A technical solution producing highly-personalized investment recommendations using ML

David Sabater Dinter
Product Manager, Data Analytics Google Cloud
Oleksii Lialka
SoftServe Senior Data Scientist
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialDeveloped by SoftServe with the use of Google Cloud, the Investment Products Recommendation Engine (IPRE) is a solution designed to tackle common retail banking customer investment challenges. In particular, it makes investment recommendations based on BigQuery ML model capabilities. Big data pipelines are utilized to process investment data. The environment setup is automated with the use of Terraform. In this blog post we will take a closer look at the technical implementation of the solution.
Solution architecture
Let’s dive deeper into the technical part of the solution and consider solution architecture.
Components of the pattern architecture are split into three main areas, shown in Figure 1.
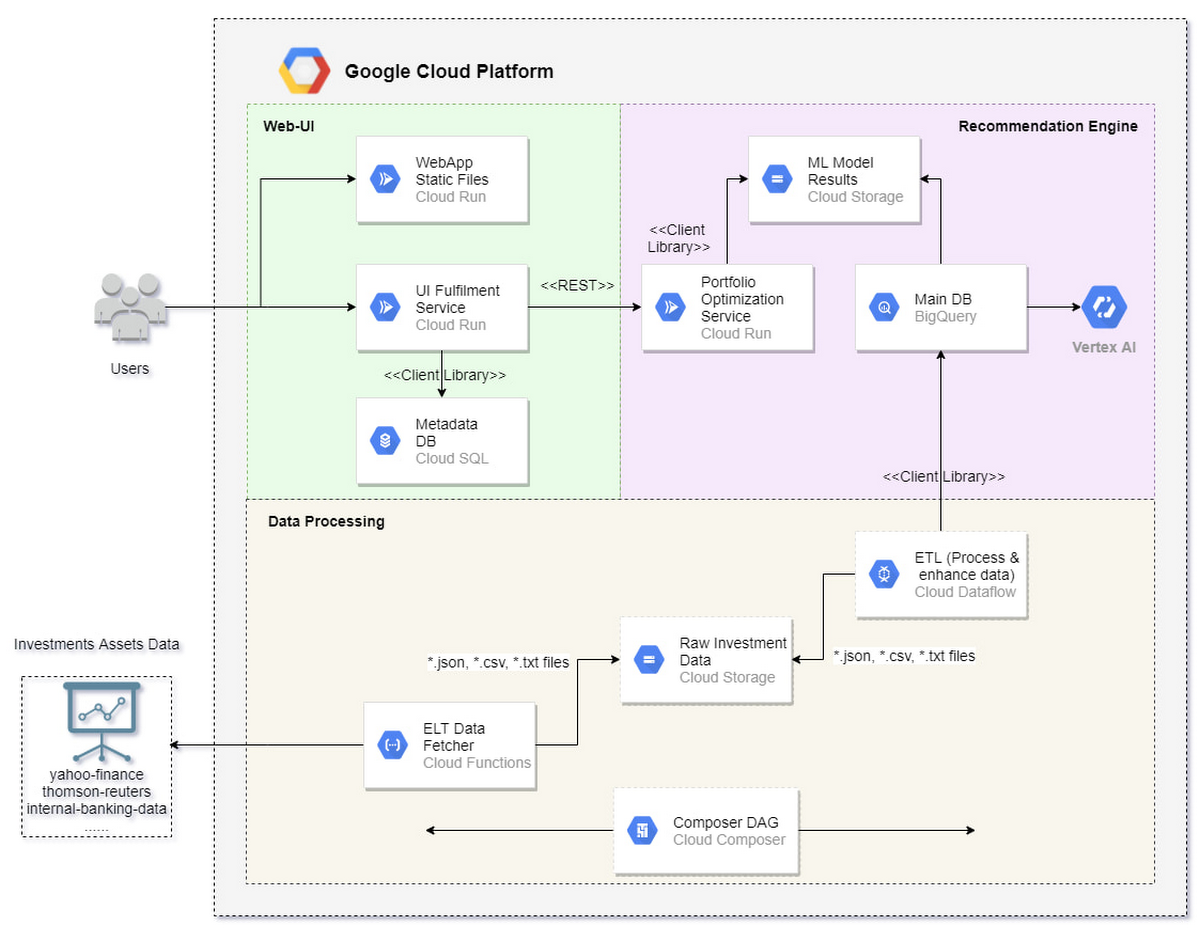
The Web-UI area is indicated by the green color and corresponds to the web application (React.js application deployed in Cloud Run). The application demonstrates features of investment risk preferences and portfolio investment recommendations. The web application has its database to respond to users’ requests.
