Build intelligent applications with Neo4j Knowledge Graphs and Google Cloud generative AI
Ezhil Vendhan
Senior Cloud Partner Architect, Neo4j
Dr. Ali Arsanjani
Director, AI/ML Partner Engineering, Google Cloud
In this blog post, we’re going to show you how to use two technologies together: The generative AI functionality in Google Cloud Vertex AI, an ML development platform, and Neo4j, a graph database. Together these technologies can be used to build and interact with knowledge graphs.
The code underlying this blog post is available here.
Why should you use generative AI to build knowledge graphs?
Enterprises struggle with the challenge of extracting value from vast amounts of data. Structured data comes in many formats with well defined APIs. Unstructured data contained in documents, engineering drawings, case sheets, and financial reports can be more difficult to integrate into a comprehensive knowledge management system.
Neo4j can be used to build a knowledge graph from structured and unstructured sources. By modeling that data as a graph, we can uncover insights in that data not otherwise available. Graph data can be huge and messy to deal with. Generative AI on Google Cloud makes it easy to build a knowledge graph in Neo4j and then interact with it using natural language.
The architecture diagram below shows how Google Cloud and Neo4j work together to build and interact with knowledge graphs.
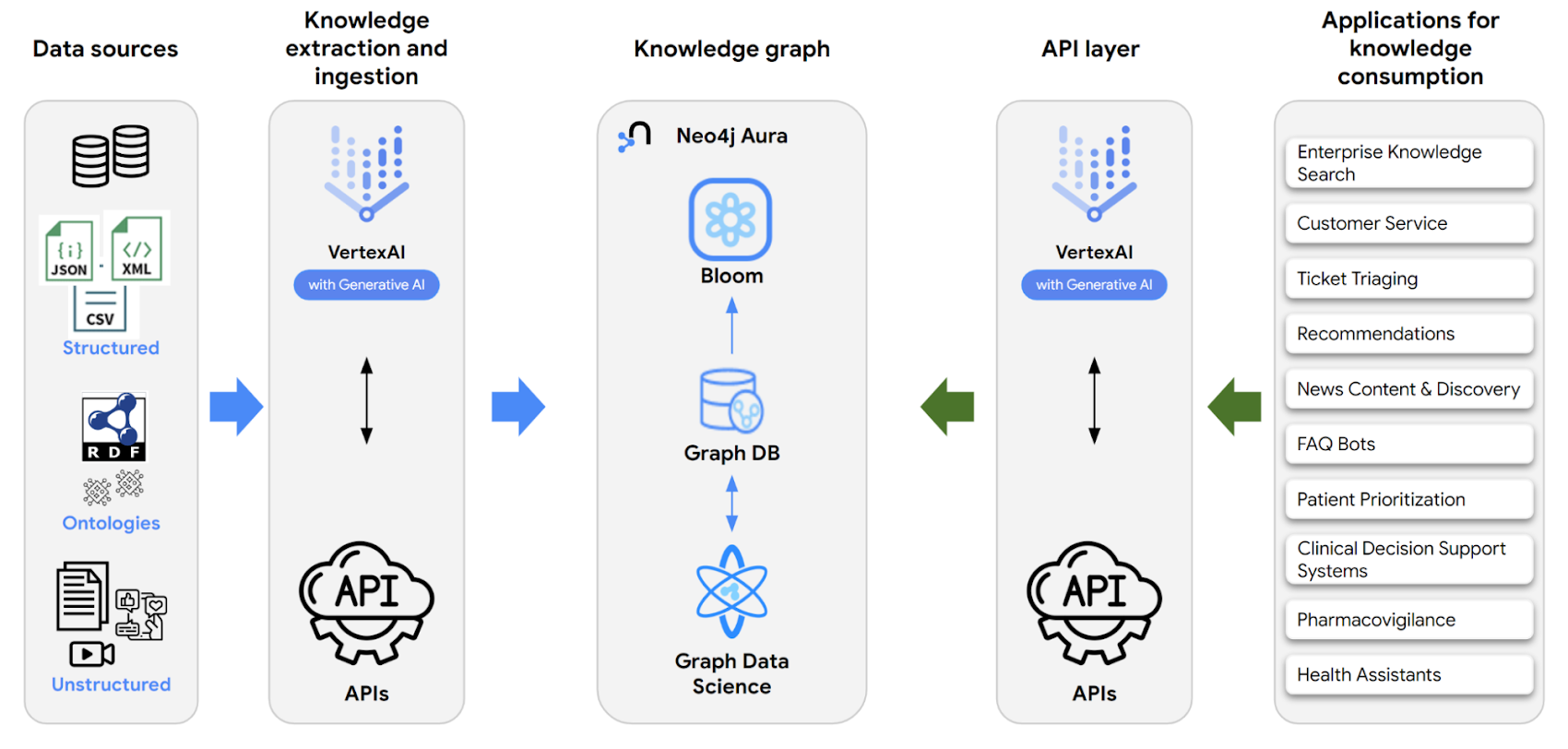
The diagram shows two data flows:
Knowledge extraction - On the left side of the diagram, blue arrows show data flowing from structured and unstructured sources into Vertex AI. Generative AI is used to extract entities and relationships from that data which are then converted to Neo4j Cypher queries that are run against the Neo4j database to populate the knowledge graph. This work was traditionally done manually with handcrafted rules. Using generative AI eliminates much of the manual work of data cleansing and consolidation.
