Jupiter evolving: Reflecting on Google’s data center network transformation

Amin Vahdat
VP/GM, AI & Infrastructure, Google Cloud
Data center networks form the basis for modern warehouse-scale and cloud computing. The underlying guarantee of uniform, arbitrary communication among tens of thousands of servers at 100s of Gb/s of bandwidth with sub-100us latency has transformed computing and storage. The primary benefit of this model is simple yet profound: adding an incremental server or storage device to a higher-level service delivers a proportional increase in service capacity and capability. At Google, our Jupiter data center network technology supports this kind of scale-out capability for foundational services for our users, such as Search, YouTube, Gmail, and Cloud services, such as AI and machine learning, Compute Engine, BigQuery analytics, Spanner databases, and dozens more.
We have spent the last eight years deeply integrating optical circuit switching (OCS) and wave division multiplexing (WDM) into Jupiter. While decades of conventional wisdom suggested that doing so was impractical, the combination of OCS with our Software Defined Networking (SDN) architecture has enabled new capabilities: support for incremental network builds with heterogeneous technologies; higher performance and lower latency, cost, and power consumption; real-time application priority and communication patterns; and zero-downtime upgrades. Jupiter does all this while reducing flow completion by 10%, improving throughput by 30%, using 40% less power, incurring 30% less cost, and delivering 50x less downtime than the best known alternatives. You can read more about how we did this in the paper we presented at SIGCOMM 2022 today, Jupiter Evolving: Transforming Google's Datacenter Network via Optical Circuit Switches and Software-Defined Networking.
Here is an overview of this project.
Evolving Jupiter data center networks
In 2015, we showed how our Jupiter data center networks scaled to more than 30,000 servers with uniform 40Gb/s per-server connectivity, supporting more than 1Pb/sec of aggregate bandwidth. Today, Jupiter supports more than 6Pb/sec of datacenter bandwidth. We delivered this never-before-seen level of performance and scale by leveraging three ideas:
Software Defined Networking (SDN) - a logically centralized and hierarchical control plane to program and manage the thousands of switching chips in the data center network.
Clos topology - a non-blocking multistage switching topology, built out of smaller radix switch chips, that can scale to arbitrarily large networks.
Merchant switch silicon - cost-effective, commodity general-purpose Ethernet switching components for a converged storage and data network.
By building on these three pillars, Jupiter’s architectural approach supported a sea change in distributed systems architecture and set the path for how industry as a whole builds and manages data center networks.
However, two primary challenges for hyperscale data centers remained. First, data center networks need to be deployed at the scale of an entire building — perhaps 40MW or more of infrastructure. Further, the servers and storage devices deployed into the building are always evolving, for example moving from 40Gb/s to 100Gb/s to 200Gb/s and today 400Gb/s native network interconnects. Therefore, the data center network needs to evolve dynamically to keep pace with the new elements connecting to it.
Unfortunately, as shown below, Clos topologies require a spine layer with uniform support for the fastest devices that might connect to it. Deploying a building-scale, Clos-based data center network meant pre-deploying a very large spine layer that ran at a fixed speed of the latest generation of the day. This is because Clos topologies inherently require all-to-all fanout from aggregation blocks1 to the spine; adding to the spine incrementally would require rewiring the entire data center. One way to support new devices running at faster line rates would be to replace the entire spine layer to support the newer speed, but this would be impractical given hundreds of individual racks housing the switches and tens of thousands of fiber pairs running across the building.
