Using the Cloud Spanner Emulator in CI/CD pipelines
Sneha Shah
Senior Software Engineer
Stefan Serban
Software Engineering Manager
In past posts, we have seen how to provision and manage Cloud Spanner in production environments and how to use the Cloud Spanner Emulator in your development workflow with a sample Node.js app called OmegaTrade. We’ve covered:
The Cloud Spanner emulator’s various deployment models,
Running the emulator locally with OmegaTrade, and
Running the emulator remotely with OmegaTrade
In this post, we will cover how to use the Cloud Spanner emulator in your Continuous Integration and Continuous Delivery/Deployment (CI/CD) pipelines, with sample steps covering the following tools:
As a refresher, OmegaTrade is a stock ticker visualization application that stores stock prices in Cloud Spanner and renders visualizations using Google Charts. It consists of a frontend service that renders the visualizations and a backend service that writes to and reads from the Cloud Spanner instance.
For the sake of simplicity, we focus on the backend service of the OmegaTrade application in this blog post and demonstrate how to use the Cloud Spanner emulator in CI/CD pipelines for this service.
If you’d prefer to deploy the OmegaTrade backend manually, you can learn all about how to do that by reading this blog post and focusing on the section Manual deployment steps.
CI/CD Approach for deploying OmegaTrade
The steps for all of the CI/CD tools we discuss are similar. The code is stored in a public GitHub repository, Docker files are used for creating the application docker image, Google Container Registry is used as the docker image repository and gcloud commands are used for application deployment to Cloud Run.
Please note that all of the CI/CD tools require access to a GCP Service Account (SA) as well as integration with your GitHub repository.
The main branch keeps the application code to be deployed on the dev environment where we will be deploying the Cloud Spanner emulator. Since it is using the emulator, we are calling this a dev environment.
The prod branch keeps the application code to be deployed on the prod environment where we will be deploying an actual Cloud Spanner instance.
We have two dockerfiles, one for dev (dockerfile.local.emulator) where we will be deploying the Cloud Spanner emulator, and another for prod (dockerfile.prod). dockerfile.local.emulator contains the Cloud Spanner emulator as well as the application layers (for testing purposes) whereas dockerfile.prod only contains the application code layer.
Cloud Build
To set up CI/CD with Cloud Build, please ensure the Cloud Build API is enabled from your Cloud Console as a prerequisite. The first step is to connect our GitHub repository with Cloud Build for automated deployment of our application over Cloud Run.
From the Connect Repository option in the Cloud Build Triggers screen, select the source as GitHub (Cloud Build GitHub App), authenticate, select GitHub Account and Repository.
In the backend, Cloud Build will install the Cloud Build app in your GitHub repository. You can find Cloud Build in Repo Settings ➞ Integrations. This app will monitor your repository and trigger pipeline processing upon any commit or push to whichever branch you mention in the trigger. Cloud Build allows folder-specific triggers.
For this blog, we are going to create 2 triggers, one dedicated to dev deployment and another to prod. The Dev deployment will be communicating with the Spanner emulator whereas Prod one will be communicating with an actual Cloud Spanner instance.
Create Google Cloud Build Triggers
We are using the Cloud Build.yaml file (build config file) for the deployment. A build config file defines the fields that are needed for Cloud Build to perform your tasks. We can create either a .yml or .json file for Cloud Build where we write instructions for our CI/CD pipeline.
The Cloud Build config is purely parameterized which means we are using the same build config file for our frontend as well as backend deployment and providing values while creating triggers in the GCP UI.
The substitution_option: 'ALLOW_LOOSE' allows Cloud Build triggers to run despite any missing substitution variable. We are using this option because we need some extra values for backend deployment. In this case, Cloud Build won’t return any errors.
To set up the backend trigger, follow the below steps:
From Cloud Build ➞ Create Trigger, enter a unique name, description for the trigger
Select Event as Push to a branch
Choose GitHub repo in Source
Enter ^main$ under Branch
Enter backend/** in the Included files filter (this option triggers a backend trigger when there is any change(s) in the folder)
Enter Cloud Build.yaml in Build Configuration.