Knowledge consumption - On the right side of the diagram, green arrows show applications that consume the knowledge graph. They present natural language interfaces to users. Vertex AI generative AI converts that natural language to Neo4j Cypher that is run against the Neo4j database. This allows non technical users to interact more closely with the database than was possible without generative AI
We’re seeing this architecture come up again and again across verticals. Some examples include:
Healthcare - Modeling the patient journey for multiple sclerosis to improve patient outcomes
Manufacturing - Using generative AI to collect a bill of materials that extends across domains, something that wasn’t tractable with previous manual approaches
Oil and gas - Building a knowledge base with extracts from technical documents that users without a data science background can interact with. This enables them to more quickly educate themselves and answer questions about the business.
Now that we have a high level picture of where this technology can be used, let’s focus on a particular example.
Dataset and architecture
In this example we’re going to use the generative AI functionality in Vertex AI to parse documents from the Securities and Exchange Commision (SEC). Asset managers who manage over $100 million are required to file Form 13 once a quarter. Form 13 describes their holdings.
We’re going to build a knowledge graph from those entities that shows what holdings different asset managers share with one another.
The architecture to do this is a specific version of the architecture we saw above.
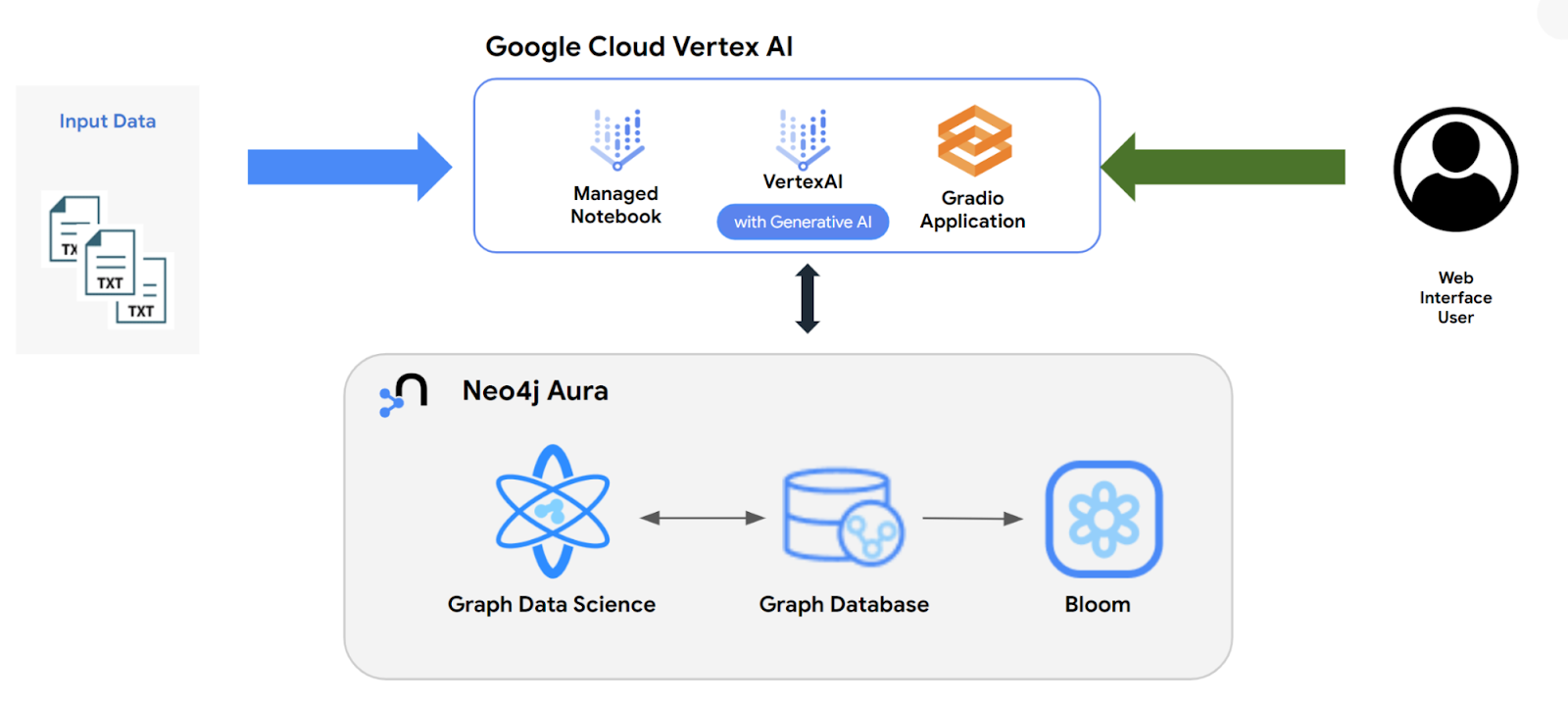
In this case, we have just one data source, rather than many. The data all comes from semi-unstructured text in the Form 13 filings. The documents are a rather odd mix of text and XML unique to the SEC’s EDGAR system. As such, a convenient shortcut to parsing them is quite useful.
Once we’ve built the knowledge graph, we’ll use a Gradio application to interact with it using natural language.
Knowledge Extraction
Neo4j is a schema flexible database, allowing you to bring in new data and relevant schema, connect them to existing ones, or iteratively modify the existing schema based on the use case.
Here is a schema that represents the data set:

To transfer unstructured data to Neo4j, we must first extract the entities and relationships. This is where generative AI foundation models like Google’s PaLM 2 can help. Using prompt engineering, the PaLM 2 model can extract relevant data in the format of our choice. In our chatbot example, we can chain multiple prompts using PaLM 2’s “text-bison” model, each extracting specific entities and relationships from the input text. Chaining prompts can help us avoid token limitation errors.
The prompt below can be used to extract company and holding information as JSON from a Form13 document:
The output from text-bison model is then:
The text-bison model was able to understand the text and extract information in the output format we wanted. Let’s take a look at how this looks in Neo4j Browser.
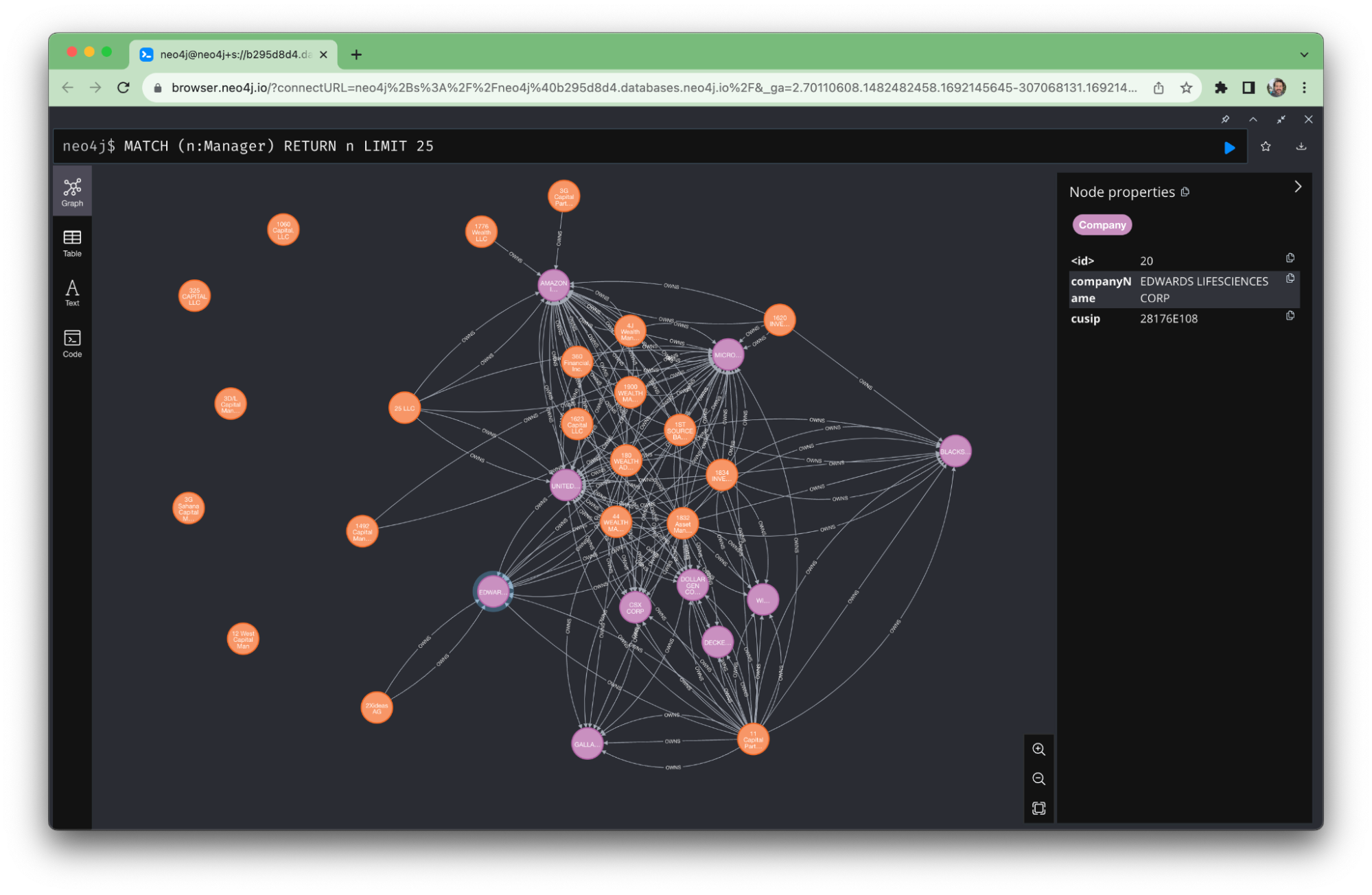
The screenshot above shows the knowledge graph that we built, now stored in Neo4j Graph Database.