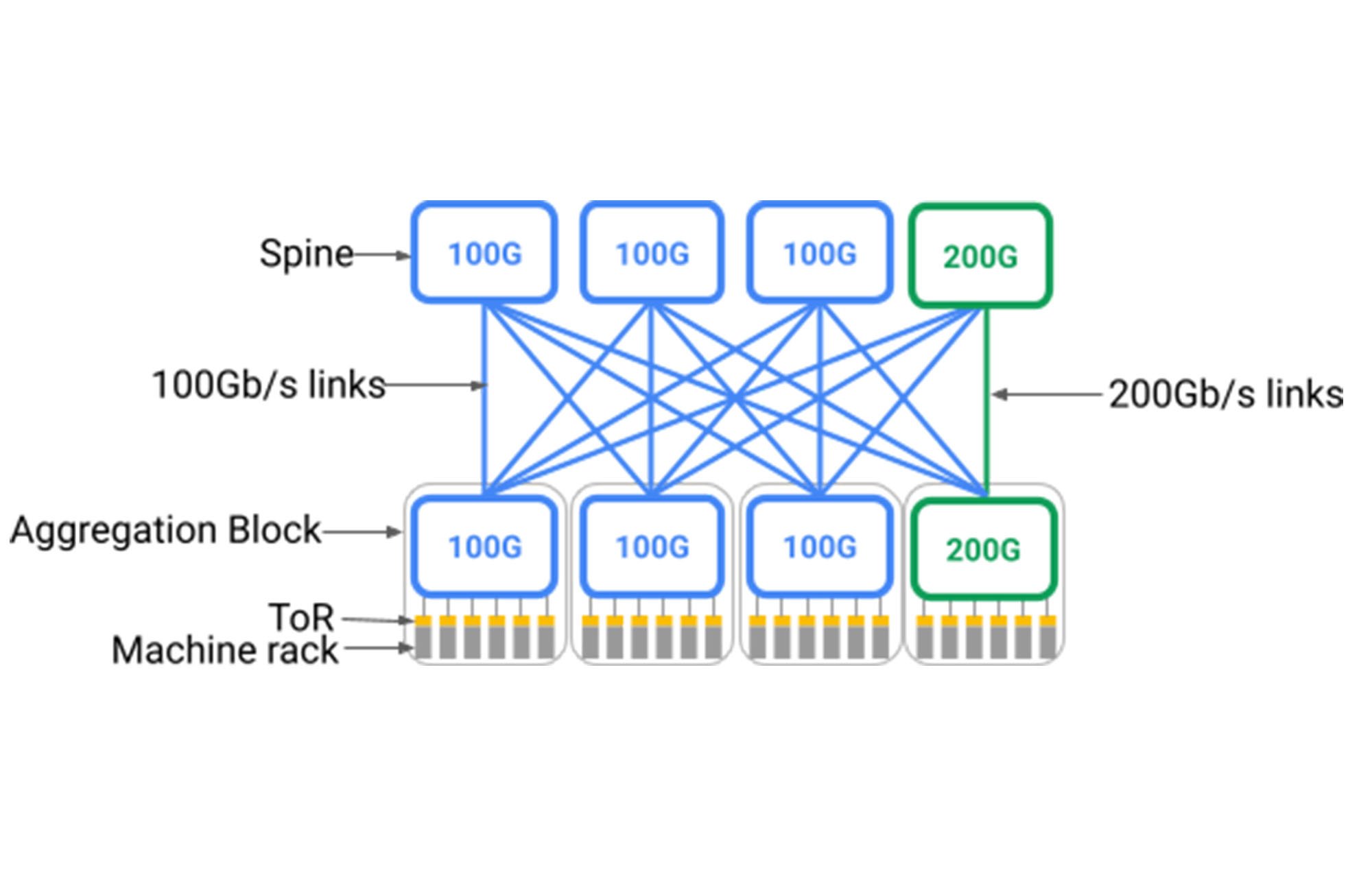
Ideally, the data center network would support heterogeneous network elements in a “pay as you grow” model, adding network elements only when needed and supporting the latest generation of technology incrementally. The network would support the same idealized scale-out model it enables for servers and storage, allowing the incremental addition of network capacity — even if of a different technology than previously deployed — to deliver a proportional capacity increase and native interoperability for the entire building of devices.
Second, while uniform building-scale bandwidth is a strength, it becomes limiting when you consider that data center networks are inherently multi-tenant and continuously subject to maintenance and localized failures. A single data center network hosts hundreds of individual services with varying levels of priority and sensitivity to bandwidth and latency variation. For example, serving web search results in real-time might require real-time latency guarantees and bandwidth allocation, while a multi-hour batch analytics job may have more flexible bandwidth requirements for short periods of time. Given this, the data center network should allocate bandwidth and pathing for services based on real-time communication patterns and application-aware optimization of the network. Ideally, if 10% of network capacity needs to be temporarily taken down for an upgrade, then that 10% should not be uniformly distributed across all tenants, but apportioned based on individual application requirements and priority.
