Using the Open Source Insights dataset to analyze the security and compliance of your dependencies
Nicky Ringland
Product Manager
James Wetter
Software Engineer
Recent security events, like the Log4j issue, underscore the need for security teams to be vigilant in evaluating not only the code written by developers in-house, but also the open source packages that code depends on, and the code that those open source packages depend on, and so on. This web of dependencies forms a dependency graph, in which each node can introduce security vulnerabilities and other surprises. Reviewing all of these dependencies is a complex task for security teams.
Security teams generally use one of two common approaches to evaluate dependencies for vulnerabilities. With the first approach, security teams begin by researching every single dependency and its security posture at the beginning of the application development process. When a project is underway, security teams must continue to monitor and analyze any changes to the security posture of each dependency over time. This approach has drawbacks: it is very tedious and difficult for security teams to continually check each dependency. This is why security teams frequently choose the second approach, which is to rely on commercial software that evaluates security posture. Unfortunately this approach limits the control that security teams have over how to integrate dependency evaluations into the team's workflows.
Now, security teams have a new option for reviewing the security posture of dependencies! Google recently announced the Open Source Insights dataset, which was created to help developers better understand the structure and security of the software they use, and provide access to critical software supply chain information for developers, maintainers, and consumers of open-source software. The Open Source Insights project scans millions of open-source packages from the npm, Go, Maven, PyPI, and Cargo ecosystems and computes their dependency graphs. It then annotates those graphs with security advisories, license information, popularity metrics, and other metadata. Google teams are working to regularly update the dataset, specifically with information from Open Source Vulnerabilities and OpenSSF Scorecard, to make sure the data is current and relevant while also providing a snapshotted view of changes over time.
Let's get hands-on into a few different ways you can use this dataset as a security team.
Using the Open Source Insights dataset