We’ve now used Vertex AI generative AI to extract entities and relationships from our semistructured data. We wrote those into Neo4j using Cypher queries created by Vertex AI. These steps would previously have been manual. Generative AI helps automate them, saving time and effort.
Knowledge consumption
Now that we’ve built our knowledge graph, we can start to consume data from it. Cypher is Neo4j’s query language. If we are to build a chatbot, we have to convert the input natural language, English, to Cypher. Models like PaLM 2 are capable of doing this. The base model produces good results, but to achieve better accuracy, we can use two additional techniques:
Prompt Engineering - Provide a few samples to the model input to achieve the desired output. We can also try chain of thought prompting, to teach the model how to achieve a certain Cypher output.
Adapter Tuning (Parameter Efficient Fine Tuning) - We can also adapter tune the model using sample data. The weights generated this way will stay within your tenant.
The data flow in this case is then:
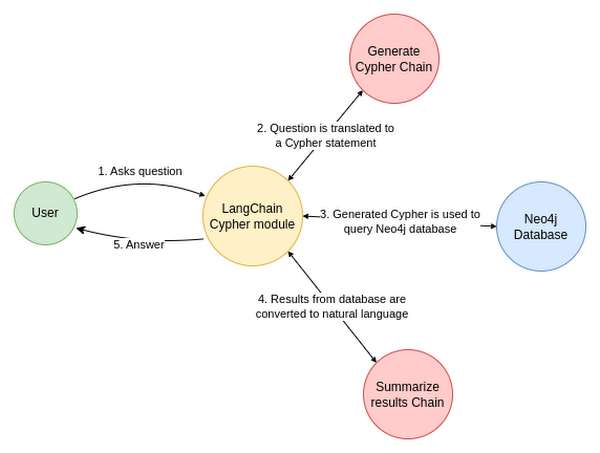
With a tuned model, we can use a simple prompt to turn text-bison into a Cypher expert as:
Vertex AI generative AI is then able to respond to a question like “Which managers own FAANG stocks?” like this in Cypher:
This is kind of amazing. Vertex AI has understood what FAANG means, mapped that to company names and then created a Cypher query based on that. The final answer is “Beacon Wealthcare LLC and Pinnacle Holdings, LLC own FAANG stocks.”
Gradio even provides a nice chatbot widget to wrap this all up.
