Detect spoofing exceptions in financial markets with Google Cloud and GTS
Vishakha Sadhwani
Customer Engineer, Google Cloud
Victor Zigdon
Director of Trading Analytics, GTS Securities, LLC
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialRegulatory Surveillance of Trading Activity with Google Cloud
The purpose of regulatory surveillance is to verify market fairness and protect against unethical trading behavior. Since regulatory reporting requirements have local differences, global financial institutions often need to operate in a large number of jurisdictions, meet specific variations of the local regulations of each, conduct internal surveillance, and justify their firm's compliance approaches. Additionally, with the rapid increase in low-latency co-location trading networks, the speed at which orders are entered to the market and transactions are executed has gone from seconds to microseconds, while the volume has simultaneously exploded. Thus, these firms require robust recording and surveillance solutions to monitor and audit trading activity for potential market manipulation and make this available to internal stakeholders and regulators. This blog focuses on one such solution that is built on Google Cloud, using SQL analytics on BigQuery.
Market surveillance is getting more complex as deceptive trading practices increase with higher trading volume and the emergence of new asset classes. One such deceptive practice is “spoofing,” which largely revolves around the intent (or lack thereof) of traders to place bonafide orders, devoid of any premeditation to cancel a particular order before or at the time of its placement. “Flashing” is a form of market spoofing — where market participants exhibit a pattern of submitting orders that are not intended to be fulfilled, but rather only to move ("improve") the market to benefit a subsequent order on the other side of the market. The “flashed” orders are short-lived orders, which are canceled quickly after being entered and before getting executed. In the world of electronic trading, order entry is fully automated and typically happens within milliseconds or microseconds.
Large financial institutions have solved this by implementing in-house surveillance systems that operate in their local data centers. Although on-premises solutions achieve the desired result of detecting and reporting such activities, one challenge is their long implementation and testing cycles. Another is the costly and rigid infrastructure, often overprovisioned to serve the peak times of the reporting cycles and sitting largely unused the remainder of the time. Hence, these institutions need mechanisms for efficiently operating the surveillance processes, and use the data for value-add activities.
This blog post’s focus — a cloud-native pipeline that fits to help meet cost-saving targets, operational efficiencies and demanding evolving regulatory requirements — collaboratively developed by GTS Securities LLC, Strike Technologies LLC (its technology provider) and Google Cloud, is one such mechanism.

GTS is a leading global, electronic market maker that combines market expertise with innovative, proprietary technology. As a quantitative trading firm continually building for the future, GTS leverages the latest in artificial intelligence systems and sophisticated pricing models to bring consistency, efficiency, and transparency to today’s financial markets. GTS accounts for 3-5% of daily cash equities volume in the U.S. and trades over 30,000 different instruments globally, including listed and OTC equities, ETFs, futures, commodities, options, fixed income, foreign exchange, and interest rate products. GTS is the largest Designated Market Maker (DMM) at the New York Stock Exchange, responsible for nearly $12 trillion of market capitalization.
Detecting flashing exceptions
GTS modeled its flashing detection analytics solution on Google Cloud after its post-trade surveillance system, a large-scale simulation framework that marries the firm’s bidirectional trading order data with the high resolution market-data feeds disseminated by the exchanges into a uniform stream. The stream is analyzed by numerous surveillance reports to perform a fully automated regulatory compliance review.
Datasets
Market Data
Public high resolution tick data disseminated by the exchanges
A unidirectional data stream of quotes, trades, symbol trading status, etc.