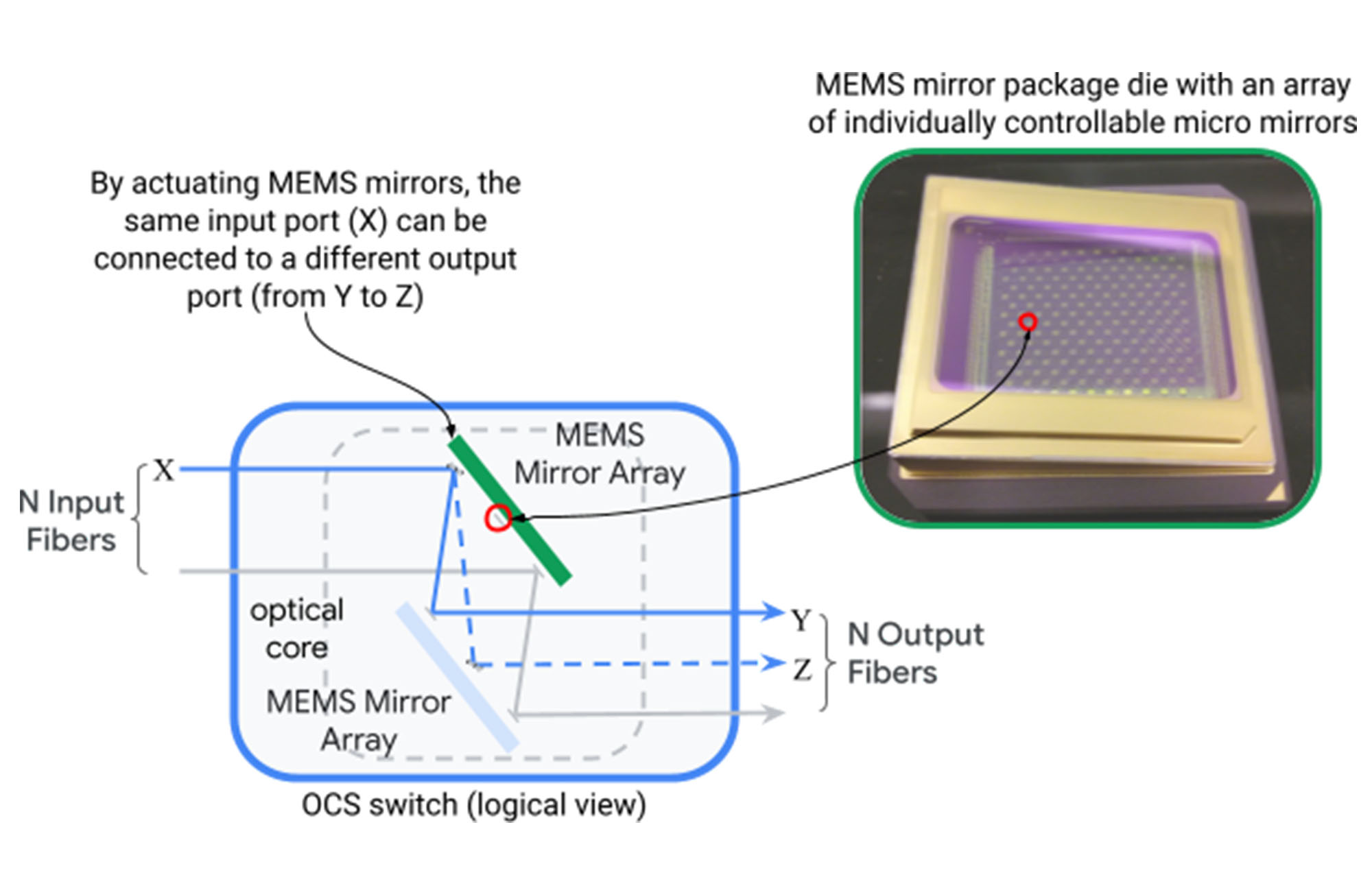
Addressing these remaining challenges seemed impossible at first. Data center networks were built around hierarchical topologies at massive physical scale such that supporting incremental heterogeneity and dynamic application adaptation could not be incorporated into the design. We broke this impasse by developing and introducing Optical Circuit Switching (OCS) into the Jupiter architecture. An optical circuit switch (depicted below) maps an optical fiber input port to an output port dynamically through two sets of micro-electromechanical systems (MEMS) mirrors that can be rotated in two dimensions to create arbitrary port-to-port mappings.
