Building Large Scale Recommenders using Cloud TPUs
Gagik Amirkhanyan
Software Engineer, Cloud TPU
Bruce Fontaine
Software Engineer, TensorFlow TPU
Building Large Scale Recommenders using Cloud TPUs
Introduction
Personalized recommender systems are used widely for offering the right products or content to the right users. Some examples of such systems are video recommendations (“What to Watch Next”) on YouTube, Google Play Store app recommendations and similar services offered by other app stores and content services. In essence, recommendation systems filter products or content from a large number of options and offer them to users. Read on to learn how to use the TPU embedding API to accelerate the training of recommendation systems, particularly models with large embedding tables.
The embedding lookup operation is a critical component for large scale recommendation systems (e.g., Wide and Deep, DLRM or Deep & Cross Network) and can easily become a performance bottleneck, particularly for large tables distributed across multiple accelerators. TPUEmbedding API addresses this bottleneck. The TPUEmbedding API allows users to efficiently handle very large tables by automatically sharding or partitioning them across all available TPU cores. Along with ultra-fast chip-to-chip interconnect it can scale seamlessly from the smallest TPU configuration (8 TPU devices) to a TPU pod slice (>=32 TPU devices). This allows embedding models to scale from ~ 200GB on one TPU v4-8, to multiple TBs on a TPU pod slice.
In a recently published post on large recommendation model training, Snap achieved ~3x more throughput while lowering the cost by 30% by using the TPU embedding API and other optimizations on a v3-32 system when compared to a 4xA100 system. Thanks to the dedicated chip-to-chip high speed interconnect and optimized TPU software stack we hope that you too can train your recommendation models faster, reducing the training cost at the same time. To this end, here, we present an overview of the TPUEmbedding API along with various performance optimization techniques.
Simplified Recommendation Pipeline
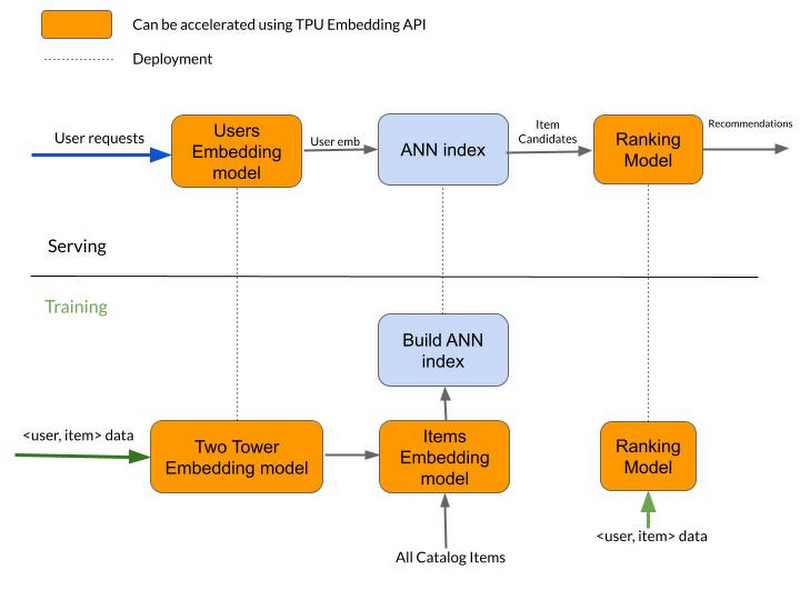
In the presented pipeline, we note that the TPUEmbedding API can be used to accelerate training of both retrieval models (such as the two-tower model) and ranking models (such as DLRM).
As a rule of thumb, we can expect that the TPUEmbedding API provides performance benefit for tables with more than 100K rows.
TPUEmbedding APIs
To use the TPUEmbedding API, one TPUEmbedding TableConfig (of type tf.tpu.experimental.embedding.TableConfig) for each table in your model needs to be defined.
Note that:
vocabulary_size: is the size of the table's vocabulary (number of rows),dim: is the embedding dimension (width) of the table.optimizer:is a per table optimizer. If set it will override the global optimizer.combiner: is an aggregator to be applied for multi-hot embedding lookups (for Sparse/Ragged Tensors it is applied to the last dimension). It’s ignored for one-hot or dense embedding lookups.
Next a TPUEmbedding FeatureConfig (of type tf.tpu.experimental.embedding.FeatureConfig) for each embedding feature in the model is defined.
Note that:
max_sequence_length: is only used for sequence features with `max_sequence_length` > 0. If the sequence is longer than this, it will be truncated.output_shape: Optional argument to configure the output shape of the feature activation. If not provided, the shape can be either provided to the TPUEmbedding.build or auto detected at the runtime.