The Data processing area is indicated by the beige color and corresponds to the Data Processing that performs data transformation, aggregation, and putting the data into a BigQuery data lake. That part includes fetching data from external sources (Yahoo Finance is used as sample data), storing raw data in Cloud Data Storage, transforming data with the use of Cloud Dataflow, and putting data into BigQuery. The data pipeline is orchestrated by Cloud Composer.
The Recommendation Engine area is indicated by the pink color and corresponds to the Recommendation Engine (RE). The RE provides portfolio optimization data for incoming requests from the web application. AutoML Tables models are used to make two different predictions:
Investor risk preferences
Investment recommendations
The solution is deployed on Google Cloud. Terraform is used to set up all required components and establish the right communications between them.
IPRE workflow
The following steps are executed to provide users with investment recommendations based on their risk preferences:
The Investor Risk Preference cloud function generates users’ synthetic data and their preferences.
Capital Market Data is fetched from Yahoo Finance by the Cap Market cloud function and stored as raw data in Cloud Storage.
When new raw data is available in the bucket, the Cloud Dataflow job orchestrated by Cloud Composer is triggered. Dataflow stores processed data in BigQuery.
BigQuery Training AutoML jobs, which are orchestrated by Cloud Composer, are triggered after initial setup (or daily) and create the corresponding BigQuery ML Models.
Based on available data, BigQuery AutoML generates potential Investor risk preference profiles and investment recommendations, and puts it into Cloud Storage.
The risk preference profile is determined for the user that signed in to the Web Application. The recommendations are displayed based on the user’s investment profile. A separate UI Fulfillment backend service provides recommended data to the user.
Each day, when new capital market data is available, investment portfolio recommendations are updated with the same flow.
Data pipelines
The IPRE service relies on multiple data sources, both internal and external. The solution implements scalable data pipelines with technologies, such as BigQuery, Cloud Storage, and Dataflow.
All external raw data streams are aggregated in dedicated Cloud Storage buckets. The Cloud Functions trigger minor pre-processing scripts. Writing an object to the Cloud Storage bucket triggers a Dataflow job for adding new data to BigQuery.
This type of architecture makes an ETL pipeline resilient to corrupt data and scalable to multiple data sources.
The Cloud Functions provide a clean, cost-effective solution for migrating massive datasets from data lake to DWH.
Capital markets data
Historical market data is a crucial element for the recommendation service. A dedicated data pipeline job collects quotes of the selected securities from Yahoo Finance. All selected assets vary in return and risk. This allows IPRE to construct a wide range of portfolios to meet diverse investors’ preferences. After minor preprocessing, daily historical quotes (q) are turned into periodic returns.

Returns of observations with a unique timestamp are written to Cloud Storage. It allows reducing egress and ensures that BigQuery does not receive duplicate data. During the first run of the script, all observations starting from 2017 will make it to BigQuery.
Subsequent runs provide incremental observations of the ”unseen” data. In the final stage of ETL, the processed data is written to BigQuery. Aggregating data in BigQuery allows other services to retrieve the data in a cost-effective way.
Investors risk preferences
The investor risk preferences (IRP) are a synthetic dataset containing historical records of thousands of existing retail investors. This dataset is a crucial component for making personalized recommendations based on an individual’s investment preferences.
The risk aversion is a target variable of interest. Average monthly income, education, loans, and deposits are among 15 independent variables. Investors’ attributes are generated using different continuous variable distribution functions: Gamma, Gumbel, Gaussian, R-distributed, and others. A script produces monthly snapshots of investors’ attributes, resulting in 48,000 data points.
The Cloud Function triggers a generation of the dataset upon the first launch of IPRE. Dataflow migrates the generated dataset from Cloud Storage to BigQuery.
