Stateful serverless on Google Cloud with Cloudstate and Akka Serverless
James Ward
Developer Advocate at Google Cloud
Viktor Klang
Head of Cloud Engineering and Deputy CTO at Lightbend
In recent years, stateless middle-tiers have been touted as a simple way to achieve horizontal scalability. But the rise of microservices has pushed the limits of the stateless architectural pattern, causing developers to look for alternatives.
Stateless middle-tiers have been a preferred architectural pattern because they helped with horizontal scaling by alleviating the need for server affinity (aka sticky sessions). Server affinity made it easy to hold data in the middle-tier for low-latency access and easy cache invalidation. The stateless model pushed all "state" out of the middle-tier into backing data stores. In reality the stateless pattern just moved complexity and bottlenecks to that backing data tier. The growth of microservice architectures exacerbated the problem by putting more pressure on the middle tier, since technically, microservices should only talk to other services and not share data tiers. All manners of bailing wire and duct tape have been employed to overcome the challenges introduced by these patterns. New patterns are now emerging which fundamentally change how we compose a system from many services running on many machines.
To take an example, imagine you have a fraud detection system. Traditionally the transactions would be stored in a gigantic database and the only way to perform some analysis on the data would be to periodically query the database, pull the necessary records into an application, and perform the analysis. But these systems do not partition or scale easily. Also, they lack the ability for real-time analysis. So architectures shifted to more of an event-driven approach where transactions were put onto a bus where a scalable fleet of event-consuming nodes could pull them off. This approach makes partitioning easier, but it still relies on gigantic databases that received a lot of queries. Thus, event-driven architectures often ran into challenges with multiple systems consuming the same events but at different rates.
Another (we think better) approach, is to build an event-driven system that co-locates partitioned data in the application tier, while backing the event log in a durable external store. To take our fraud detection example, this means a consumer can receive transactions for a given customer, keep those transactions in memory for as long as needed, and perform real-time analysis without having to perform an external query. Each consumer instance receives a subset of commands (i.e., add a transaction) and maintains its own "query" / projection of the accumulated state. For instance:
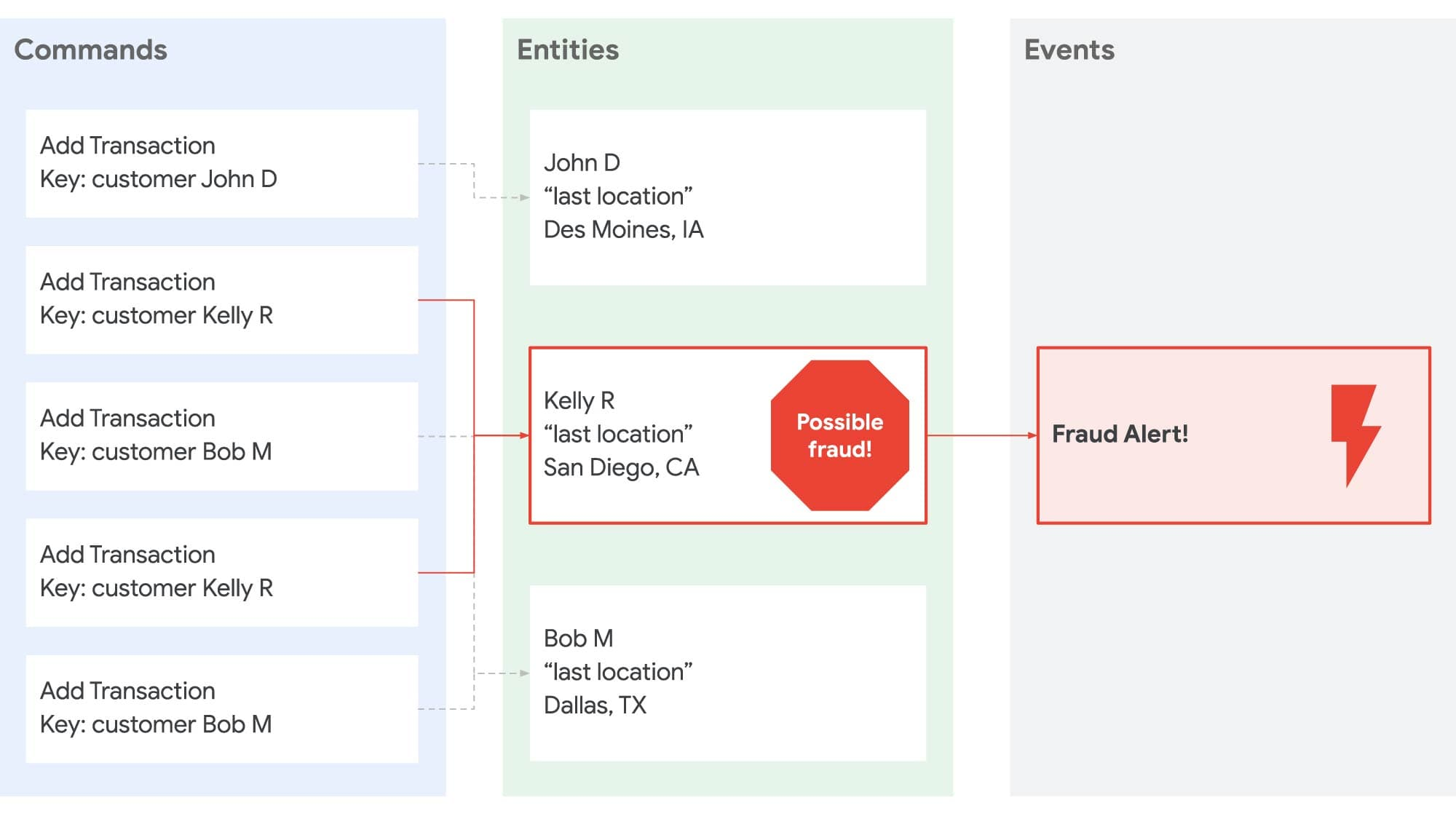
By separating commands and queries we can easily achieve end-to-end horizontal scaling, fault tolerance, and microservice decoupling. And with the data being partitioned in the application tier we can easily scale that tier up and down based on the number of events or size of data, achieving serverless operations.
Making it work with Cloudstate
This architecture is not entirely uncommon, going by the names Event Sourcing, Command Query Response Segregation (CQRS), and Conflict-Free Replicated Data Types. (Note: for a great overview of this see a presentation titled "Cloudstate - Towards Stateful Serverless" by Jonas Bonér.) But until now, it’s been pretty cumbersome to build systems with these architectures due to primitive programming and operational models. The new Cloudstate open-source project attempts to change that by building more approachable programming and operational models.
