Backup & Disaster Recovery strategies for BigQuery
Sonakshi Pandey
Data Analytics Leader
Praveen Kumar Akunuru
Customer Engineer, Google Cloud
Backup & Disaster Recovery strategies for BigQuery
BigQuery is increasingly becoming the landing zone of choice for many customers' data in Google cloud. BigQuery is designed to provide high data durability. Data is written synchronously to 2 availability zones and within these zones, data is written using erasure encoding to make sure data can be recovered from multiple disk failures. As of this writing in October 2022, BigQuery is built to automatically recover from zone level catastrophic failures with 99.99% availability and very high durability.
We increasingly see that many data applications have disaster recovery requirements that exceed the levels provided by BigQuery natively. For example, regulatory requirements in some industries mandate higher data durability requirements. To accommodate these, there is a need to create a robust backup and recovery strategy for your data to help these applications meet the durability & availability requirements in case a BigQuery dataset in a region suffers a persistent data loss event.
In this document, we will walk you through different failure modes and the impact of these failures on data in BigQuery. Additionally, you will learn different backup and disaster recovery strategies to ensure your data and workloads remain available in case of a disaster.
Different failures and their impact on BigQuery data
It is important to distinguish between the type of failures that can result in data loss and failures that are benign. Soft failures, which are defined as failures that do not result in actual hardware destruction, like power loss, network loss events etc, in general do not result in data loss. Hard failures, where there is actual failure or destruction of hardware are situations that can potentially result in data loss events.
There is another potential type of failure, Software bugs. These can be bugs in the SQL code written by end users, or bugs in the product code itself. Data in BigQuery is immutable. i.e. data once written is not modified. Whenever a change happens, a new version of the data is written. BigQuery retains all data added, updated, or deleted in the last 7 days. i.e. BigQuery provides 7 days of time travel. This capability helps to recover from any user initiated data loss events or software level errors.
Zone level and lower level failures
BigQuery provides zone level redundancy for both data and compute slots. i.e. BigQuery is designed so that there is no user visible service availability loss or data loss when machine level failures, disk level failures happen.
While short lived zone level disruptions are not common, they do happen. BigQuery automation, however, will failover queries to another zone within a minute or two of any severe disruption. Already inflight queries may not immediately recover, but newly issued queries will. This would manifest as inflight queries taking a long time to finish while newly issued queries complete as expected.
Even if a zone were to be unavailable for a longer period of time or a catastrophic event results in hard failure of one zone, no data loss is expected due to the fact that BigQuery synchronously writes data to two zones. Sufficient compute redundancy is maintained to cover for zone level failures. Due to these, even in the face of zone loss, customers are not expected to experience a service disruption.
Regional failure
Similar to soft failures at other levels, Region level soft failures in general do not result in data loss. However, when there is a catastrophic event that results in loss of infrastructure for an entire region, there is a possibility of data loss. To overcome any service & data disruptions in such cases, based on the need, you need to build backup & disaster recovery solutions over and above what is natively provided.
Keep in mind before designing for DR
Define RPO, RTO before choosing the strategy
RPO - Recovery point objective. Defines the maximum period for which there can be a data loss.
RTO - Recovery time objective. Defines the minimum time within which the system is expected to be restored and ready to serve users.
For every application, work with your data consumers and define the RPO, RTO that are acceptable. More stringent requirements will be more expensive to set up and manage. This is a trade off. If you are building this to meet regulatory requirements, identify these clearly before designing the system.
Make informed decisions when choosing the regions to host your backup copy
Based on where the primary copy of data is located, it is recommended to choose a geographically distant region to host the backup of the data. For example, if your primary dataset is in us-west1, you can choose northamerica-northeast2 or us-east1 to host a copy of your data.
In the case of BigQuery multi-region dataset, avoid backing up to regions within the scope of the multi-region. For example, if your primary dataset is in multiregion US, then avoid choosing us-central1 to backup your data. The region and multi-region may share failure domains and have shared fate in disaster. Instead, you can back up the data to a non-US region, such as northamerica-northeast1.