Machine learning advanced analytics
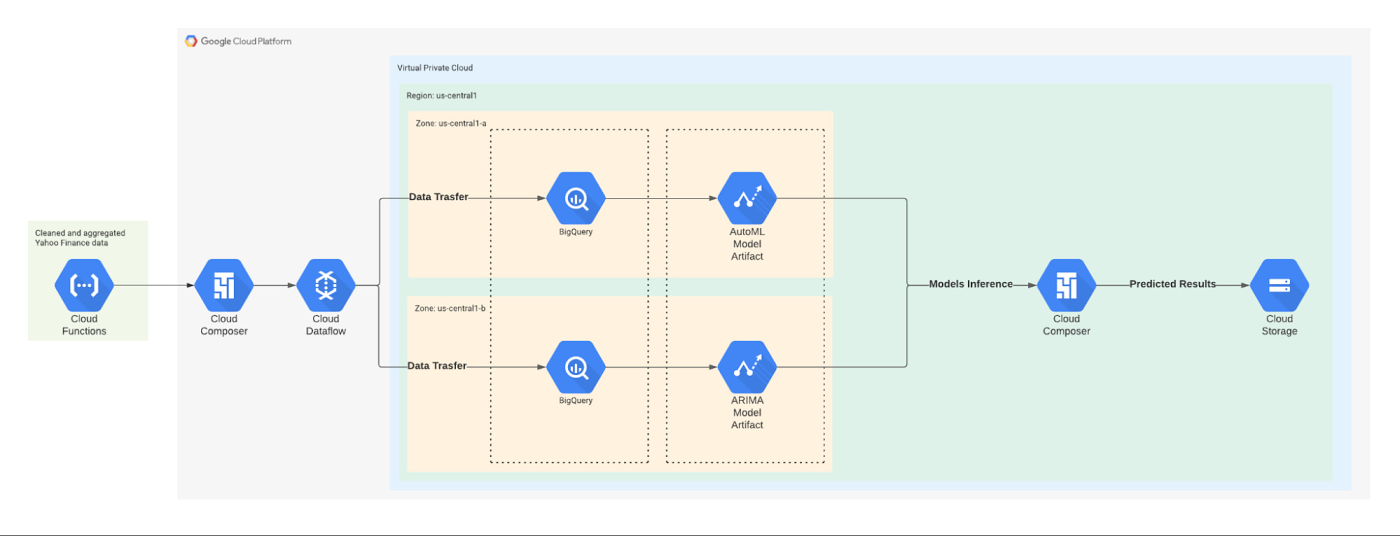
The machine learning (ML) workflow is as follows:
Raw data is preprocessed and uploaded to GCS. A Dataflow job is registered through Google Composer.
Processed data is uploaded to BigQuery with predefined data schema and data format.
By the Pub/Sub trigger, training of AutoML and ARIMA models is triggered. The training is performed with the use of integrated BigQuery ML tools.
When the training has completed, the system triggers the inference process.
Individual risk preferences and ticker’s prices are predicted by taking the uploaded BigQuery data as an input.
Predicted results are saved to Cloud Storage to cache the results and make the data reusable.
Results are published through the recommendation engine, which is deployed on Cloud Run, and prediction results are sent to the end user.
The workflow is shown in Figure 2.
IPRE implementation features
The solution is designed to be highly reproducible, with the minimal manual effort required to set up all services.
Users of the web application can create several wallets and switch among them. In addition to working with wallets, users can see investment recommendations and their portfolio with detailed statistics.
