Give your agentic chatbots a fast and reliable long-term memory
Aishwarya Prabhat
Solutions Acceleration Architect, Google Forge, Google Cloud
Yun Pang
Principal Architect
When scaling conversational agents, the data layer design often determines success or failure. To support millions of users, agents need conversational continuity — the ability to maintain responsive chats while preserving the context backend models need.
This article covers how to use Google Cloud solutions to solve two data challenges in AI: fast context updates for real-time chat, and efficient retrieval for long-term history. We’ll share a polyglot approach using Redis, Bigtable, and BigQuery that ensures your agent retains detail and continuity, from recent interactions to months-old archives.
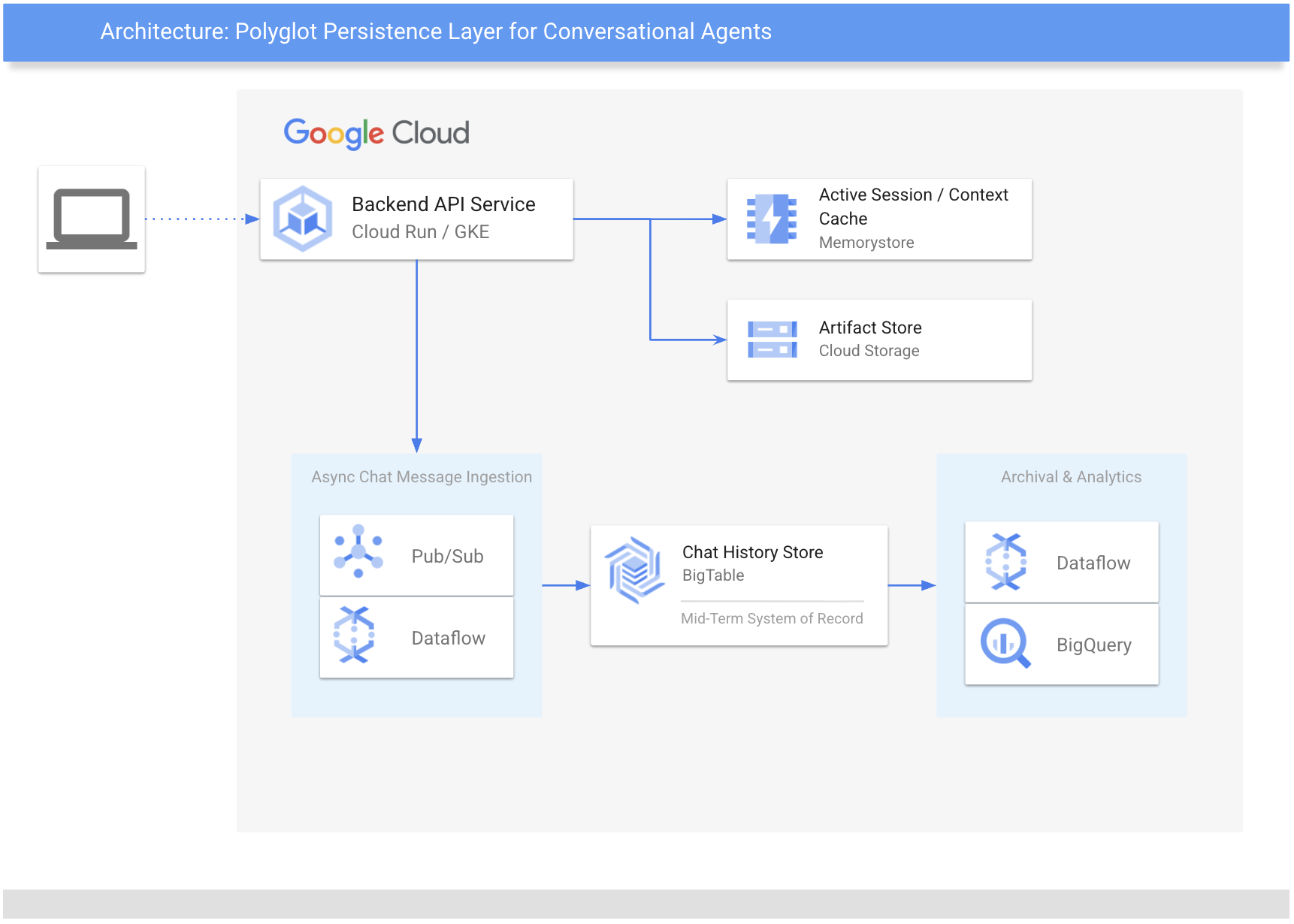
Polyglot storage approach for short, mid, and long-term history
What is a polyglot approach?
