Extend your Dataflow template with UDFs

Roy Arsan
Cloud Solutions Architect, Google
Google provides a set of Dataflow templates that customers commonly use for frequent data tasks, but also as reference data pipelines that developers can extend. But what if you want to customize a Dataflow template without modifying or maintaining the Dataflow template code itself? With user-defined functions (UDFs), customers can extend certain Dataflow templates with their custom logic to transform records on the fly:
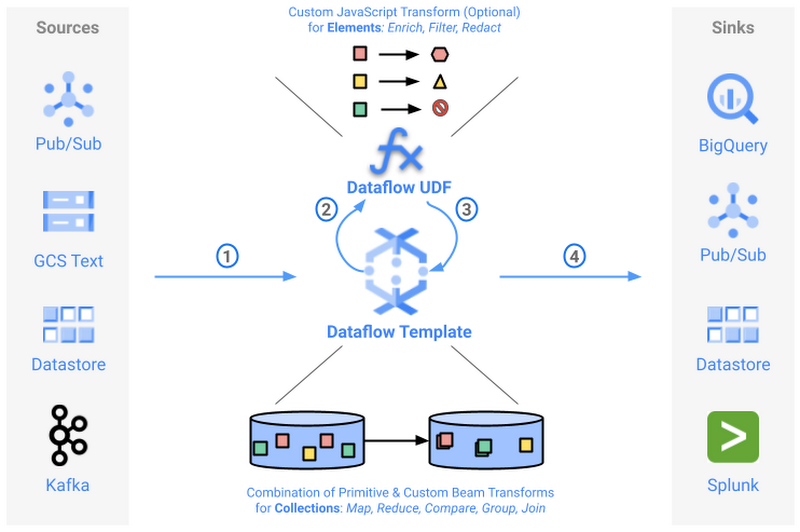
A UDF is a JavaScript snippet that implements a simple element processing logic, and is provided as an input parameter to the Dataflow pipeline. This is especially helpful for users who want to customize the pipeline’s output format without having to re-compile or to maintain the template code itself. Example use cases include enriching records with additional fields, redacting some sensitive fields, or filtering out undesired records - we’ll dive into each of those. That means you do not have to be an Apache Beam developer or even have a developer environment setup in order to tweak the output of these Dataflow templates!
At the time of writing, the following Google-provided Dataflow templates support UDF:
GCS Text to BigQuery (Batch and Stream)
Note: While the UDF concepts described here apply to any Dataflow template that supports UDF, the utility UDF samples below are from real-world use cases using the Pub/Sub to Splunk Dataflow template, but you can re-use those as starting point for this or other Dataflow templates.
How UDF works with templates
When a UDF is provided, the UDF JavaScript code runs on Nashorn JavaScript engine included in the Dataflow worker’s Java runtime (applicable for Java pipelines such as Google-provided Dataflow templates). The code is invoked locally by a Dataflow worker for each element separately. Element payloads are serialized and passed as JSON strings back and forth.
Here’s the format of a Dataflow UDF function called process which you can reuse and insert your own custom transformation logic into:
Using JavaScript’s standard built-in JSON object, the UDF first parses the stringified element inJson into a variable obj, and, at the end, it must return a stringified version outJson of the modified element obj. Where highlighted, you add your custom element transformation logic depending on your use case. In the next section, we provide you with utility UDF samples from real-world use cases.
Note: The variable includePubsubMessage is required if the UDF is applied to Pub/Sub to Splunk Dataflow template since it supports two possible element formats: that specific template can be configured to process the full Pub/Sub message payload or only the underlying Pub/Sub message data payload (default behavior). The statement setting data variable is needed to normalize the UDF input payload in order to simplify your subsequent transformation logic in the UDF, consistent with the examples below. For more context, see includePubsubMessage parameter in Pub/Sub to Splunk template documentation.
Common UDF patterns
The following code snippets are example transformation logic to be inserted in the above UDF process function. They are grouped below by common patterns.
Pattern 1: Enrich events
Follow this pattern to enrich events with new fields for more contextual information.
- Example 1.1:
Add a new field as metadata to track pipeline’s input Pub/Sub subscription
- Example 1.2*:
Set Splunk HEC metadata source field to track pipeline’s input Pub/Sub subscription
- Example 1.3:
Add new fields based on a user-defined local function e.g.
callerToAppIdLookup()acting as a static mapping or lookup table
Pattern 2: Transform events
Follow this pattern to transform the entire event format depending on what your destination expects.
- Example 2.1:
Revert logs from Cloud Logging log payload (LogEntry) to original raw log string. You may use this pattern with VM application or system logs (e.g. syslog or Windows Event Logs) to send source raw logs (instead of JSON payloads):
- Example 2.2*:
Transform logs from Cloud Logging log payload (LogEntry) to original raw log string by setting Splunk HEC event metadata. Use this pattern with application or VM logs (e.g. syslog or Windows Event Logs) to index original raw logs (instead of JSON payload) for compatibility with downstream analytics. This example also enriches logs by setting HEC fields metadata to incoming resource labels metadata:
Pattern 3: Redact events