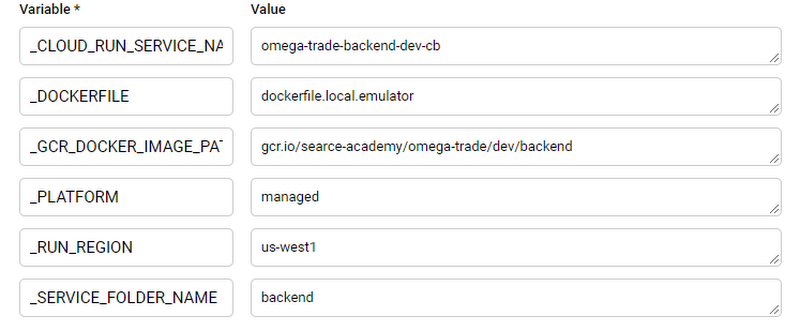
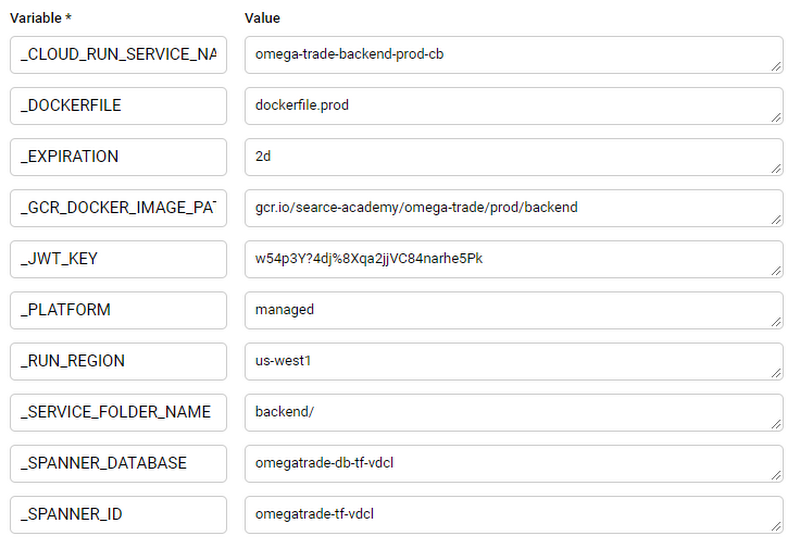
Similarly, create one for prod deployment with ^prod$ under Branch and substitute the rest of the fields with actual Cloud Spanner instance values.
Here is a video walkthrough of the configuration steps for Cloud Build:
Jenkins
Prerequisites:
Basic Knowledge of Jenkins
Jenkins must be installed and setup
To set up Jenkins CI/CD, we are using the Jenkins Multibranch Pipeline, which allows for creating and triggering pipelines based on branch and pull requests. For this blog post, we are going to create 2 branches: dev and prod. Dev app code will be communicating with the Spanner emulator hosted on Google Compute Engine whereas the Prod one would be communicating with an actual Cloud Spanner instance.
Create service accounts in GCP
After installing Jenkins on GKE, we need to create a service account (SA) in GCP. After creating the SA, we’ll need to give it the correct permissions.
For this blog, we’ve given wide scope permission — admin, but in your environment, you may want to follow the Principle of Least Privilege.
Once done, create an SA key, as we’re going to need it later.

Now let’s create one secret — kaniko-secret in Kubernetes with the kaniko service account key. kaniko is a tool to build container images from a Dockerfile, inside a container or Kubernetes cluster.
For this, we’re using a cloud shell, so before applying the commands we have to upload key.json here.
Connect Jenkins with GitHub
Integrating Jenkins with GitHub keeps your project updated. With this, your Jenkins build will automatically schedule when there is any new push/commit to the branch by pulling the code and data files from GitHub to Jenkins.
To do this, add a webhook from the settings option of your repo. Enter the Jenkins URL, append /github-webhook/, and choose application/json in the content type.