We had the insight that we could create arbitrary logical topologies for data center networks by introducing an OCS intermediation layer between data center packet switches as shown below.
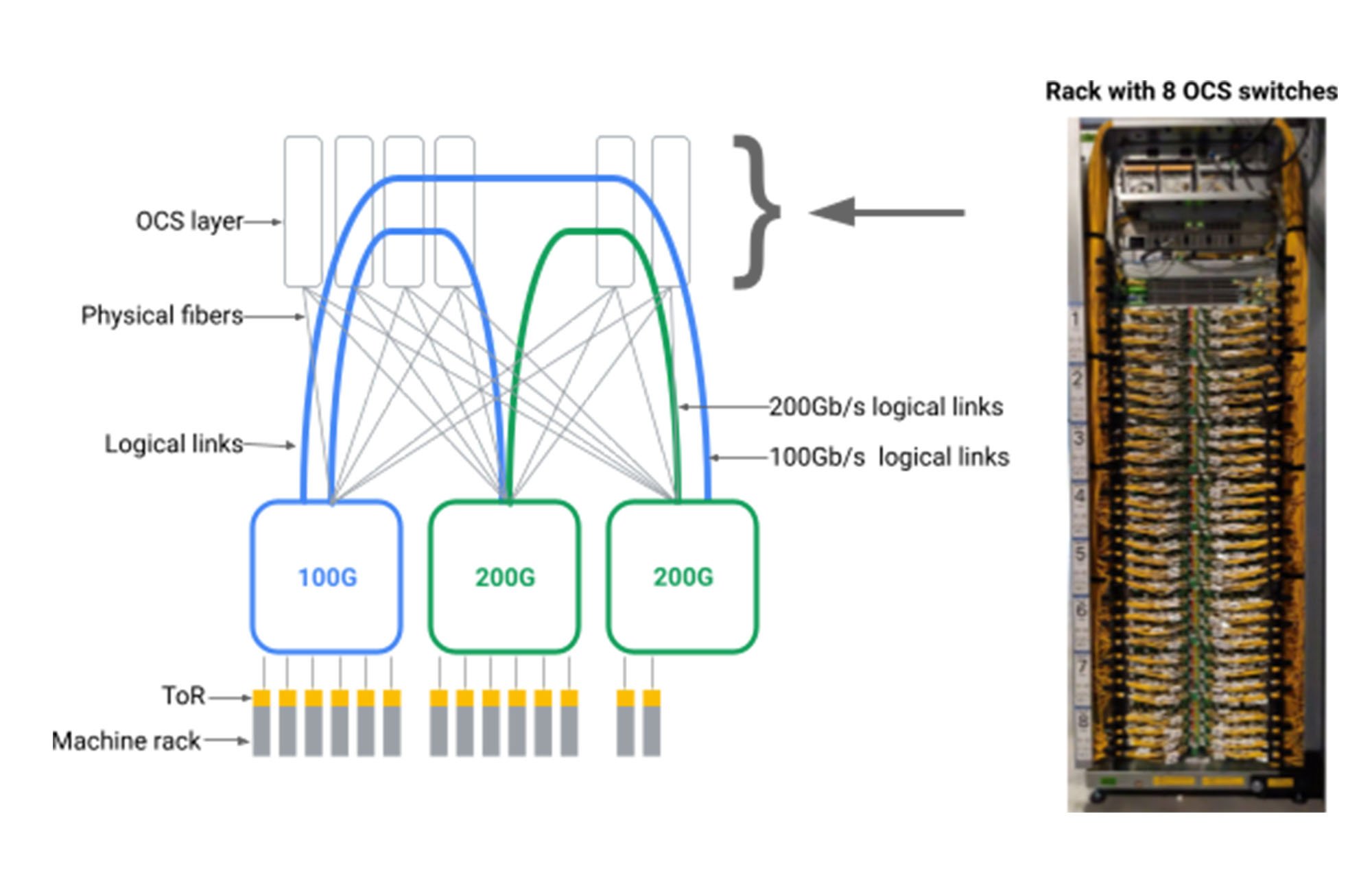
Doing so required us to build OCS and native WDM transceivers with levels of scale, manufacturability, programmability and reliability never achieved before. While academic research investigated the benefits of optical switches, conventional wisdom suggested that OCS technology was not commercially viable. Over multiple years, we designed and built Apollo OCS that now forms the basis for the vast majority of our data center networks.