Cloudstate's programming model is built on top of protocol buffers (protobufs) which enable evolvable data schemas and generated service interaction stubs. When it comes to data schemas, protobufs allow you to add fields to event / message objects without breaking systems that are still using older versions of those objects. Likewise, with the gRPC project, protobufs can be automatically wrapped with client and server "stubs" so that no code needs to be written for handling protobuf-based network communication. For example, in the fraud detection system, the protobuf might be:
The `Transaction` message contains the details about a transaction and the `user_id` field enables automatic sharding of data based on the user.
Cloudstate adds support for event sourcing on top of this foundation so developers can focus on just the commands and accumulated state that a given component needs. For our fraud detection example, we can simply define a class / entity to hold the distributed state and handle each new transaction. You can use any language, but we use Kotlin, a Google-sponsored language that extends Java.
With the exception of a tiny bit of bootstrapping code, that’s all you need to build an event-sourced system with Cloudstate!
The operational model is also just as delightful since it is built on Kubernetes and Knative. First you need to containerize the service. For JVM-based builds (Maven, Gradle, etc.) you can do this with Jib. In our example we use Gradle and can just run:
This creates a container image for the service and stores it on the Google Container Registry. To run the Cloudstate service on your own Kubernetes / Google Kubernetes Engine (GKE) cluster, you can use the Cloudstate operator and a deployment descriptor such as:
There you have it—a scalable, distributed event-sourced service!
And if you'd rather not manage your own Kubernetes cluster, then you can also run your Cloudstate service in the Akka Serverless managed environment, provided by Lightbend, the company behind Cloudstate.
To deploy the Cloudstate service on Lightbend Cloudstate simply run:
It's that easy! Here is a video that walks through the full fraud detection sample:

You can find the source for the sample on GitHub: github.com/jamesward/cloudstate-sample-fraud
Akka Serverless under the hood
As an added bonus, Akka Serverless itself is built on Google Cloud. To deliver this stateful serverless cloud service on Google Cloud, Cloudstate needs a distributed durable store for messages. With the open-source Cloudstate you can use PostgreSQL or Apache Cassandra. The managed Akka Serverless service is built on Google Cloud Spanner due to its global scale and high throughput. Lightbend also chose to build their workload execution on GKE to take advantage of its autoscaling and security features.
Together, Lightbend and Google Cloud have many shared customers who have built modern, resilient, and scalable systems with Lightbend's open source and Google's Cloud services. So we are excited that Cloudstate brings together Lightbend and Google Cloud and we look forward to seeing what you will build with it! To get started check out the Open Source Cloudstate project and Lightbend’s Akka Serverless managed cloud service.