Why you should be using Flex templates for your Dataflow deployments
Sergei Lilichenko
Solutions Architect, Google Cloud
Last year Google announced general availability of Dataflow Flex templates. We covered many details of this new way to deploy Dataflow pipelines in this blog. Here we offer additional tips and suggestions, best practices, details on using Google Artifact Repository for storing template’s Docker images, and ways to reduce cost for certain kinds of pipelines. You can dive deeper by reviewing the GitHub repository that has the code that implements many of these suggestions. While we use Java in our examples the majority of the recommendations also apply to Python pipelines.
If you are not familiar with Flex templates, here are the main advantages to using them compared to direct launch of the pipeline or classic templates.
Better security model
Flex templates allow assigning the least required privileges to different actors in the pipeline life cycle. Flex templates also help in the cases where the pipeline needs to access services only available on certain network/subnetworks.
Ability to dynamically define pipeline graphs
Dataflow is a runner of pipelines coded using Apache Beam SDK. Each Beam pipeline is a directed acyclic graph (DAG) of transforms. Pipeline developers define this graph as a sequence of “apply(transform)” methods. Often it is useful to be able to run a single pipeline in slightly different configurations. A typical example is a pipeline which can be run in the streaming mode to process Google Pub/Sub messages or in the batch mode to backfill from the data residing on Google Cloud Storage (GCS) buckets. The only difference between the two modes would be their starting transforms (reading from sources), but the rest of the graph is the same.
Interestingly enough, Beam DAGs don’t have to have a single starting source transform or be fully connected DAGs - one pipeline can have a number of independent and completely different DAGs. This can be a useful feature where a single pipeline can process a number of separate data sources in parallel, for example when processing relatively small (MBs to GB sized) GCS files of different types. Instead of running a pipeline per file you can run a pipeline per a group of files, and each will have its own processing DAG.
Only direct deployment or Flex template support the ability to dynamically define pipeline DAGs. We will show later an example of dynamic pipeline generation.
Ability to run pre-processing steps before pipeline construction
There are cases where a simple step performed before the pipeline is run can simplify the pipeline logic. Flex templates allow a certain amount of pre-processing to be run on a virtual machine (VM) with the pipeline credentials during the pipeline construction time.
Consider how you would build a pipeline to process a set of data files and a single-record control file that provides the total number of records that must be present in the data files. It’s possible to construct a Beam pipeline where one of its DAG branches would read the control file, create a single value side input and pass that input into some transform that would verify that the record count matches expected values. But this whole DAG branch can be removed if you can read and validate the control file during the graph construction time and pass the expected number of records as a parameter to the record count checking transform.
Let’s see how many of these concepts apply to a particular use case. Imagine that you need to periodically synchronize data from an on-premises relational database into BigQuery. There are several constraints to your solution. You need to use the pull approach - the pipeline will be querying the database to pull the data changed since the last synchronization event. While it is not the most efficient approach (Change Data Capture is preferred for high volume synchronization), it’s still a viable solution in many situations. The database contains sensitive data and can only be connected from a particular subnetwork in a Virtual Private Cloud (VPC). Database connection parameters (including the password) are stored in the Secret Manager. The database schema is a typical snowflake schema with a number of infrequently changing dimension tables and more frequently changing fact tables. We need to synchronize about 200 tables, orchestrating the synchronization using Cloud Composer.
If you were to implement this pipeline using the direct pipeline launch method or by creating a classic template you will face three main challenges:
Cloud Composer VMs need to be deployed in the same network as the database and the service account they run under would need to be able to read the Cloud Secrets - both are the case of excessive permissions.
If you coded the pipeline to process one table at a time you will most likely incur unnecessary costs when processing dimension tables with very few changed records, and would need to address the default Dataflow job number quota (25 concurrent jobs per project).
Direct deployment method will require the pipeline code and a Java SDK to reside on the Composer VMs. It typically requires additional steps in a Composer workflow to get the latest released code from the code repository, with additional permissions to access that repository.
