Recognizing and Avoiding Disassembled Junk
Mandiant
Written by: Nick Harbour
There is a common annoyance that seems to plague every reverse engineer and incident responder at some point in their career: wasting time or energy looking at junk code. Junk code is a sequence of bytes that you have disassembled that are not actual instructions executed as part of a program. In addition to wasting time, I’ve seen people get alarmed and excited by the junk code they’ve found. In these cases, it is because they found executable code in a place they weren’t expecting, which led them to believe they had found an exploit or an advanced malware specimen.
In this post, I will discuss how to recognize junk code by learning what causes it and how it differs from real code. We are going to focus on x86 disassembly, but similar issues are present in many other architectures.
The Problem
The first mistake people make in disassembling junk code is assuming that it is actual code because it disassembled to valid instructions. The x86 instruction set is densely packed, and many are encoded with a single byte. Disassembling almost any data will yield potentially valid looking x86 code at first glance.
For example, I generated a 16kb file of random data and disassembled it. This produced 6,455 valid 32-bit x86 instructions and only 239 bytes of unrecognized data. This means data that the disassembler was not able to parse into valid instructions. Over 98 percent of the random data could be disassembled into valid instructions. To explain what I mean by unrecognized data, let’s look at the disassembly for the first portion of this random data where we will encounter many instructions and one byte of unrecognized data.
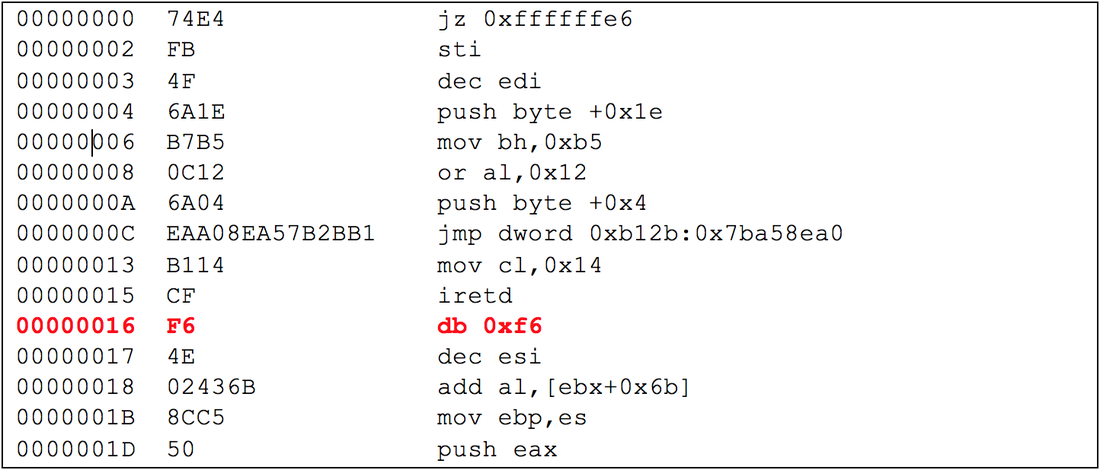
The first column of data in this fragment (and all the disassembly represented in this post) is the data offset. The second column shows the bytes that make up the instructions, and the third column shows the disassembly representation of those bytes. For all lines except the highlighted line (offset 0x16), the disassembly shows a valid instruction. Offset 0x16 shows what may look like an instruction, but the notation “db” is just assembler notation to declare a byte. The disassembler is denoting that at this location is the byte 0xF6 and it doesn’t recognize it as part of an instruction. The x86 instruction set is so densely packed that every byte value is the potential start of an instruction. In this case, 0xF6 could be a valid start of an instruction depending on the bytes that followed it, but the byte 0x4E in this case did not form a valid operand. In the 16kb of random data, the 274 unrecognized bytes were all one of only 27 different values. Of these 27 values, the only one that overlaps the range of common English language characters is the letter ‘b’ (0x62).
We will stick to 32-bit disassembly in this post due to its more widespread fluency, but the same issues do occur in 16-bit and 64-bit Intel assembly. When the random data previously presented was disassembled as 16-bit code, it produced 96 percent valid instructions, and disassembling as 64-bit yielded 95 percent valid instructions.
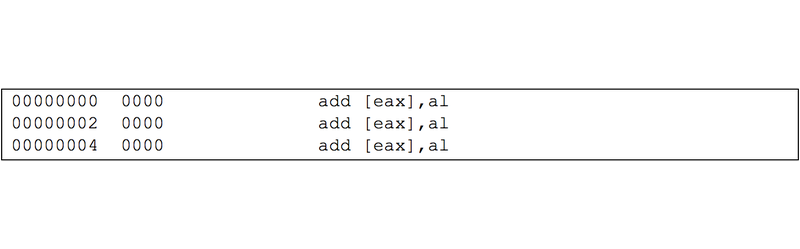
You might expect that a large area of zeros would mean an area where no code exists. Advanced disassemblers might intelligently recognize large amounts of zeros as not code and skip the disassembly, but they disassembly as valid x86 instructions. Here are a few bytes of disassembled zeros which illustrate this:
The problem is even worse for English language text. I generated a 60kb file containing random text (lorem ipsum) and disassembling it produced 23,170 instructions and no unrecognized data. So, 100 percent of the random text was valid instructions when disassembled. The following fragment shows the first three words of standard lorem ipsum disassembled (“Lorem ipsum dolor”):

Clearly, it is going to take more than just seeing if it disassembles to tell us if what we are looking at is actual code.
