prompt Injection
- This is where an attacker will try to inject bad data or information into the prompt in order to make your model do something you don’t want it to do, such as try to access the underlying operating system or make it output embarrassing results that could be shared on social media.
- G02 – Sensitive Data Exposure
- This is where an attacker is able to access sensitive data due to insufficient curation of training data or attacker gaining access to underlying tech stack.
- G03 – Data Integrity Failure
- This is where an attacker is able to inject adversarial data into the model or embeddings database after an attacker gains access to the underlying tech stack.
- G04 – Poor Access Control
- This is where the underlying tech stack has insufficient access control and the attacker is able to download the model or APIs have not been designed with access control in mind.
- G05 – Insufficient Prompt & Hallucination Filtering
- This is where prompt filters have not been adequately tested or red-teamed with abuse cases or common data hallucinations have not been adequately tested or red-teamed with abuse cases.
- G06 – Agent Excessive Access
- This is where a public facing agent has access to private/restricted internal APIs or a public facing agent has access to private/restricted models or an agent has access to financial systems.
- G07 – Supply Chain Attacks
- Similar to software development tech stacks, AI tech stacks rely on a variety of third-party libraries (particularly Python libraries). If using open source libraries, these libraries could have been compromised by malicious third parties. Additionally, third-party repositories of AI models could have been compromised. It is worth noting that the model itself, if built using Python, could be in the default configuration of a mixture of code and data, and could potentially run attacker code upon install.
- G08 – Denial of Service Attacks
- This is where throttling or rate limiting are not in place or load balancing is not adequate.
- G09 – Insufficient Logging
- Similarly to standard tech stacks, there are various points at which useful logging data could be gathered and sent to a centralized SIEM, which could aid defenders in identifying an ongoing attack. Logging is often an afterthought for AI pipelines.
- G10 – Insecure public facing deployment
- Examples of cases of insecure public facing deployment might be a model deployed directly on an unsecured inference server or made directly downloadable. Also, an Inference API or Web Service being vulnerable, unpatched and not up-to-date, and excessive permissions for service accounts on inference servers.
The following diagram illustrates the parts of the AI pipeline that could be vulnerable to the GAIA Top 10.
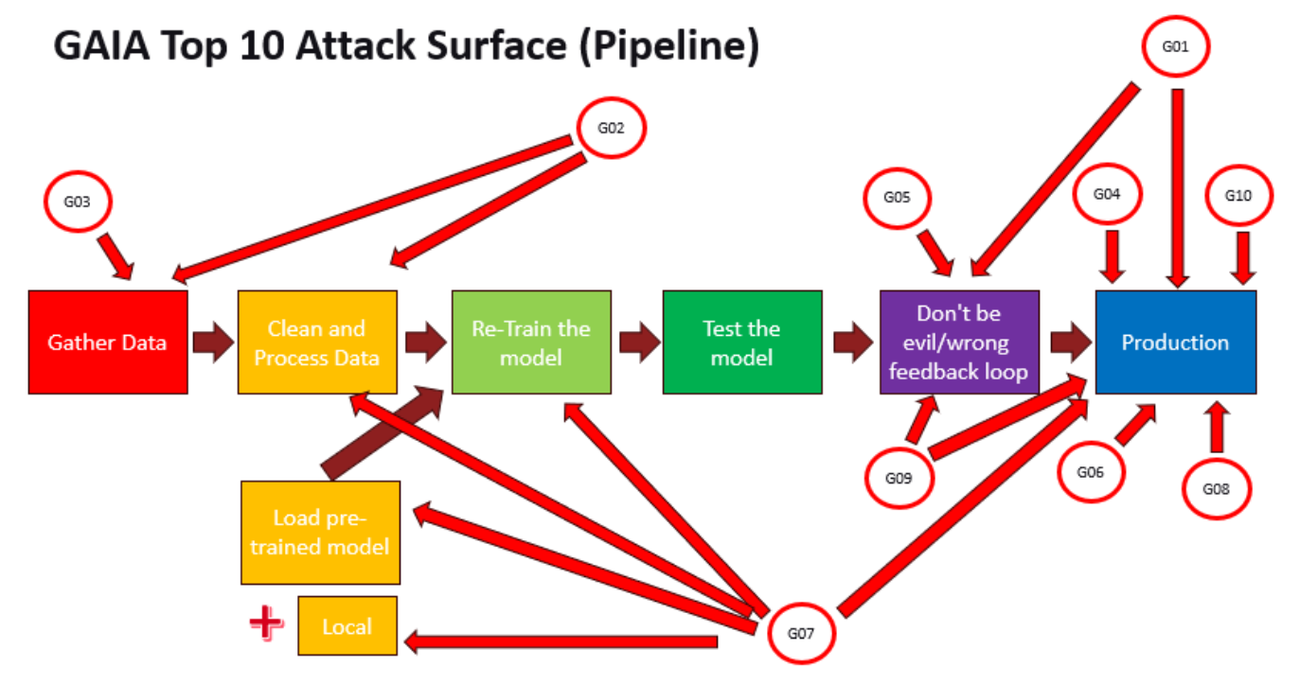
Organizations should consider their tech stack along with the GAIA Top 10 when asking the question “how do we secure this”, with the idea that the AI pipeline is built on known technology, and thus, any mitigations put in place are mostly modifications of existing security controls.