A polyglot approach uses a multi-tiered storage strategy that leverages several specialized data services rather than a single database to manage different data lifecycles. This allows an application to use the specific strengths of various tools—such as in-memory caches for speed, NoSQL databases for scale, blob storage for unstructured artifacts, and data warehousing for analytics—to handle the "temperature" and volume of data effectively.
Define a polyglot approach on Google Cloud for short, mid, and long-term memory
To maintain conversational continuity, you can implement this polyglot approach using Memorystore for Redis for sub-millisecond "hot" context retrieval, Cloud Bigtable as a petabyte-scale system of record for durable history, and BigQuery for long-term archival and analytical insights, with Cloud Storage handling unstructured multimedia and an asynchronous pipeline built using Pub/Sub and Dataflow.
1. Short-term memory: Memorystore for Redis
Users expect chat histories to load instantaneously, whether they are initiating a new chat or continuing a previous conversation. For context of a conversation, Memorystore for Redis serves as the primary cache. As a fully managed in-memory data store, it provides the sub-millisecond latency required to maintain a natural conversational flow. Since chat sessions are incrementally growing lists of messages, we store history using Redis Lists. By using the native RPUSH command, the application transmits only the newest message, avoiding the network-heavy "read-modify-write" cycles found in simpler stores like Memcached.
2. Mid-term memory: Cloud Bigtable
As the conversation grows over time, the agentic applications need to account for larger and longer term storage of a growing chat history. This is where Bigtable acts as the durable mid-term store and the definitive system of record for all chat history. Bigtable is a petabyte-scale NoSQL database designed specifically for high-velocity, write-heavy workloads, making it perfect for capturing millions of simultaneous chat interactions. While it handles massive data volumes, teams can keep the active cluster lean by implementing garbage collection policies — retaining, for example, only the last 60 days of data in the high-performance tier. To make lookups fast, we use a key strategy with a user_id#session_id#reverse_timestamp pattern. This co-locates all messages from a single session, allowing for efficient range scans to retrieve the most recent messages for history reloads.
3. Long-term memory and analytics: BigQuery
For archival and analytics, data moves to BigQuery, representing the long-term memory of the system. While Bigtable is optimized for serving the live application, BigQuery is Google's premier serverless data warehouse designed for complex SQL queries at scale. This allows teams to go beyond simple logging and derive analytical insights. Ultimately, this operational data becomes a feedback loop for improving the agent and user experience without impacting the performance of the user-facing components.
4. Artifact storage: Cloud Storage (GCS)
Unstructured data such as multimedia files — whether uploaded by a user for analysis or generated by a generative model — live in Cloud Storage, which is purpose built for unstructured artifacts. We utilize a pointer strategy where Redis and Bigtable records contain a URI pointer (e.g., gs://bucket/file) to the object. To maintain security, the application serves these files using signed URLs, providing the client with time-limited access without exposing the bucket publicly.