To understand the reason behind the first challenge, let’s recall the life cycle of a pipeline. It’s covered in the Dataflow documentation, but here is a concise description of the three major phases:
Graph construction. It happens when the main() method of your pipeline’s class is invoked and all these apply() methods are called. They in turn invoke the expand() methods for each transform class and the pipeline object builds the execution graph of the pipeline.
Job creation. Execution graph is transferred to the Dataflow service, gets validated, and a Dataflow job is created.
Execution. The Dataflow service starts provisioning worker VMs. Serialized processing functions from the execution graph and required libraries are downloaded to the worker VMs and the Dataflow service starts distributing the data bundles to be processed on these VMs.
Among the three possible ways to launch a pipeline the job creation and execution phases are identical. The only difference is the timing, location, and security context of the graph construction phase:
Direct deployment. The graph is constructed on the VM which executes the main() method, e.g., Cloud Composer VM, and uses the credentials of the user or the service account associated with the VM.
Classic templates. The graph is typically constructed on the VM used by the build process and uses the credentials associated with that VM.
Flex templates. The graph is constructed at the pipeline launch time on a VM located in the same network as the Dataflow worker VMs and using the same service account as these worker VMs.
Only pipelines launched using Flex templates construct execution graphs in the same network location and use the same credentials as the VMs used in the execution phase. Graph construction phase is where many Beam’s standard transforms implement extensive validation of the input parameters, and, importantly, call the Google Cloud APIs to get additional information. Where it’s run and what security context is used can determine if your pipeline will fail to launch or not!
In our use case, Beam’s JdbcIO transform can be used to query the data. During the expand() method execution a database connection is established and a query is parsed by the database in order to obtain the metadata of the result set. It means that the invoker of the pipeline will need to have access to the database credentials and be on the same network as the database. If you were to run Cloud Composer jobs using the direct launch method you would need to co-locate Java code on the Composer VMs, grant the service account Composer uses the ability to access Cloud Secrets and run the Composer VMs on the same network as the database. By using the Flex template launch method you will enable clean separation of the invoker credentials (Dataflow jobs will be using a dedicated Service Account which is the only account with read access to the Cloud Secrets) and invocation location (Cloud Composer can run in a different network than the database).
Next challenge - how do you synchronize 200 tables efficiently? Ideally, you want to start a pipeline which processes multiple tables in a single run. Many of the sync jobs will be processing relatively small amounts of data and running a separate pipeline per table will create a lot of overhead. Syncing all tables at once will make your DBAs unhappy. A good middle ground is synching several tables at a time, most likely based on their interdependencies. Which means that our pipeline needs to have a list of sync jobs to run as a parameter (“option” in Beam parlance) and dynamically build an execution graph based on this list. Classic templates will not allow us to do that; they have a limited capability for parametrization and the pipeline graph is determined at the template build time. Flex templates handle this with ease using this pseudo code:
Here’s how this dynamic graph would look like in a pipeline with three tables to synch:
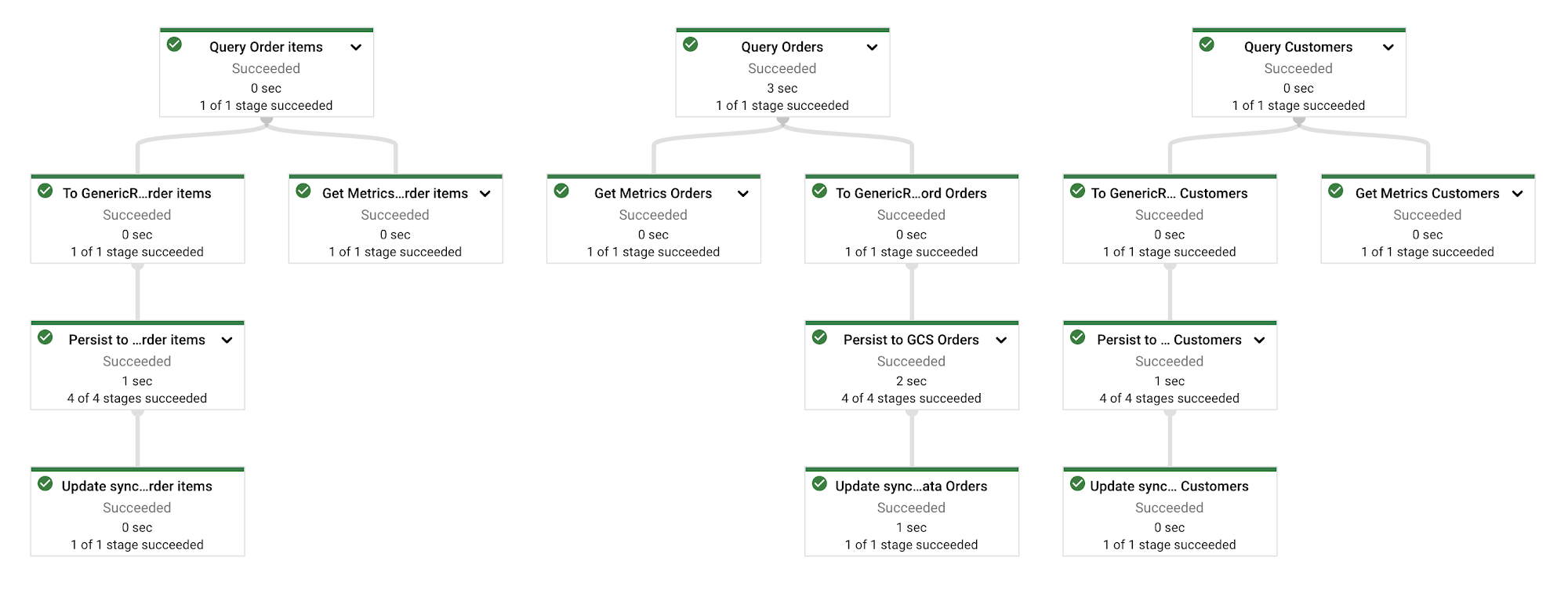
If the number of database changes is low a single worker VM of the default n1-standard-1 type can handle updates to dozens of tables at a time - it can be a sizable cost saving compared to launching a pipeline per table. The pipeline will autoscale if it determines that it would benefit from multiple workers to process the records.
Taken to the extreme you can use a once coded and staged Flex template to generate pipelines of unlimited complexity based on input parameters. Well, almost unlimited - the size of the serialized graph is capped at 10MB at the time of this writing. See this FAQ answer for more information.
We created a GitHub repo containing a sample pipeline that solves this use case, Terraform scripts to create a sample environment and run a Cloud SQL instance to simulate the on-premises database. We will refer to several scripts in that repo in the discussion below.
Let’s walk through some of the nuances of building, staging and running Flex templates.
Building Flex templates
This blog describes in great details various steps involved in building and staging Flex templates. Here’s a brief summary of the process - a developer codes the pipeline, compiles the code and creates a Docker image that is deployed in Google Artifact Registry (or Container Registry). Additionally, a template specification file is created in a Google Cloud storage bucket. The template specification file has a pointer to the newly created Docker image and the metadata information about the pipeline parameters (name, type, description and validation rules). Note that no pipeline code is actually run at this point and no graph is generated; it is pure packaging of the code.
The gcloud dataflow flex-template build command is all that you need to create and stage the template in a single step. You give it the GCS location of the final template spec (first positional TEMPLATE_FILE_GCS_PATH parameter) which will include the location of the Docker image, SDK info and additional parameters.
If you don’t provide a Docker image that you built by yourself (via –image parameter) then this command will run a Cloud Build to build the image. This image will be built based on a particular Google-provided image (–flex-template-base-image, a bit more on that later), and will know that it needs to run the main method of the class provided via --env FLEX_TEMPLATE_JAVA_MAIN_CLASS parameter.
The image will be pushed into either Google Artifact Registry (GAR) or Google Container Registry (GCR), depending on the URL provided via --image-gcr-path parameter. This template building script has examples of both URLs. You need to make sure that the user or service account which deploys the template has sufficient permissions to create artifacts in the destination registry, and the worker service account needs to be able to read the registry. This Terraform script sets the permissions needed to access both registries.