Select from which events you would like to trigger this webhook
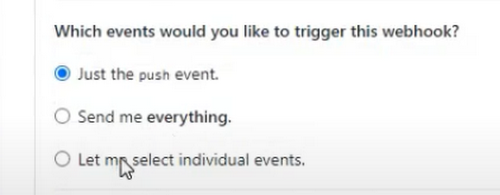
For instance, you can go with the 3rd option — Let me select individual events, and then allow Push and Pull Requests.
Upon saving you will see a green check, which means the first (testing) delivery is successful.
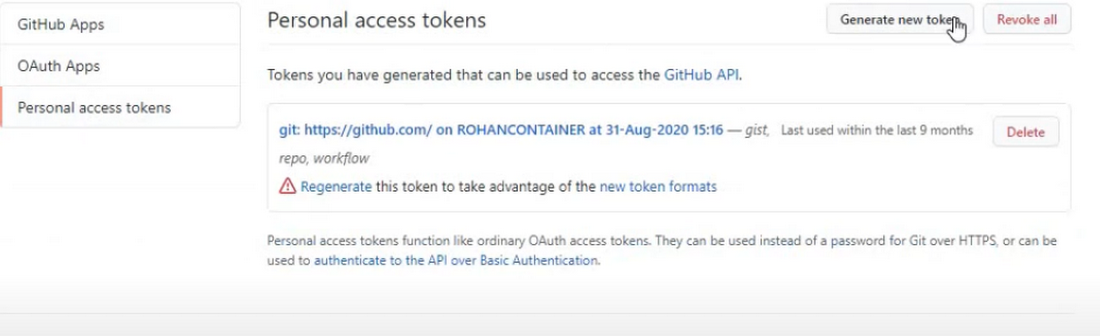
Create a GitHub Personal Access Token
A GitHub Personal access token is a good alternative to using passwords for authentication to GitHub when using the GitHub API or the command line. Generate one from your GitHub profile settings➞Developer Settings➞Personal Access Tokens with all necessary permission that you want to give to this token. Copy the token value.
Add Credentials
Credentials allow Jenkins to interact with 3rd party services or tools like Docker Container Registry in an authorized manner. Jenkins stores credentials in encrypted form on the master Jenkins instance (encrypted by the Jenkins instance ID) and the credentials are only handled in Pipeline projects via their credential IDs.
Here we'll be adding the kaniko-executor-sa key (created above) in Jenkins, which allows Jenkins to communicate with GCR.
From the admin option on the top left, go to Credentials➞Stores from parent(in right)➞Global credentials (unrestricted)➞Add Credentials.
Select Secret File from Kind and upload the file.

Create one Secret with username and password where the username will be your GitHub username and the password will be the Access Token that you copied above.
Install Plugins
We’ll be installing some plugins that help make the multibranch pipeline experience smoother.
From Manage Plugins in Manage Jenkins, install:
Create Multibranch Pipeline
To create a multibranch pipeline, go to New Item➞Multibranch Pipeline. Enter the item name, the display name, and the description.
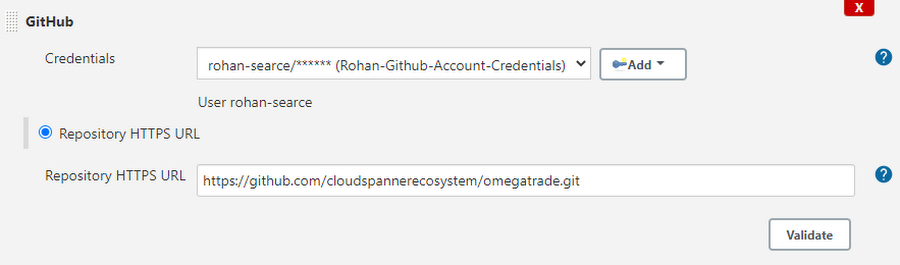
Choose GitHub from Branch Source, select GitHub Personal Access Token that you’ve created before, enter the GitHub repo name, and hit validate. It should show Credentials OK.