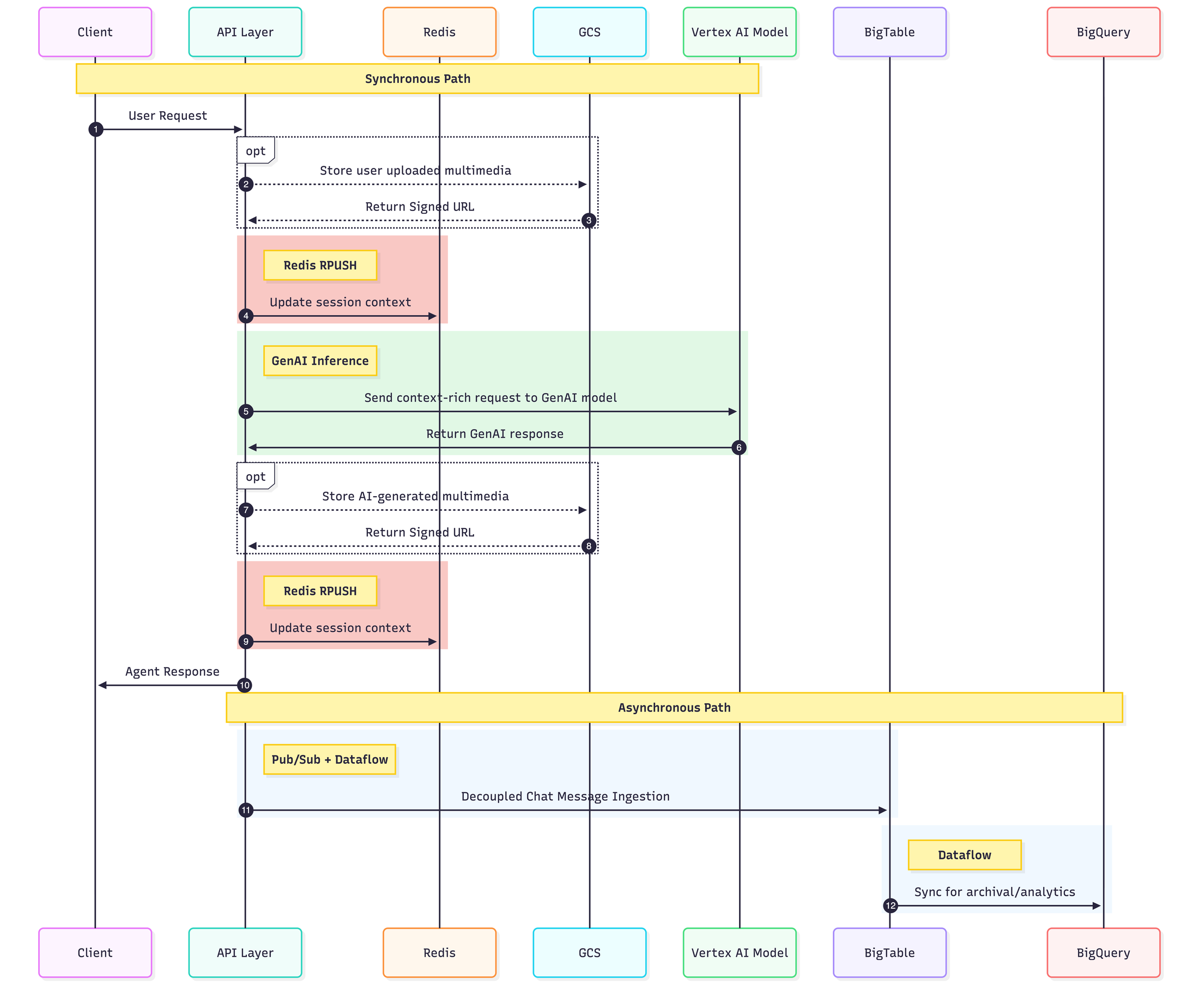
A hybrid sync-async strategy for optimal flow of data
As shown in the sequence diagrams below, the hybrid sync-async strategy utilizes the abovementioned storage solutions to balance high-speed consistency with durable data persistence.