One salient benefit of OCS is that no packet routing or header parsing are involved in its operation. OCS simply reflects light from an input port to an output port with incredible precision and little loss. The light is generated through electro-optical conversion at WDM transceivers already required to transmit data reliably and efficiently across data center buildings. Hence, OCS becomes part of the building infrastructure, is data rate and wavelength agnostic, and does not require upgrades even as the electrical infrastructure moves from transmission and encoding rates of 40Gb/s to 100Gb/s to 200Gb/s — and beyond.
With an OCS layer, we eliminated the spine layer from our data center networks, instead connecting heterogeneous aggregation blocks in a direct mesh, for the first time moving beyond Clos topologies in the data center. We created dynamic logical topologies that reflected both physical capacity and application communication patterns. Reconfiguring the logical connectivity seen by switches in our network is now standard operating procedure, dynamically evolving the topology from one pattern to another with no application-visible impact. We did this by coordinating link drains with routing software and OCS reconfiguration, relying on our Orion Software Defined Networking control plane to seamlessly orchestrate thousands of dependent and independent operations.
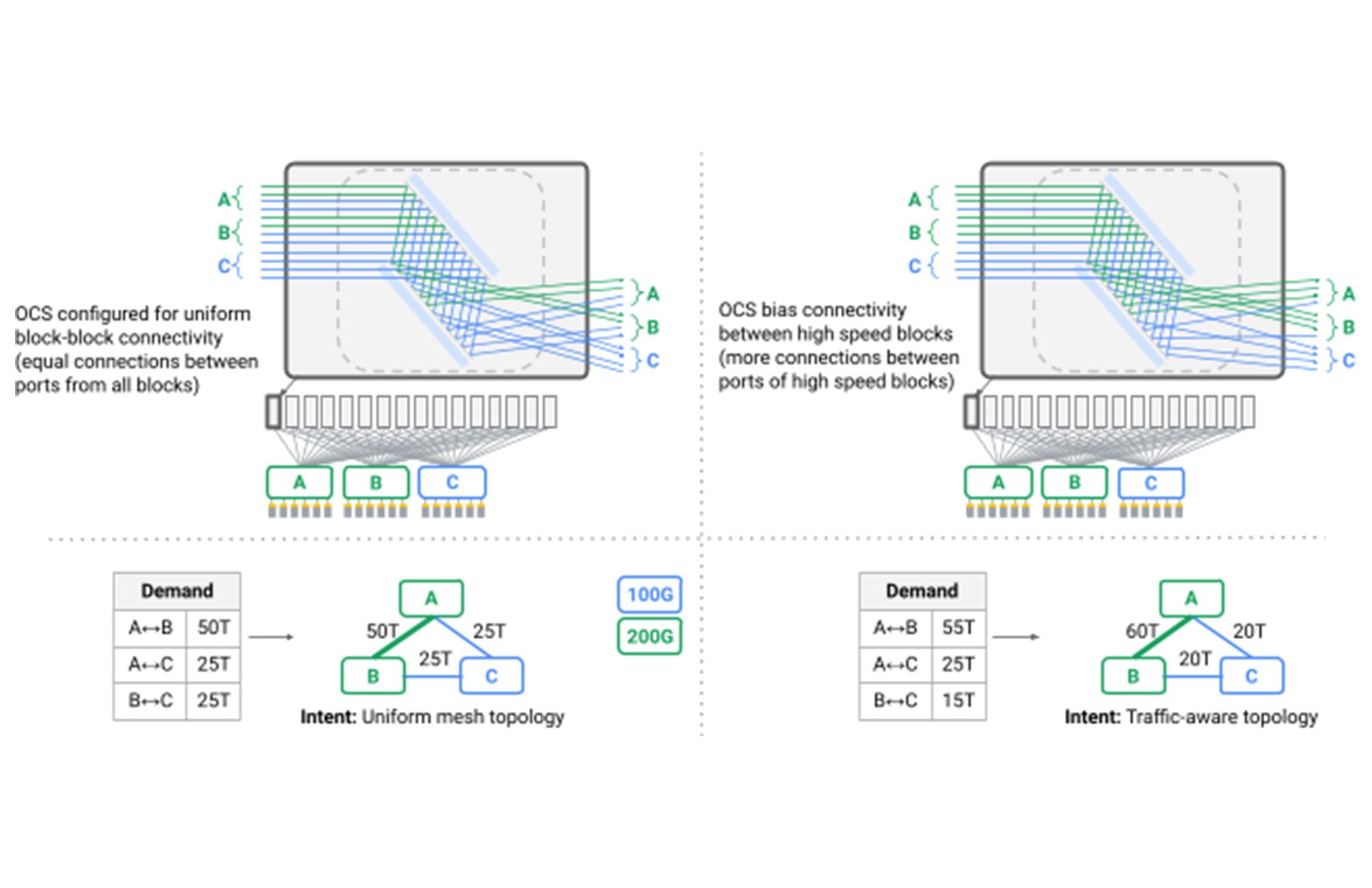