From Behaviors, you may want to select the following:
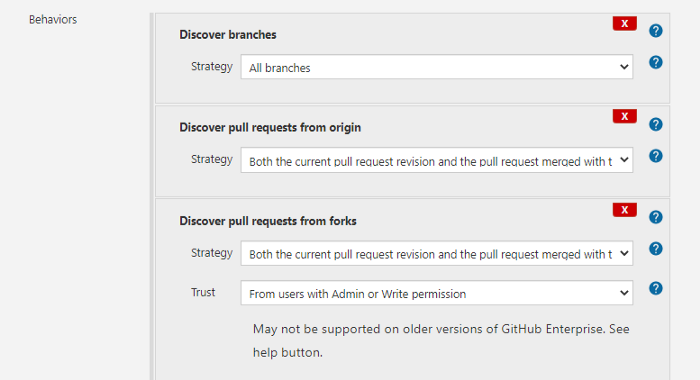
You can select other available options based on your trigger requirements. The options mentioned above tend to help improve discoverability.
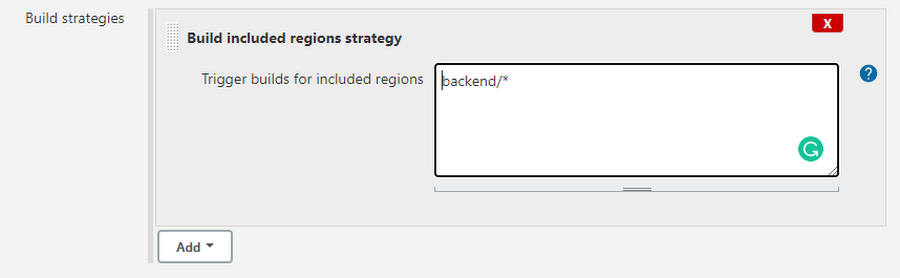
From Build Strategies, choose Trigger builds for included regions.
Build Strategies
This feature is based on the Pipeline: Multibranch build strategy extension plugin. Without it, you won’t be able to create GitHub folder-based triggers.
If you have the code for more than one service in a single repo, then creating a repo-based trigger is not recommended, because all the pipelines will get triggered by any change in the repo. With this plugin, however, you can specify folders from which a build will occur. Like in the above example, this particular pipeline will only get triggered when there is a change in the specific folder.
Under Build Configuration, enter the Jenkinsfile path
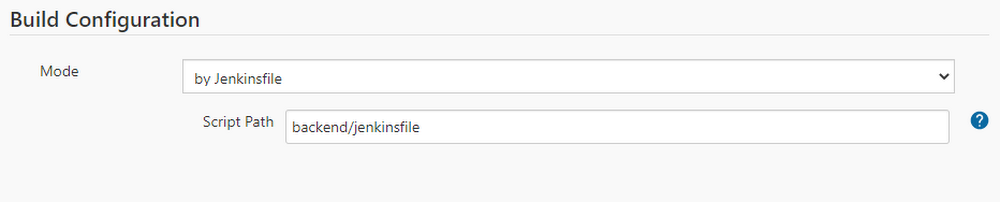
Leave the rest of the options as it is and hit Save. As you save it, Jenkins will scan the repository and display logs. Once it is done, Jenkins will start building and deploying the app over GCP Cloud Run.
Here is a video walkthrough of the configuration steps for Jenkins:
GitHub Actions
With GitHub Actions, we create workflows. Here we’ll be creating 2 workflows, one dedicated to dev and another one to prod. The Dev deployment will be communicating to the Spanner emulator whereas the Prod one will talk to the actual Cloud Spanner instance.
First, we have to set up some secrets in GitHub which will be used by GitHub Actions during deployments.
To create a multibranch pipeline, go to Setting➞Secrets.