These per-exchange feeds are collected, normalized and merged to a per-symbol uniform stream
For the purposes of this surveillance, the market-wide best bid and ask price (NBBO - National Best Bid / Offer) at any given time are used
Order Data
Proprietary order activity of the market participant under review
A bidirectional data stream initiated by the market participant
A simplified life cycle of a single order is illustrated below:
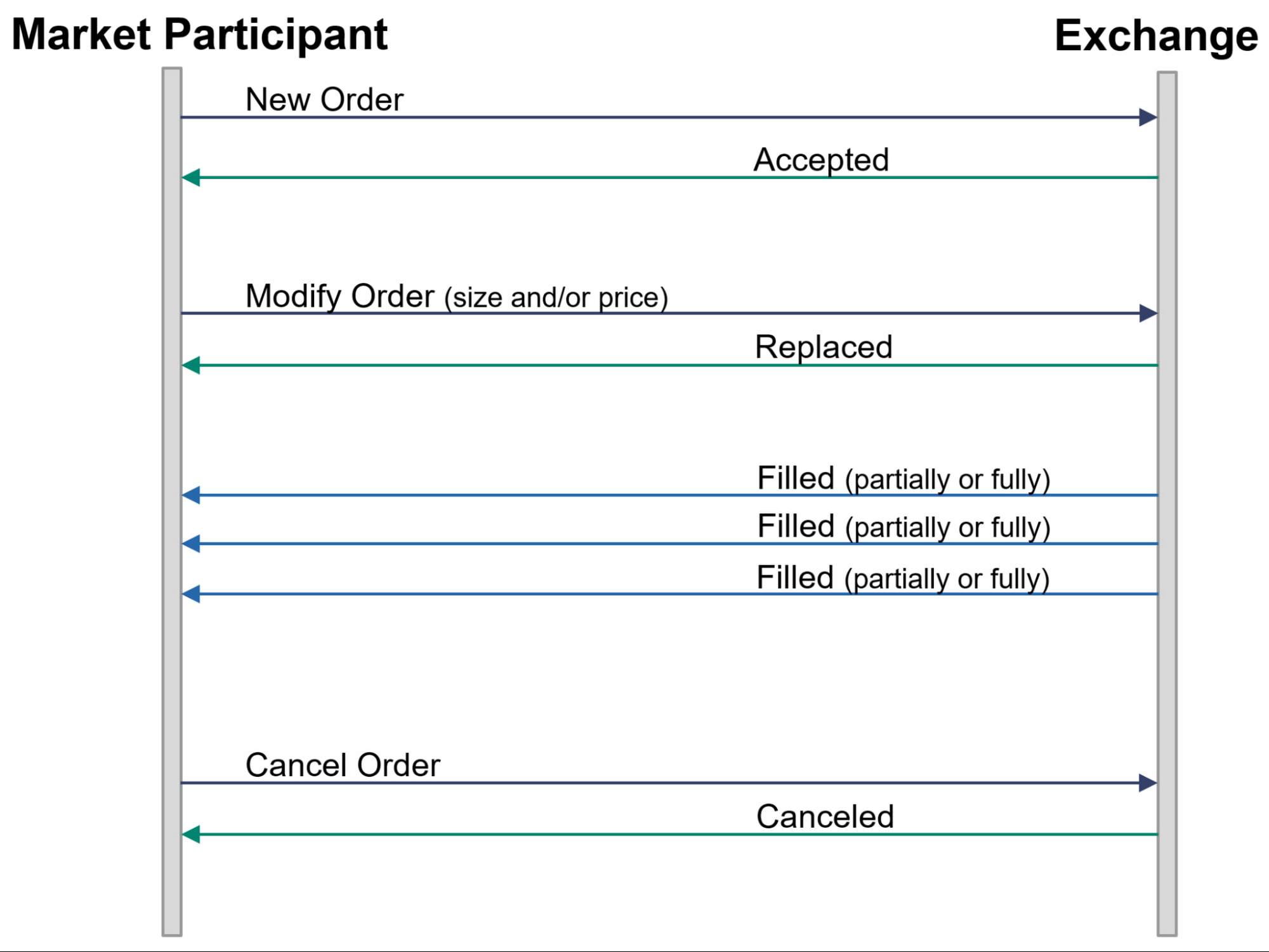
Flashing detection
This surveillance is designed to capture the manipulative practice of placing orders with no trading intention. Rather, these orders are placed on the market to induce a favorable movement.
A flashing activity is composed of a “flash” and “take” events:
Flash
Entry of short-lived orders on one side of the market
These orders are not meant to be executed (filled) just to show an artificial interest on the market, as such they are canceled a short period after being entered
Note that the flashed order lifespan is a parameter of the surveillance that should be configured to fit the trading profile of the firm under review
For demonstration purposes we used 500ms (though in practice this can happen over a much smaller timespan)
Market-movement
Other market participants react to the flashed order/s, moving the price towards the indicated direction, i.e., causing the NBBO to “improve”
Take
Placement of an order/s on the other side of the market that gets executed against other market participants that joined the market at the improved price
Note that the take order can be “staged” on the market prior to the initiation of the flashing order or entered after it
Furthermore, the take event should be in proximity to the Flash event
For demonstration purposes we configured this parameter to 10 seconds
As indicated above, flashing detection requires marrying the order activity of the market participant under review with the public market data, essentially synchronizing two large and discrete nanosecond resolution datasets. In addition to the technical challenge of joining these datasets, we recognize that a trading platform might introduce a small latency when processing large market-data volumes. Further, there might be slight clock differences between the trading-platform and surveillance system’s view of the market-data. To compensate for this difference, the surveillance system employs a windowing mechanism when reviewing the NBBO (National Best Bid and offer) near the take event. The NBBO window length is a configurable parameter of the surveillance and should be set based on the specifics of the trading firm under review. For demonstration purposes we used a 1000ms window. Note that as is the case for discrete data, there might not be any NBBO update within the window. In such cases we carry forward the last NBBO update prior to the window.
Finally, any sequence of events that fit the scenario outlined above are flagged as potential exceptions to be reviewed by the compliance officer of the trading firm.