The Open Source Insights dataset is available as part of the Google Cloud Public Dataset Program, and can be explored both using SQL in BigQuery and using the interactive UI at deps.dev. The UI is especially useful for visualizing the dependency graph, while the BigQuery option enables you to write complex, custom queries to analyze the data. This post focuses on accessing and analyzing the data in BigQuery, with example queries you can adopt and adapt along the way.
For research across the ecosystem
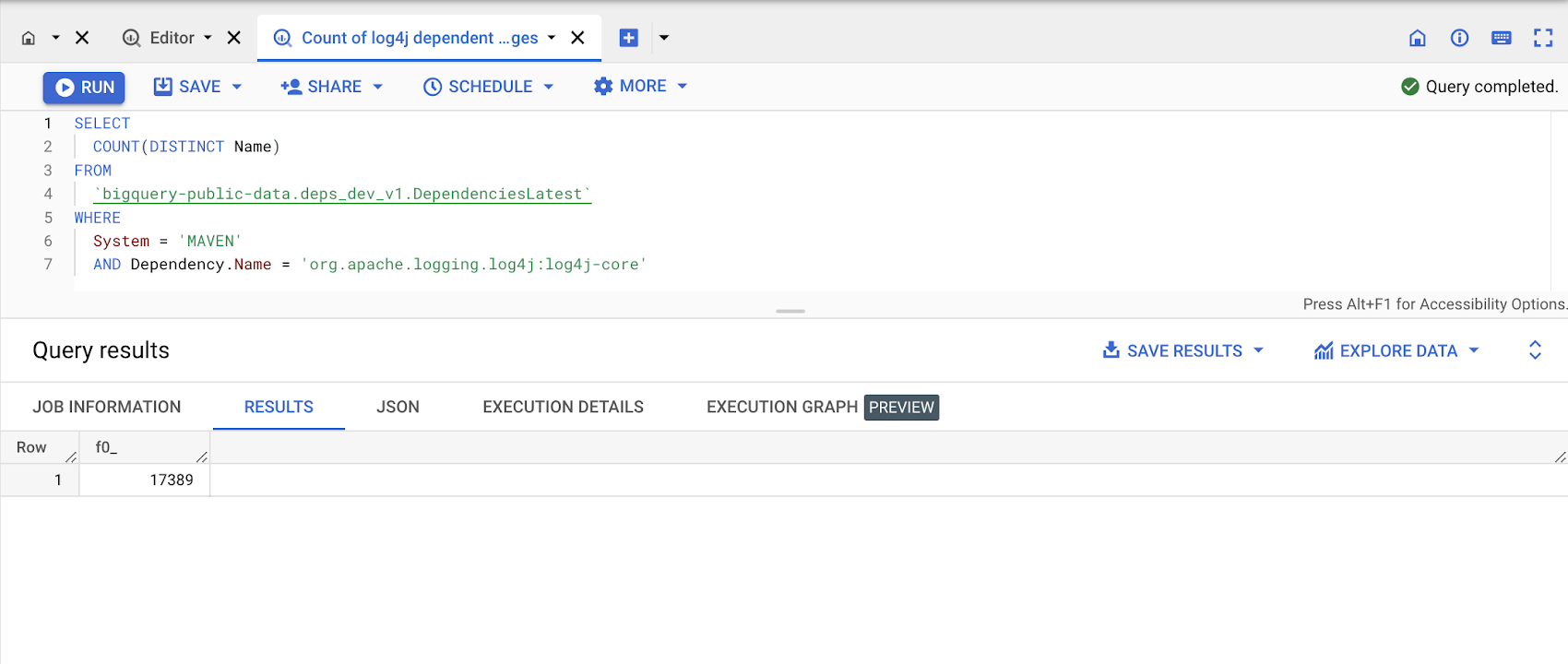
The Open Source Insights dataset can be used to research packages across your ecosystem as a whole. Going back to Log4Shell as an example, it was determined at the time of the advisory that more than 35,000 Java packages, which amounts to over 8% of the Maven Central repository, were impacted by the Log4j vulnerability. If your team wanted to research all packages that used Log4j today, you could run one query using the Open Source Insights dataset (in fact you can see it below). This query's size at over 4TB does show how complex this dataset really is and the immense work that is being done on the backend to create it. The dependencies table is 4 TB due to containing a row for every dependency of every package in npm, maven central, PyPI, Cargo, and Go.
For finding vulnerabilities and licenses that your code uses
Now let's transition from the ecosystem as a whole and zoom in on your codebase. Imagine your team is building a JavaScript application using npm, and you want to audit the dependencies to ensure that each is compliant and contains no vulnerabilities. You could take the full transitive dependencies from your lock file and query the deps.dev dataset to check the license of each one, and then look for any vulnerabilities that might be lurking in your dependency depths. This process could take days if done manually, but with automation this review can be completed much faster.
For example, the query below fetches the exact licenses for the packages REACT, REACT DOMS, REACT IS, REACT Router, QS, and SEND.
And similarly, this query finds vulnerabilities within REACT, REACT DOMS, REACT IS, REACT Router, QS, and SEND packages. Using the information from this query, security teams can tackle the most severe vulnerabilities first.
Integrate queries into a CI/CD pipeline
In addition to running queries for ad-hoc analysis, you can also operationalize the analysis and insights from these queries in your CI/CD pipeline using the BigQuery API and CLI.
Next steps
These are just a few of the many ways to use Open Source Insights dataset to understand and analyze the security posture of your codebase's dependencies.