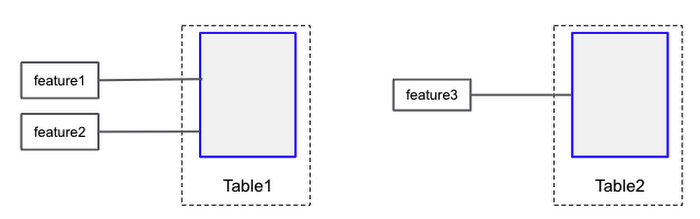
Each feature is assigned to an embedding table through the table argument and multiple embedding features can use the same TableConfig instance. When two or more features share the same TableConfig instance, a shared table will be created for feature lookups.
The output_shape argument can be set when the layer is unable to determine the shape of the input at compile time. It should be set to the desired output shape, without the embedding dimension. For example, if you are feeding dense inputs, this can be set to the same dimensions as the dense shape, since the combiner is not applied to dense inputs. For sparse inputs (such as SparseTensor or RaggedTensor), this can be set to the expected input shape without the last dimension (since that dimension is where the combiner acts.
The above configuration has two tables, and three features. The first two features will be looked up in the first table and the third feature will be looked up in the second table.
After this you define a TF2 Keras layer for embedding lookups with TPU.
This layer must be applied to the categorical inputs before the dense layers are applied. Setting pipeline_execution_with_tensor_core=True improves the training performance by overlapping the TPU embedding lookup computations with the dense computations. This may lead to some weights being stale, but in practice the impact on correctness is small.
The optimizer argument is used as a global optimizer for each embedding table that doesn’t have a table level optimizer. For most use cases a single optimizer is enough for all embedding tables, but some advanced use cases can require a table level optimizer/learning rate.
The following code snippet creates a functional style Keras model:
Note: You can only have one TPUEmbedding layer created under a TPUStrategy and it can only be called once per training function. For a two tower network, both towers need to use the same TPUEmbedding call.
For details please refer to the documentation on TPUEmbedding model creation.
You can also follow the TensorFlow 2 TPUEmbeddingLayer: Quick Start colab to build a simple ranking model using the MovieLens 100K dataset with the TPUEmbedding layer.
How to Optimize Performance?
Pipelining embedding lookups with dense computations
TPU Embedding API implementation allows the embedding lookup to run in parallel with dense computations, which can improve the performance. Setting pipeline_execution_with_tensor_core=True in the layers constructor will enable the embedding lookups for step n+1 in parallel with the dense computations for step n. In particular, the lookup for step n+1 will happen before the update on the embedding tables for step n. Although this is mathematically incorrect in general, we have found that this is safe to enable for most models, since the ids that are used in step n and n+1 have little overlap.
Choosing which tables to shard based on their sizes
Sharding small embedding tables (less than 10000 rows) between TPU cores can be suboptimal as it increases network communication between TPU cores without saving much HBM memory on each TPU core. The PartialTPUEmbedding API allows sharding large tables between TPU cores via the normal TPUEmbedding API, while keeping small tables mirrored on each TPU core.
The PartialTPUEmbedding API is very similar to the tfrs.layers.embedding.TPUEmbedding API, with size_threshold extra argument. Tables with vocabulary sizes less than size_threshold are not sharded (replicated across TPU cores), while tables with sizes more than size_threshold are sharded.
Further performance improvement by Input pipeline Optimization
Now that embedding table lookup on the TPU with the TPUEmbedding API is much faster, the next bottleneck might be in the input pipeline. Please refer to the Better performance with the tf.data API guide and the Analyze tf.data performance with the TF Profiler guide, to learn more about optimizing input data pipelines.
Exporting models for serving
There are multiple ways to export models for serving. The easiest way is to start from an already trained checkpoint:
Note that the TPUEmbedding layer supports serving a subset of the tables, which is useful when exporting part of a co-trained model:
When creating a SavedModel using the method above, you must have a single VM with enough capacity to load and save the entire model. Since the TPUEmbedding layer supports multi TB embedding tables, this may be difficult. In this situation you can use the following method instead:
What’s Next
In this article, we reviewed the TPUEmbedding API and how you can leverage this API to accelerate the training of your retrieval and ranking models. Once the retrieval model is trained, you can create the approximate nearest neighbor (ANN) index using the embedding trained via the retrieval model (you can deploy low latency ANN lookup using Vertex AI’s matching engine). And finally we presented multiple ways to export the ranking model used for generating the final recommendation to the end users.
The TPUEmbedding API is open sourced in the TensorFlow Recommenders library. Additionally, TensorFlow 2 also offers the mid level TPU Embedding API for more fine-grained embedding configuration. Examples of open source implementations for DLRM and DCN v2 ranking models can be found in the TensorFlow Model Garden. Detailed tutorials for training these models on Cloud TPUs are available at Cloud TPU user guide.
The recommendation pipeline presented here is a simplified version. In practice the implementation choice might depend on multiple factors. You can refer to this article for a summary of various options to build and serve recommendation models on Google Cloud Platform.
The unique architecture and dedicated chip-to-chip high speed interconnect makes TPU the ideal platform to train and serve your custom recommendation models. Further, we highly recommend using the TPUEmbedding API presented here to greatly accelerate training and inferencing on these models.
Happy hacking!