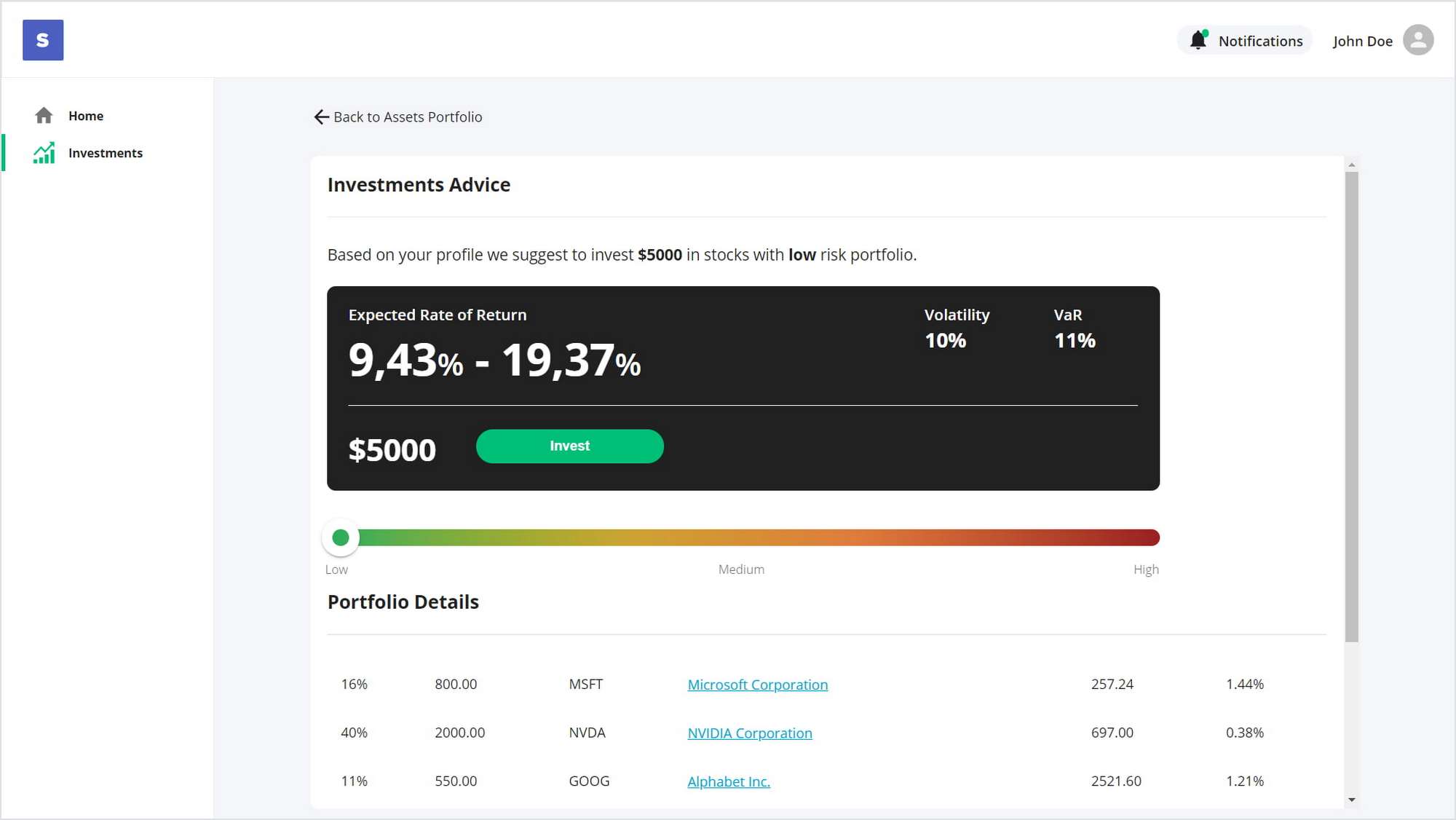
The application's back end is a service developed using Django Framework. The service, which acts as a bridge between the IPRE and the web application, is responsible for working with wallets, managing transactions, showing user portfolio..
The ML interface pipeline is designed with ease of deployment in mind, so that the solution can be deployed on Google Cloud with just one click.
Better investing with IPRE
Using Google Cloud Platform, SoftServe developed the IPRE solution, and within the solution implemented an end-to-end automated MLmodel that can be deployed in one click. SoftServe’s Investment Products Recommendation Engine serves as a pivotal point in increasing the cross-selling potential of investment products to retail banking customers. It establishes a bridge between retail banking investors, who are non-finance professionals, and the complexity of modern capital markets investment vehicles. The solution applies ML technology for micro-segmentation of user groups based on their risk preferences to provide highly personalized investment products selection to an individual user.
The IPRE makes investment recommendations based on BigQuery ML Model capabilities and uses Big Data pipelines to process investment data. The environment setup is automated by Terraform. The solution incorporates a fully automated ML process. Extensive pattern automation will help developers easily switch to implementation and explore different configuration options.
If you want to dive deeper into the solution or implement your own IPRE with the use of GCP, please check out the pattern details or reach out to the Google Cloud or SoftServe team to get more information.