A particularly interesting challenge was that, for the first time, shortest path routing over mesh topologies could no longer provide the performance and robustness required by our data center. A side effect of typically-deployed Clos topologies is that while many paths are available through the network, all of them have the same length and link capacity, such that oblivious packet distribution, or Valiant Load Balancing, provides sufficient performance. In Jupiter, we leverage our SDN control plane to introduce dynamic traffic engineering, adopting techniques pioneered for Google’s B4 WAN: We split traffic among multiple shortest and non-shortest paths while observing link capacity, real-time communication patterns, and individual application priority (red arrows in the figure below).
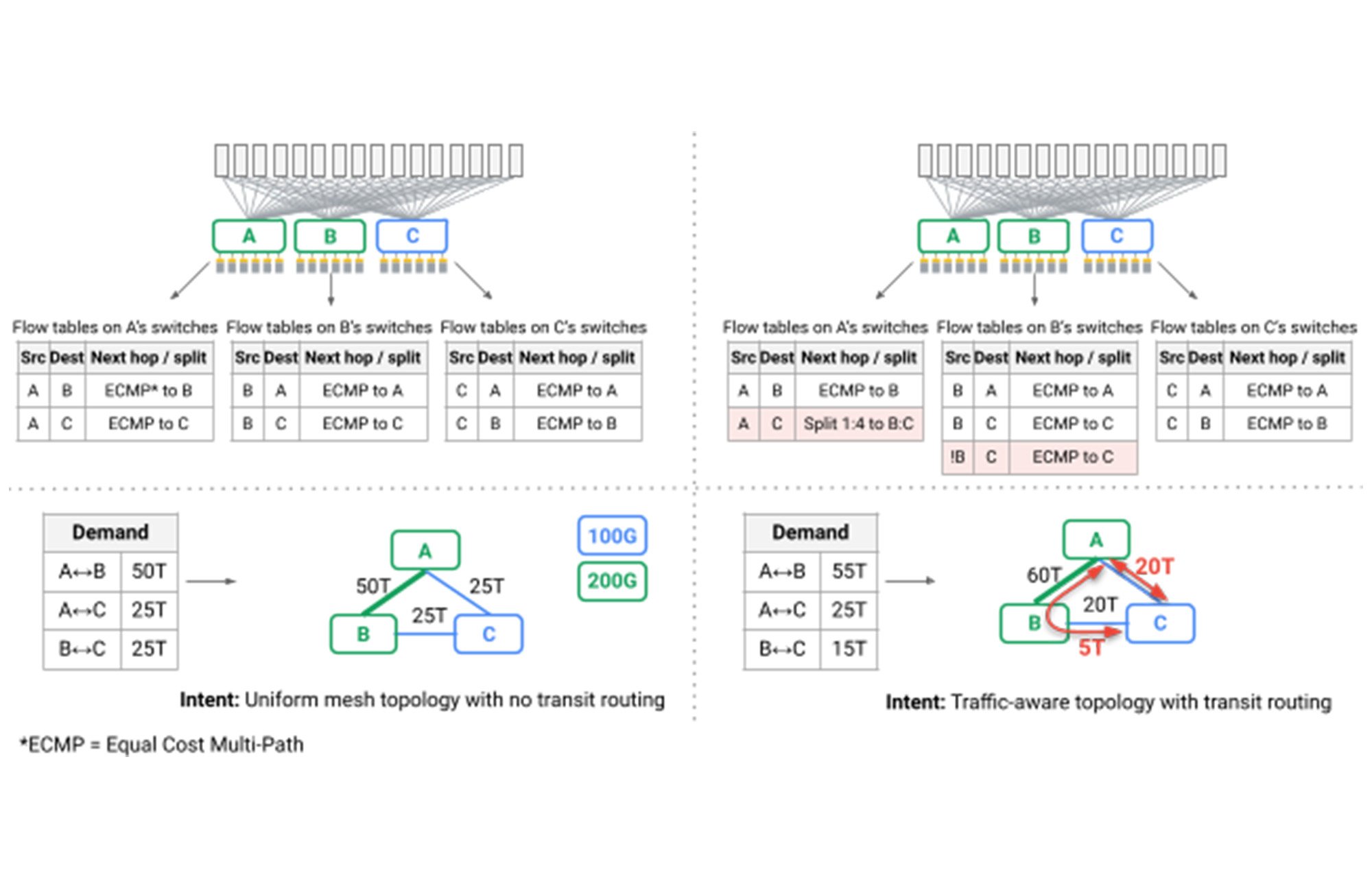
Taken together, we have iteratively completely re-architected the Jupiter data center networks that power Google’s warehouse-scale computers, introducing a number of industry firsts along the way:
Optical Circuit Switches as the interoperability point for building-scale networks, seamlessly supporting heterogeneous technologies, upgrades, and service requirements.
Direct mesh-based network topologies for higher performance, lower latency, lower cost, and lower power consumption.
Real-time topology and traffic engineering to simultaneously adapt network connectivity and pathing to match application priority and communication patterns, all while observing real-time maintenance and failures.