The Solution
Our best weapon is currently the human brain, though it should be feasible to script heuristics to better filter out junk code. There are many things that stand out to an experienced reverse engineer about the fragments of code you have seen so far in this post, and they are the key to learning to gauge whether the code you are looking at is junk or not.
Privileged Instructions
The x86 processor has four “rings” of protection. Just like Lord of the Rings, but much less fun. Two of the rings typically aren’t used at all. Kernel mode execution happens in Ring0 and user mode in Ring3. Certain instructions can only operate in Ring0. Many of these special privileged instructions also happen to be single byte opcodes and occur frequently in disassembled junk. Let’s look again at that lorem ipsum disassembly, but this time I will highlight the privileged instructions:
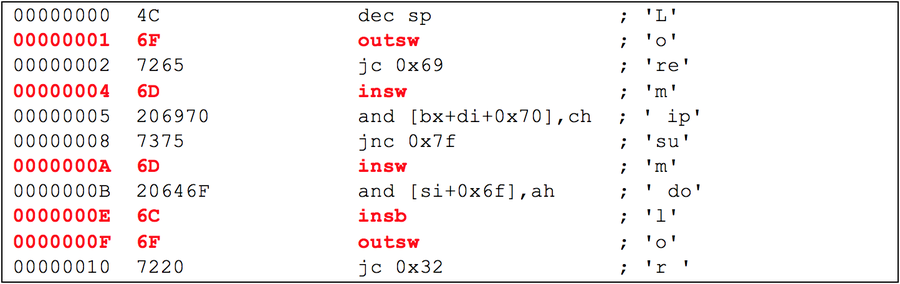
If you know that the code you’re looking at is not designed to run as an operating system bootloader, kernel, or device driver, then seeing these privileged instructions should indicate that this disassembly is not actually valid code. The highlighted instructions are both variants of the IN and OUT instructions read and write data from hardware ports. These would-be instructions must be used within a device driver and would generate an exception if executed from Ring3 user mode. Even if you were attempting to disassemble kernel code, the frequency that these instructions occur is much higher than you will find if you disassembled every file in your operating system. The following is a list of some common Ring0 instructions you will see frequently in disassembled junk:
- IN (INS, INSB, INSW, INSD)
- OUT (OUTS, OUTSB, OUTSW, OUTSD)
- IRET
- IRETD
- ARPL
- ICEBP / INT 1
- CLI
- STI
- HLT
Rare Instructions
There are many Ring3 instructions that are valid in user mode code yet are very uncommon, particularly in compiled code as opposed to handwritten assembler. We can categorize these instructions into three categories: convenience instructions, unlikely math, and far pointer instructions. Let’s examine these categories.
Convenience Instructions
- ENTER
- LEAVE
- LOOP (LOOPE/LOOPZ, LOOPNE/LOOPNZ)
- PUSHA
- POPA
The instructions ENTER and LEAVE can be used by assembly language programmers for function prologues and epilogues, but they do not provide any capability that can’t also be accomplished manually with instructions PUSH, MOV, and SUB. Modern compilers tend to avoid ENTER and LEAVE and, as a result, most programmers don’t use them either. Because together they occupy almost 1 percent of the opcode range, their appearance in junk code is very common.
The LOOP instruction, and its conditional brethren LOOPZ and LOOPNZ, offers a very intuitive and useful way to write loops in assembly language. Compilers typically choose to not use these, and instead craft their own loops out of JMP and conditional jump instructions.
The PUSHA and POPA instructions provide a mechanism to save the state of all the registers to the stack. This provides a potentially convenient macro-like instruction for assembly language programmers. It is complicated by the fact that it also stores and restores the stack pointer itself, which eliminates its potential use of allowing a lazy coder to blindly store registers at the start of a function and restore them at the end of the function. You won’t find these instructions in compiled code, but they also occupy nearly 1 percent of the available opcode range, so they appear frequently in junk disassembly.
Unlikely Math
- Floating point instructions
- F*
- WAIT/FWAIT
Floating point instructions generally start with the letter ‘F’. While some programs out there do make use of floating point math, the majority do not. The floating point instructions occupy a large portion of the opcode range, so their presence in disassembled junk is very common. This is where your knowledge of the design of the code you are attempting to reverse engineer will come in handy. If you are reverse engineering a program with 3D graphics, expect to find potentially large amounts of floating point instructions. For the work we do on the FLARE team, Malware Analysis, floating point math is extremely rare. The notable exception is that shellcode often uses some floating point instructions as a trick to get a pointer to itself.