Follow this pattern to redact or remove a part of the event.
- Example 3.1:
Delete or redact sensitive SQL query field from BigQuery AuditData data access logs:
Pattern 4: Route events
Follow this pattern to programmatically route events to separate destinations.
- Example 4.1*:
Route event to the correct Splunk index per used-defined local function e.g.
splunkIndexLookup()acting as a static mapping or lookup table:
- Example 4.2:
Route unrecognized or unsupported events to Pub/Sub deadletter topic (if configured) in order to avoid invalid data or unnecessary consumption of downstream sinks such as BigQuery or Splunk:
Pattern 5: Filter events

Follow this pattern to filter out undesired or unrecognized events.
- Example 5.1:
Drop events from a particular resource type or log type, e.g. filter out verbose Dataflow operational logs such as worker & system logs:
- Example 5.2:
Drop events from a particular log type, e.g. Cloud Run application stdout:
* Example applicable to Pub/Sub to Splunk Dataflow template only
Testing UDFs
Besides ensuring functional correctness, you must verify your UDF code is syntactically correct JavaScript on Oracle Nashorn JavaScript engine which is shipped as part of JDK (8 through 14) pre-installed in Dataflow workers. That’s where your UDF ultimately runs. Before pipeline deployment, it is highly recommended to test your UDF on Nashorn engine: any JavaScript syntax error will throw an exception, potentially on every message. This will cause a pipeline outage as the UDF is unable to process those messages in-flight.
At the time of this writing, Google-provided Dataflow templates run on JDK 11 environment with the corresponding Nashorn engine v11 release. By default, Nashorn engine is only ECMAScript 5.1 (ES5) compliant so a lot of newer ES6 JavaScript keywords like let or const will cause syntax errors. In addition, it’s important to note that Nashorn engine is a slightly different JavaScript implementation than Node.js. A common pitfall is using console.log() or Number.isNaN() for example, neither of which are defined in the Nashorn engine. For more details, see this introduction to using Oracle Nashorn. That said, using the utility UDFs provided above without major code changes should be sufficient for most use cases.
An easy way to test your UDF on Nashorn engine is by launching Cloud Shell where JDK 11 is pre-installed, including jjs command-line tool to invoke Nashorn engine.
Let’s assume your UDF is saved in dataflow_udf_transform.js JavaScript file and that you’re using UDF example 1.1 above which appends new inputSubscription field.
In Cloud Shell, you can launch Nashorn in interactive mode as follows:
In Nashorn interactive shell, first load your UDF JavaScript file which will load the UDF ‘process’ function in global scope:
To test your UDF, define an arbitrary input JSON object depending on your pipeline’s expected in-flight messages. In this example, we’re using a snippet of a Dataflow job log message to be processed by our pipeline:
You can now invoke your UDF function to process that input object as follows:
Notice how the input object is serialized first before being passed to UDF which expects an input string as noted in the previous section.
Print the UDF output to view the transformed log with the appended inputSubscription field as expected:
Finally exit the interactive shell:
Deploying UDFs

You deploy a UDF when you run a Dataflow job by referencing a GCS file containing the UDF JavaScript file. Here’s an example using gcloud CLI to run a job using the Pub/Sub to Splunk Dataflow template:
The relevant parameters to configure:
gcs-location: GCS location path to the Dataflow templatejavascriptTextTransformGcsPath: GCS location path to JavaScript file with your UDF codejavascriptTextTransformFunctionName: Name of JavaScript function to call as your UDF
As a Dataflow user or operator, you simply reference a pre-existing template URL (Google-hosted), and your custom UDF (Customer-hosted) without the requirement to have a Beam developer environment setup or to maintain the template code itself.
Note: The Dataflow worker service account used must have access to the GCS object (JavaScript file) containing your UDF function. Refer to Dataflow user docs to learn more about Dataflow worker service account.
What’s Next?
We hope this helps you get started with customizing some of the off-the-shelf Google-provided Dataflow templates using one of the above utility UDFs or writing your own UDF function. As a technical artifact of your pipeline deployment, the UDF is a component of your infrastructure, and so we recommend you follow Infrastructure-as-Code (IaC) best practices including version-controlling your UDF. If you have questions or suggestions for other utility UDFs, we’d like to hear from you: create an issue directly in GitHub repo, or ask away in our Stack Overflow forum.
In a follow-up blog post, we’ll dive deeper into testing UDFs (unit tests and end-to-end pipeline tests) as well as setting up a CI/CD pipeline (for your pipelines!) including triggering new deployment every time you update your UDFs - all without maintaining any Apache Beam code.