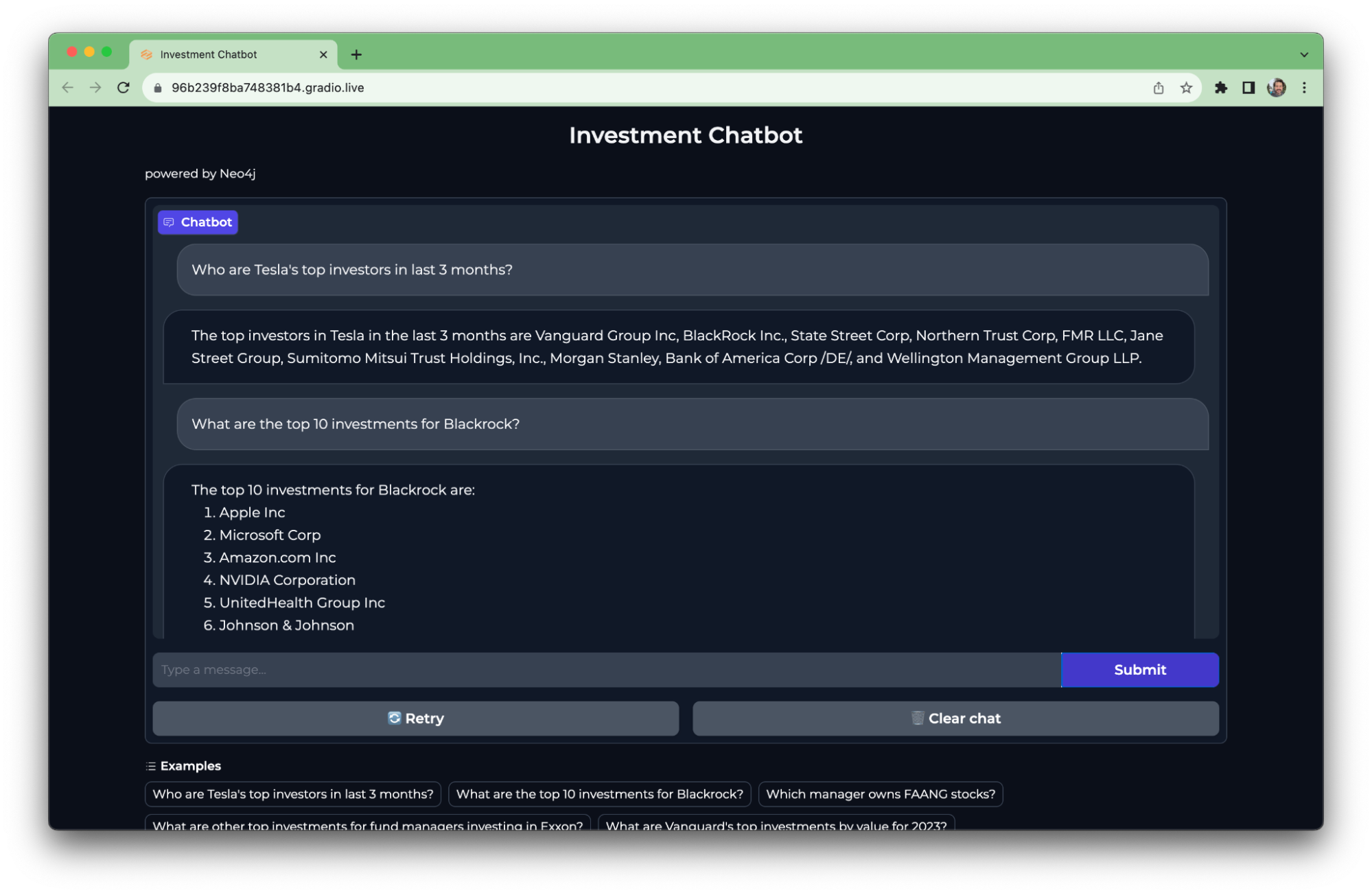
In our chatbot, we’ve included a few example questions to get you started.
Summary
In this blog post, we walked through a two part data flow:
Knowledge Extraction - Taking entities and relationships from our semistructured data and building a knowledge graph from it.
Knowledge Consumption - Enabling a user to ask questions of that knowledge graph using natural language.
In each case, it was the unique combination of generative AI capabilities in Google Cloud Vertex AI and Neo4j that made this possible. The approach here automates and simplifies what was previously a very manual process. This opens up applying the knowledge graph approach to a class of problems where it was not previously feasible.
Next Steps
We hope you found this blog post interesting and want to learn more. The example we’ve worked through is here. We hope you fork it and modify it to meet your needs. Pull requests are always welcome!
If you have any questions, please reach out to ecosystem@neo4j.com