- SAHF
- LAHF
The SAHF and LAHF instructions copy the contents of the AH register to and from the flags register EFLAGS. This is a programming behavior that does not translate down from higher level languages and, as a result, compilers generally don’t output these instructions. If these are used at all it will be rarely and in handwritten assembly. Since these are single byte instructions in the one-opcode range, they occur frequently in disassembled junk.
- ASCII Adjust Instructions
- AAA
- AAS
- AAM
- AAD
The “AA” series of instructions deal with manipulating data in binary-coded decimal form. This is an archaic encoding that you should not expect to encounter in modern computing. You will, however, encounter these instructions frequently in disassembled junk because they are single byte instructions.
- SBB
The SBB instruction is like SUB except that it adds the Carry Flag to the source operand. This could be seen in legitimate code, particularly if attempting to perform arithmetic on numbers larger than the word size of the machine (think 64-bit math in 32 bit code). Unfortunately, the SBB instruction constitutes no less than nine opcodes, which is 3.5 percent of the possible range. They are not single byte instructions, but with so many forms and so many opcodes they occur frequently in disassembled junk.
- XLAT
XLAT is a fun instruction to play with in your assembly code. There is no direct translation to a single high-level language construct and, as such, compilers do not appreciate it as much as we do on the FLARE team. Since it is a single byte instruction, you will find it more frequently than you will find programmers out there having fun with assembly language.
- CLC
- STC
- CLD
- STD
These instructions clear and set the Carry and Destination flags. They may be found in compiler generated code near stream operations (places where you see the REP prefix, usually). They are all single byte instructions, though, and their prevalence in junk disassembly is extremely inflated.
Far Pointer Instructions
- LDS
- LSS
- LES
- LFS
- LGS
The use of far pointers does not exist past the 16-bit era in the Intel architecture. The instructions to set a far pointer, though, still occupy two single-byte opcodes and three values in the two-byte opcode range. As such, you will see these instructions popping up frequently in disassembled junk.
Frequent Prefixes
Instructions in x86 can have prefixes. Prefix bytes often modify the behavior of the following instruction. A common use for prefix is altering operand size. For example, if you are executing instructions in 32-bit mode and you wish to perform a calculation using a 16-bit register or operand, you can add a prefix to the calculation instruction to inform the CPU that it is a 16-bit instruction instead of a 32-bit one. There are many such prefixes, and unfortunately many of them fall in the alphabetic range on the ASCII table. That means that when disassembling ASCII text (such as our lorem ipsum), instruction prefixes will be very common. They are found in non-junk code, but nowhere near as frequent as in junk code. If you are disassembling 32-bit code and you see a large amount of 16-bit registers being used (AX, BX, CX, DX, SP, BP, etc. instead of EAX, EBX, ECX, EDX, ESP, and EBP), you may be looking at junk code.
The disassembler will also represent other prefixes with certain notations added before the instruction mnemonic. If you see any of these keywords occurring frequently in the code, then it is likely to be junk:
- LOCK
- BOUND
- WAIT
Segment Selectors
- FS
- GS
- SS
- ES
In 16-bit mode, addressing memory is accomplished using the segment registers (CS, DS, FS, GS, SS, ES). The code of the program is typically referenced based on the CS “code segment” register and the data the program deals with is referenced from the DS “data segment” register. ES, FS, and GS are extra data segment registers and are legitimately used in 32-bit code, but that is a more advanced topic. There are segment selector prefix bytes that can be added before an instruction to force it to reference memory based on a specific segment instead of the default segment it is designed to use. Since these all occupy that precious single-byte opcode space, they will occur frequently in disassembled junk. The following instruction from my disassembled random data shows a segment selector prefix for the GS register used on an instruction that does not address memory:

Disassembled junk will also use these segment registers more frequently than normal code, and in ways that compilers do not output. Let’s examine another line from the disassembled junk:

This instruction pops the SS “stack segment” register from the stack. This is a perfectly valid instruction; however, this is disassembled 32-bit code and segment registers are generally not changed like they are in the 16-bit world. In the same disassembly, only a few lines above, is another bizarre line of code:

The 32-bit architecture supports addressing for more segment registers than there are names for segment registers. This instruction is supposedly moving some data into the 7th segment register, which my disassembler has named “segr7”.
Conclusion
In its mildest scenario, disassembled junk code can waste your time and effort. In its worst scenario, it can make you say things about the data you’re analyzing that aren’t true. In this post, we have learned to spot disassembled junk by recognizing and understanding out-of-place code. We broke the out-of-place code down into categories for the most common cases and discussed what they mean, why they occur frequently, and why they shouldn’t. By learning these indicators, you can easily spot disassembled junk and save yourself time and maintain your reputation.