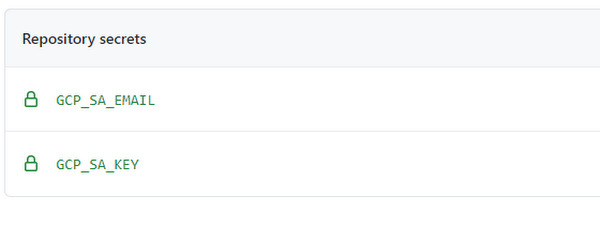
We need to create 2 secrets here. One secret for GCP Service Account email would be used for deployments and another secret would be for the associated Service Account key. To generate your Service Account key from the GCP Console, Go to Service Account➞Choose your SA and from 3 vertical dots, Create Key.
Here, the first secret, i.e. GCP_SA_EMAIL is the Service Account email and the second one, i.e GCP_SA_KEY is the Service Account key we generated.
Refer to the screenshots below.
From the GitHub repo, go to Actions, where you will find the pre-created workflows. Choose any of them, clear all the code from there, paste the Workflow code and name the file. As you commit that, you will see a .github/workflows folder appear in the GitHub repository.
From Actions, you can see your pipeline running and working.
The GitHub Actions workflows are branch and folder-specific as we have mentioned the keywords push for branch and working-directory for folder. The commit needs to satisfy these 2 things to run a specific workflow.
We are using previously created GitHub Actions for configuring the Google Cloud SDK in the GitHub Actions environment and here we are passing Service account and SA keys for authorization. Once authorization is done, we are building, tagging, and pushing docker images to GCR and deploying applications over Cloud Run.
This workflow pipeline will run on GitHub hosted infrastructure with the latest Ubuntu version as an underlying OS.
Here is a video walkthrough of the configuration steps for GitHub Actions:

CircleCI
For CircleCI integration, you need to have an account on CircleCI and add your GitHub Repository as a project in CircleCI. Once this is done, CircleCI will take care of deployments of your app on GCP Cloud Run.
Once you add a project, CircleCI will ask you to write and commit config.yml to your GitHub repository. There are templates already present for different languages and frameworks. You can ignore these right now and follow the CircleCI Pipeline Code. You can just paste it and commit it.
This pipeline has 2 jobs, one for dockerizing and deploying apps in the dev environment, and another one for the prod environment. The pipeline for the Dev environment will run when there is a change or commit in the main branch whereas the one for the prod environment will run when there is a change or commit in the prod branch.
To allow CircleCI to deploy apps to GCP, we have to add the GCP Service Account in the CircleCI Environment variables which will be passed each time the CircleCI pipeline runs. From Projects➞Your Project➞Projects Settings (on the top right)➞Environment Variables. Click add Environment Variables and add the Service Account Key.
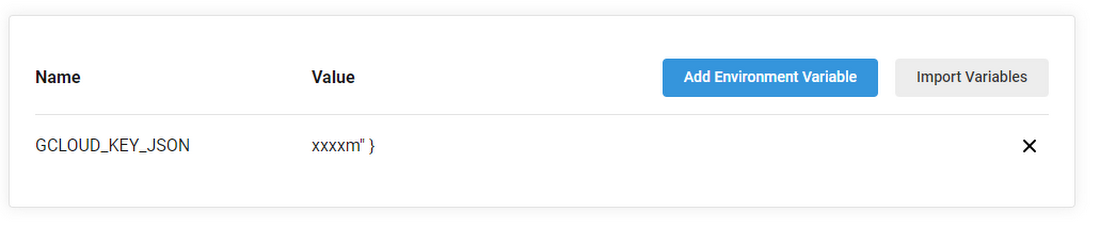
Once this is done, CircleCI will deploy your app over GCP Cloud Run.
Below is a video walkthrough of the configuration steps for CircleCI:

Conclusion
In this blog post, we have shown how to deploy the backend service of the OmegaTrade app with the Cloud Spanner emulator in 4 different CI/CD pipelines:
We’ve also briefly covered deploying to production. Note that if you’re setting up a Development environment, you may wish to consider using the emulator for your testing/validation needs. This blog post has more details on how you can set that up (locally or remotely).
To learn more about Cloud Spanner, visit the product page. To learn more about the Cloud Spanner emulator, take a look at the official documentation.