The code of the pipeline is added to the Docker image via -jar parameter. Notice that you don’t have to create an Uber jar - it’s perfectly fine to have multiple -jar parameters. Our template building script generates the list of libraries to add based on the directory where Maven’s dependency plugin produced all the project runtime and compile time dependencies. If you use Gradle - this Stackoverflow thread shows how you can copy project dependencies to a folder for later use by the build script.
You can also provide several default parameters and experiments that will be passed to the Dataflow run command; that can be a good way to make sure that these parameters are always used even if forgotten to be included during the run stage.
If you plan to run your Flex template manually (using Create Job from Template/Custom Template option on the Dataflow Jobs console page) you should add the template metadata - name and description of the template, list of parameters with help text and Javascript validation rules. You can provide the metadata for a Flex template by deploying a separate file to the same GCS bucket as the template spec. But a better alternative is to use the –metadata-file parameter with the name of the file on the local system - the metadata will be embedded in the template spec. Keeping the metadata file as part of your source code, making updates to it as the pipeline changes and automatically including it in the template spec during the build process will ensure that the UI that the Dataflow console generates based on the metadata will match the current version of your pipeline.
CI/CD considerations
Your Flex template will eventually be deployed to a number of environments, e.g., integration testing, staging, production. To make your deployments stable and reproducible you will need to use certain best practices and decide on several build and deployment details.
When you create a template you need to select the base Docker image to use, which tag to use when publishing the newly created Docker image and whether to always create a new template spec or keep overwriting the existing one in GCS. To help with the decisions keep in mind that from the deployment artifact point of view a Flex template is really just two physical pieces (assuming you embedded the metadata in the template spec) - the template spec on GCS and the Docker container with all the pipeline code residing in a registry.
You might have some unique requirements in your organization, but in most cases these policies should prevent many unpleasant surprises:
When you decide on how to build and tag the generated Docker images:
Don’t use the “latest” tag of the base image or JAVA11 or PYTHON shorthand that will resolve to the “latest” tag. Use this documentation page to get the stable tag of the latest image. The resulting image path should look like this: “gcr.io/dataflow-templates-base/java11-template-launcher-base:20210419_RC00”. Treat upgrading the base images of your pipelines the same way you treat upgrading the Beam SDK or your logging framework - check for the new tag with every code release or at least with some frequency, update the base template and re-test your pipeline.
Don’t use “latest” or another fixed tag, for the Docker images that are built and deployed into the target registry (that’s the part after the colon in the --image-gcr-path parameter). This is especially important if you use the same registry to push the images during the template build phase and pull them during the launch phase. You don’t want your scheduled production pipeline to pull the latest Docker image that hasn’t been fully tested yet! Instead use a generated unique tag, e.g., a timestamp-based one. The template spec file will have a reference to that unique tag and you will never need to worry about a particular spec file pulling the wrong image.
Related to the point above - you should use some tag, otherwise the registry will automatically assign the “latest” tag with all the issues mentioned above.
What about the template spec name? It mostly depends on how you are going to launch your pipelines - referencing the same bucket used for the build or a separate bucket per environment where this pipeline is to run. There are several options, here are the most common ones:
Template spec path is unique per build, e.g., gs://my-bucket/templates/my-pipeline-<generated-timestamp>.json. You should be able to safely use a single bucket for both building templates and launching them in various environments. The process of promoting a particular version to an environment should be just updating a name of the template file to the version to be used. For example, in Cloud Composer you could store that GCS file name in an environment variable. This is the safest way to deal with pipeline versioning. It also provides for a very simple rollback mechanism - just change the pointer to the “last known good” template spec.
Template spec path is fixed, e.g., gs://my-bucket/templates/my-pipeline.json. It can be useful for initial development, but immediately after a pipeline is deployed into another environment you need to decide how to deal with versioning of the template spec. If you end up copying the spec to other buckets for other environments you can turn on GCS versioning and copy specific versions (generations in GCS parlance) of the template to the destination environment. But it will add an extra complexity to your process.