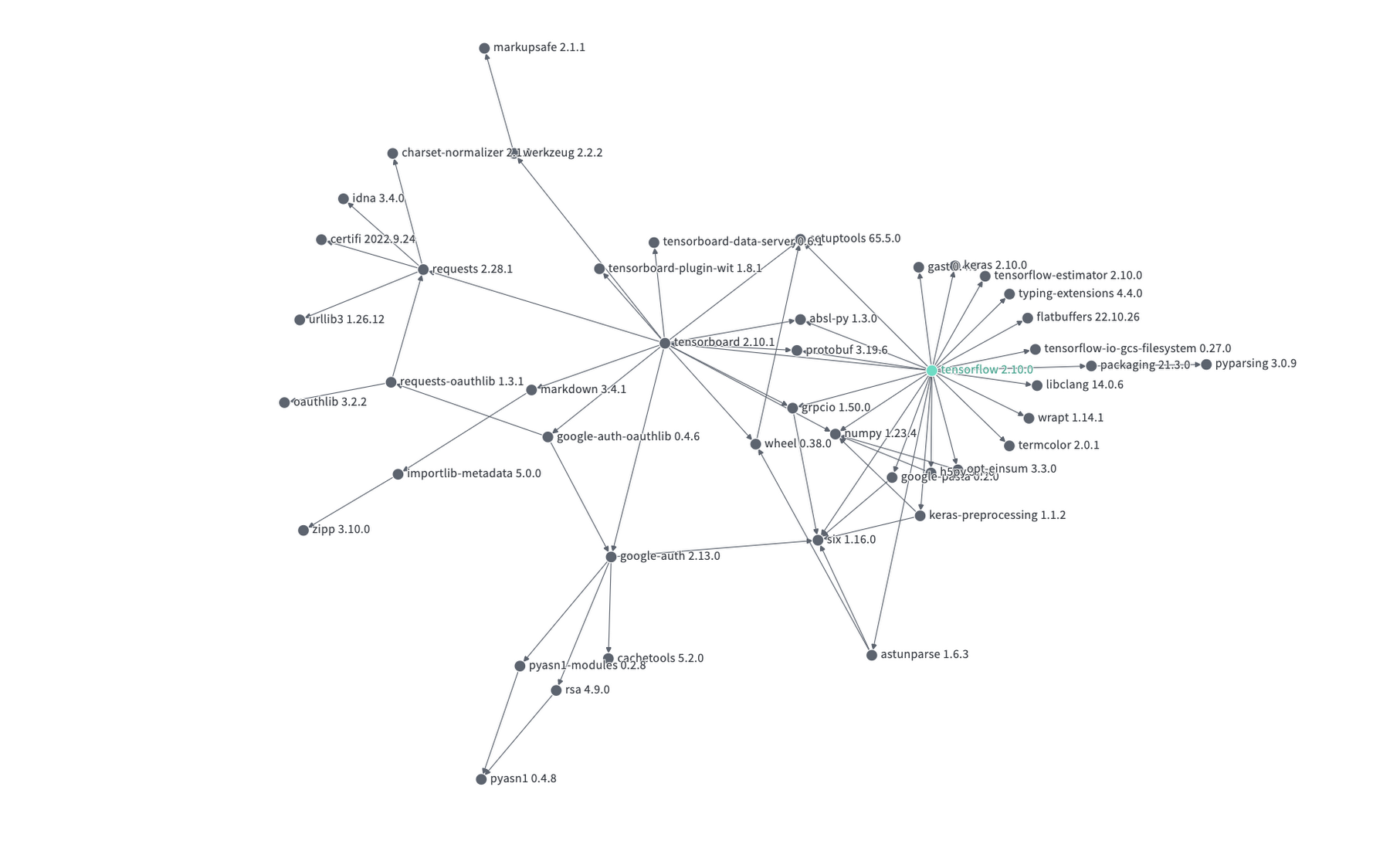
You can get started with the Open Source Insights dataset through its visual UI on deps.dev; for example, this graph showing exactly how a version of Apache Pulsar from late last year depends on log4j-core. You can also get started with the dataset by creating a BigQuery sandbox and running SQL queries on the BigQuery dataset. The BigQuery sandbox enables you to query data within the limits of the free tier without needing a credit card. If you decide to enable billing and go above the free tier threshold, you are subject to regular BigQuery pricing.
To learn more about the Open Source Insights dataset, head to the Marketplace listing and access detailed documentation at docs.deps.dev.