Hitless network upgrades with localized add/remove of capacity, eliminating the need for expensive and toilsome “all services out” style upgrades that previously required hundreds of individual customers and services to move their services for extended building downtime.
While the underlying technology is impressive, the end goal of our work is to continue to deliver performance, efficiency, and reliability that together provide transformative capabilities for the most demanding distributed services powering Google and Google Cloud. As mentioned above, our Jupiter network consumes 40% less power, incurs 30% less cost, and delivers 50x less downtime than the best alternatives we are aware of, all while reducing flow completion by 10% and improving throughput by 30%. We are proud to share details of this technological feat at SIGCOMM today, and look forward to discussing our findings with the community.
Congratulations and thank you to the countless Googlers that work on Jupiter everyday and to the authors of this latest research: Leon Poutievski, Omid Mashayekhi, Joon Ong, Arjun Singh, Mukarram Tariq, Rui Wang, Jianan Zhang, Virginia Beauregard, Patrick Conner, Steve Gribble, Rishi Kapoor, Stephen Kratzer, Nanfang Li, Hong Liu, Karthik Nagaraj, Jason Ornstein, Samir Sawhney, Ryohei Urata, Lorenzo Vicisano, Kevin Yasumura, Shidong Zhang, Junlan Zhou, Amin Vahdat.
1. An aggregation block comprises a set of machine (compute/storage/accelerator) racks including Top-of-Rack (ToR) switches connected by a layer of typically co-located switches.