Modernizing this solution using SQL Analytics on Google Cloud
To implement the above points, the collaboration applies data analytics best practices to a financial services problem. This solution can enable efficient, flexible data processing — but also supports the organizational processes that enable reliable reporting and minimize fire drills.
At the highest level, the steps are executed in containers, which models the macros steps — e.g., load data / execute transform / run data quality. Cloud Composer (Apache Airflow) is the tool that helps orchestrate containers to run BigQuery SQL jobs. As discussed in the next section in detail, these queries are defined using DBT models instead of raw SQL.
DBT is the conversion tool that codifies the regulatory reporting transformations. It runs the SQL logic which implements the surveillance rules required by the regulator as per the rulebook. With DBT, models are parameterised into reusable components and coupled with BigQuery to execute the SQL models. It fits nicely into the stack and helps in creating a CI/CD pipeline that feeds normalized data to BigQuery.
BigQuery is a critical solution component because it can be cost-efficient, offer minimal operational overhead, and solve this high-granularity problem. By cheaply storing, rapidly querying and joining huge, granular datasets, BigQuery helps provide firms with a consistent source of high-quality data. This single source serves multiple report types.
The entire infrastructure in Google Cloud is deployed using Terraform, which is an open-source ‘Infrastructure as a code’ tool. It helps in storing configuration in declarative forms, Kubernetes yaml, etc; which helps promote portability, repeatability, and enable the platform to scale.
Solution overview
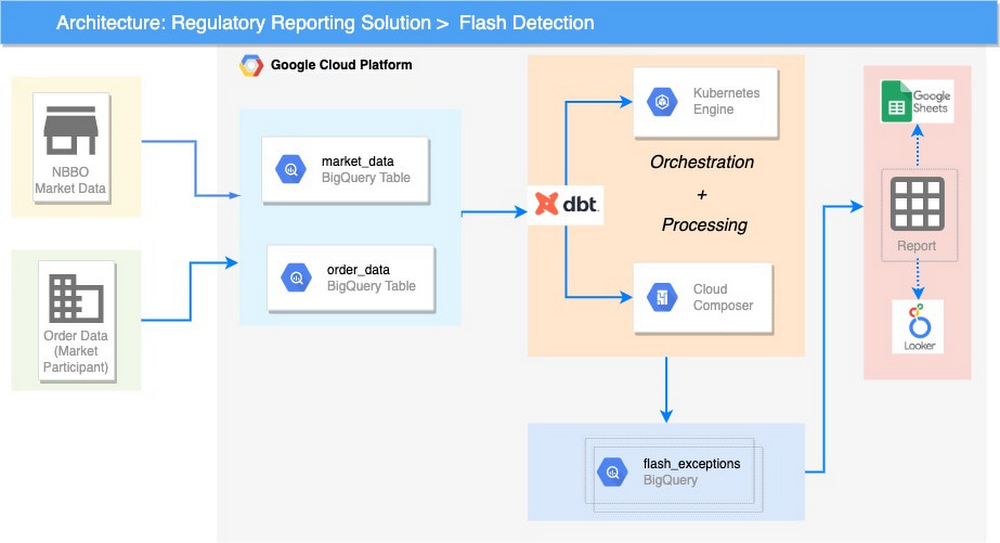
First, the pipeline must process sparse data from the two feeds, that is the public NBBO market data feed disseminated by the exchanges and proprietary order activity of the market participant under review. The source data is ingested to BigQuery, which supports running regulatory reporting workloads that exhibit frequent spikes in demand. This serverless infrastructure helps in processing complex queries within seconds and to address the scaling problem of legacy implementations.
Second, the pipeline must evaluate the order lifecycle, whether an order was entered and canceled within a short timeframe and whether this induced a market movement, which was later capitalized on. These conditions are compiled as reporting rules and expressed using ANSI SQL. As discussed above, we have leveraged an open source framework (DBT) to create reporting rules as code (i.e., modules) that can be released to regulated institutions. These reporting rules are in the form of DBT models that bundle together documentation (e.g., fields definitions) and technical schema. This framework also can remove the need for explicit maintenance by automatically building SQL DAGs of the models.
Third, the pipeline must execute these reporting rules for the order events and check for fluctuations in the market. A huge number of simple SQL queries may need to be spawned for generating the final reports. Hence, an orchestration capability can coordinate this processing, which takes place in a number of services. This is supported by running Cloud Composer workflows on Kubernetes. The output of the processing is saved back to BigQuery.
The end result is the report generation, which is supported by the analytics and reporting layer, that allows users to explore the data and work with it. This data can be accessed by Business Intelligence tools such as Looker or Google Sheets. If required, data can also be egressed on prem for analysis.
Give it a try
This approach is available to help you meet your organization’s reporting needs. Please review our user-guide, whose Tutorials section provides a step-by-step guide to constructing a simple data processing pipeline that can maintain quality of data, auditability, and ease of change and deployment, and also supports the requirements of regulatory reporting.