Threat Hunting for AI/ML Pipeline
Relevant core SAIF elements:
1. Expand strong security foundations to the AI ecosystem
2. Extend detection and response to bring AI into an organization’s threat universe
3. Automate defenses to keep pace with existing and new threats
Threat hunting is a methodical, use case driven, proactive identification of cyber threats. An organization can use threat hunting to shift from a reactive security posture to a proactive one. In a reactive posture, the security team waits for alerts to be generated by the security stack before responding to security events and incidents. In a proactive posture, the security team proactively hunts for evidence of compromise, even if no alerts have been generated.
Once a threat model has been developed for the AI pipeline, identifying attack vectors and controls, an organization can perform threat hunts to look for evidence of compromise in the AI pipeline.
Threat hunting can be broken down into four steps:
- Assess: In this step a threat hunter develops hypotheses and scopes hunt missions. A hypothesis is a statement that describes what you believe the attacker is doing or trying to do. You assume compromise and try to find evidence to prove the hypothesis.
- Acquire: Once you have defined your hypothesis, you need to acquire the data to support it. It is important to understand which tools in the AI pipeline can provide visibility for a threat hunter. This includes understanding the types of data that each tool collects, and the format of the data. Once you understand the data that is available, you can start to look for anomalies or patterns that could indicate a threat. The logs that are used for threat hunting can also be used for use case and alerting purposes. This can help to automate the process of threat hunting by creating alerts that trigger when specific events or patterns are detected.
- Analyze: Once you have gathered the data, you need to analyze it to look for evidence that supports your hypothesis. This is where you will try and find evidence of the attack paths like those listed in the GAIA top 10. If you find any evidence that supports your hypothesis, you need to investigate and validate the finding.
- Action: If your investigation confirms that an attack has occurred, you need to take action to mitigate the damage. It is key to have a response plan in place. You should also have a communication plan in place to convey findings to key stakeholders.
Some reasons to perform threat hunts for the AI pipeline include:
- Detection of threats that are not detected by traditional security tools.
- Reduce attacker dwell time.
- Improve the overall security of the AI pipeline.
To increase threat hunting capabilities for the AI pipeline consider the following steps:
- Identify the critical assets in the AI pipeline.
- Understand the threat landscape.
- Develop threat models.
- Implement security controls.
- Monitor the AI pipeline for threats and anomalies.
- Respond to threats quickly and effectively.
- Use rule-based detection to identify specific patterns of anomalous activities (ML can also be leveraged for this purpose)
- Use a variety of data sources from the AI pipeline to identify anomalies.
Conclusion
The technology stack on which AI is built is well understood. As a result, the attack vectors are also similar to those we already understand. It’s just about looking at it through a new lens.
Being proactive is key. Now is the time to take steps to prevent potential attacks from happening in the first place. When securing AI systems, it is important to think like an attacker. Consider known weaknesses and identify the ways that an attacker could exploit a system. Work with other teams in the organization—including data science, engineering, and security—to develop a comprehensive security plan.
Contact Mandiant to learn how we can help with security for your AI endeavors. For more on methods to consider when securing the AI pipeline, we recommend reading Google’s SAIF approach.