The diagram below shows how a user message and corresponding agent response traverse through the architecture:
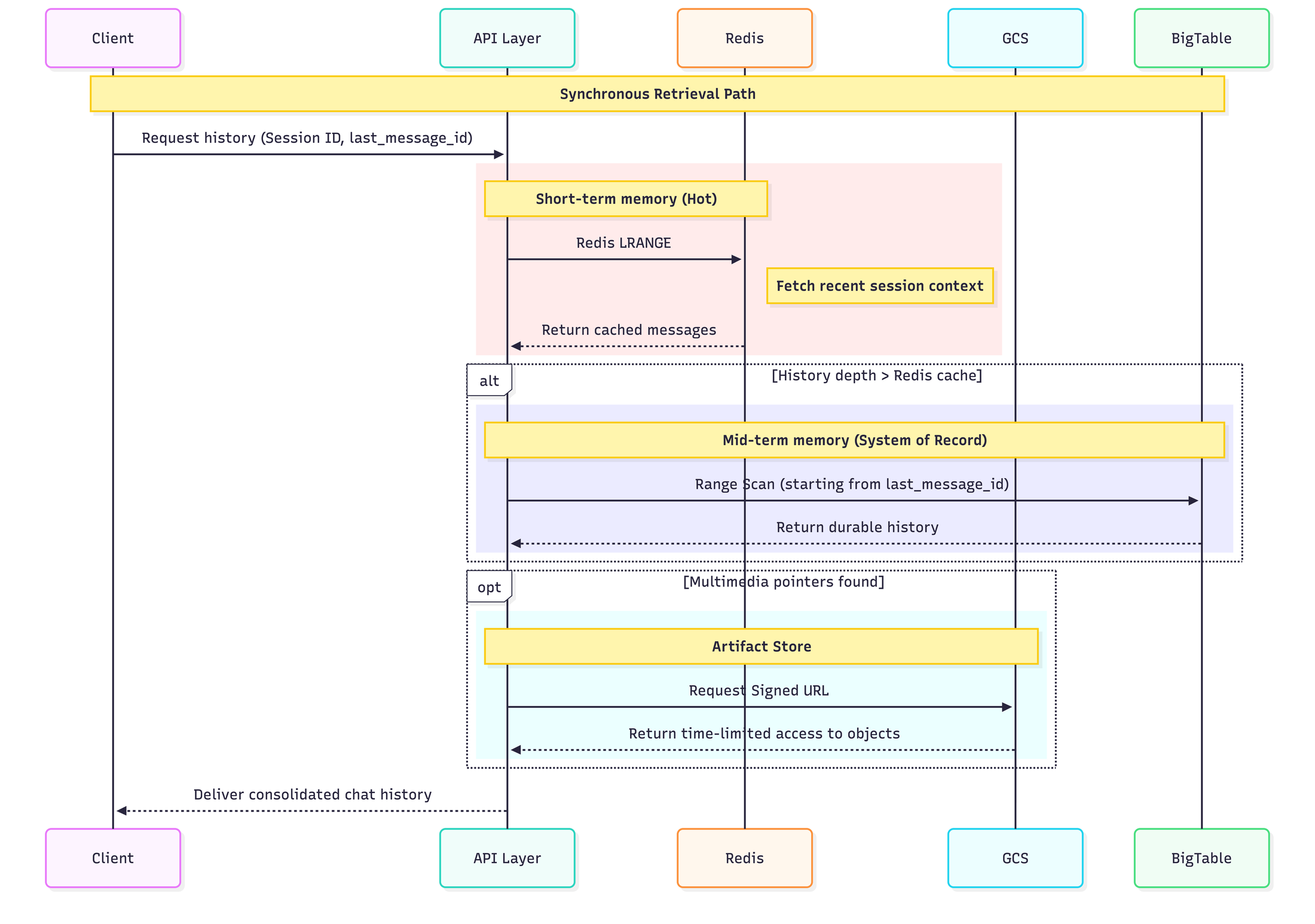
The diagram below shows how data flows across the architecture when a user decides to retrieve chat history for a particular session:
Start building now
Ready to build an agent with a robust persistence layer?
-
Build agents quickly: Start prototyping your agentic workflows on Vertex AI Agent Builder.
-
Configure your cache: Determine which Memorystore for Redis configuration best suits your latency and availability needs.
-
Design a robust BigTable schema: Review the schema design best practices.
-
Bridge to analytics: Use the Bigtable change stream to BigQuery template to ready your live chat logs for actionable business insights.
- Bring data to life with analytics: Use Looker Conversational Analytics to drive product decisions through business intelligence.