Template file is not generated in GCS at all during the template build. You can use –print-only option to output the content of the template file to standard output, capture it and store elsewhere, perhaps also in Artifact Registry, and create the GCS template spec only when needed.
Another useful thing to do is to add the template name and template version as labels to the template spec. This can be done by using –additional-user-labels parameter. Now every pipeline you start will have this information in the Job Info panel of the Dataflow UI:

This will help you with troubleshooting, especially if you tagged your code base with a template version at the build time. It is also useful for cost attribution and recurring pipeline performance comparisons - these labels will be automatically attached to the worker VMs running your pipelines (in addition to “dataflow-job-id” and “dataflow-job-name” automatically added by the Dataflow service) and will appear in Billing Exports to BigQuery.
To summarize all of these nuances, the best approach to naming, tagging and labeling various parts of Flex templates is to generate a unique tag per build, tag your code with it, use this tag as the tag for the generated Docker image, add this tag as the template version label to the template spec, and make this tag part of the image spec file name.
Launching Flex templated pipelines
There are a number of ways to run these pipelines, all of them ultimately using the underlying Dataflow API. To launch a pipeline from Cloud Composer you can use a special operator.There are also automatically generated client libraries in multiple languages that wrap this Dataflow API, e.g. for Java.
But the easiest way to do it from a machine where the gcloud SDK is installed is by using gcloud dataflow flex-template run command. Most of the parameters are standard Dataflow parameters applicable to all launch methods. If you have List or Map parameters specifying them on the command line can be a bit tricky; this page describes how to handle them. One notable parameter is “additional-user-labels”. You can provide these labels ahead of time - during the template build time or you can dynamically add them during each pipeline launch.
If you look at the console right after you launch the pipeline you will notice that your job is in “Queued” status. This status is “borrowed” from FlexRS pipelines which can be truly queued until there are enough preemptible VMs to run the pipeline. For Flex templates you can think of this status as “Launching” - the Dataflow service starts a launcher VM, pulls the Docker image found in the template specification file and runs the main() method of your pipeline with the parameters you specified. The rest is as if you were running that main() method from your development machine - the only difference is that this launcher VM is already on the same network as the worker VMs will be and uses the same service account as will be used for the worker VMs.
The launcher VM is a low end machine (you can’t control its type). The expectation is that starting the pipeline shouldn’t be computationally or memory intensive. Making a couple of API calls is perfectly fine (our sample pipeline makes a call to the Secret Manager, a JDBC’s statement.prepare() calls and reads several small configuration files from Google Cloud Storage), but don’t try to run AI model training there!
Troubleshooting the launch process
But what if something goes wrong and one of these calls fail or there are other issues launching the pipeline? You will know about it because the pipeline status will change to “Failed” and you will see an error message: “Error occurred in the launcher container: Template launch failed. See console logs.” The launcher VM’s console logs should be available in the Dataflow Log panel or Cloud Logging. Once the launch process is complete they are also copied from the launcher VM to the file listed in the very first log entry of the Dataflow job: “Console log from launcher will be available at gs://….”. To view these logs either use the console or “gsutil cat” command.
You will find the exception and the stack trace there and that’s the first step in finding out what happened. That stack trace usually points to the culprit right away (“insufficient permissions” accessing a service is a popular one).
To troubleshoot the operator errors (wrong parameters passed) find the log entry that contains “Executing: java -cp /template/* <your main class> <parameters>” and review the parameter list.
There could be cases where your pipeline doesn’t start because running the main() method causes an out-of-memory exception. You can customize the java start parameters by using the FLEX_TEMPLATE_JAVA_OPTIONS environment variable as shown in our deployment script. Again, remember that the launcher VM is not a supercomputer :-).
Conclusion
For most production environments Dataflow Flex templates are the best way to stage and deploy Dataflow pipelines. They support best security practices and provide the most flexibility in deployments.
Acknowledgments
Special thanks to several Dataflow team members—Nick Anikin (Engineering), Shan Kulandaivel (Sr Product Manager) and Mehran Nazir (Product Manager) for contributing to this post.