If you have data residency requirements that require the data to be physically stored within the United States, then it is best you choose two regional datasets like us-central1 and us-east1 to host primary and backup of your data.
Plan for periodic dry runs to ensure your DR set up works as expected.
In this blog, we are proposing a few strategies for backing up your data and designing for disaster recovery. We recommend that you also think about compute and traffic redirection in case of a disaster. In case of the compute, you need to ensure you have slots provisioned in another geographically separate region where the data backup copy is stored. Plan for dry runs every few months to ensure your traffic is directed from one region to another incase one region is completely shut off.
Backing up the data
If taking a regular backup of the data is sufficient for your business requirements, then you can use one of the below approaches based on the need.
7 day time travel
BigQuery provides time travel to allow you to access data stored in BigQuery that has been changed or deleted in the past seven days. With time travel you can query data that was updated or deleted, restore a table that was deleted, or restore a table that expired. Time travel only provides access to historical data for the duration of the 7 days. To access the data longer than that use table snapshots.
Snapshots
A BigQuery table snapshot preserves the data of a table at a particular time. You can save a snapshot of a current table, or create a snapshot of a table as it was at any time in the past seven days. A table snapshot can have an expiration; when the configured amount of time has passed since the table snapshot was created, BigQuery deletes the table snapshot. You can query a table snapshot as you would a standard table. Table snapshots are read-only, but you can create a standard table from a table snapshot, and then you can modify the restored table.
Caution: If you are using CMEK to encrypt your tables, the snapshots will also use the same CMEK key. Please be aware that for any reason if the CMEK key is disabled you will lose access to snapshots as well.
Copy dataset
Using the BigQuery copy dataset feature you can copy a dataset within a region, or from one region to another, without having to move, and reload data into BigQuery. This feature is useful if you want to copy the dataset one time or on a customized recurring schedule. One thing to note, this is an entire data copy and not incremental. Check out more information here.
Export to GCS
BigQuery allows you to export the data into Google Cloud Storage. This can serve as a backup of your tables in BigQuery, and the exported data can be loaded back to BigQuery in case the original tables are corrupted/deleted. Check out the location considerations to make a decision on which region your Google Cloud Storage bucket should be located in.
DR Solutions for BigQuery
Approach 1 - Write data in at least 2 BigQuery datasets in multiple regions
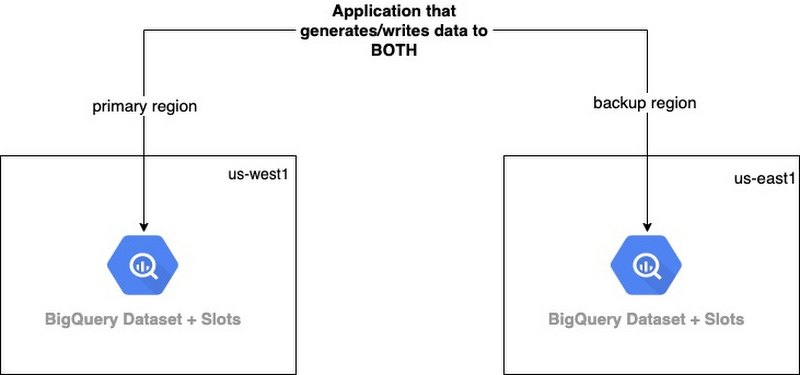
In this approach, the goal is to maintain multiple completely updated copies of your data. You will have to design your application to write data in 2 or more Bigquery datasets in primary and backup regions. In case of a disaster, if the primary region goes down, the data consumers can use the data from the backup region.
Because the mechanism for writing to each region is independent, there is a chance that writes may happen in one region, and not the other. Special care must be taken to ensure that writes are idempotent, and that writes retry if they fail.
2 or more copies of data means you use double the storage. Slots can be sized in the remote region based on the need. In general, provisioning capacity for writes should be sufficient. In case of a disaster, there is always an option of using on-demand for queries. This approach protects your data from region level failures and provides higher availability relative to what BQ natively provides.
Approach 2 - Export data to GCS in another region/dual region or multi region bucket
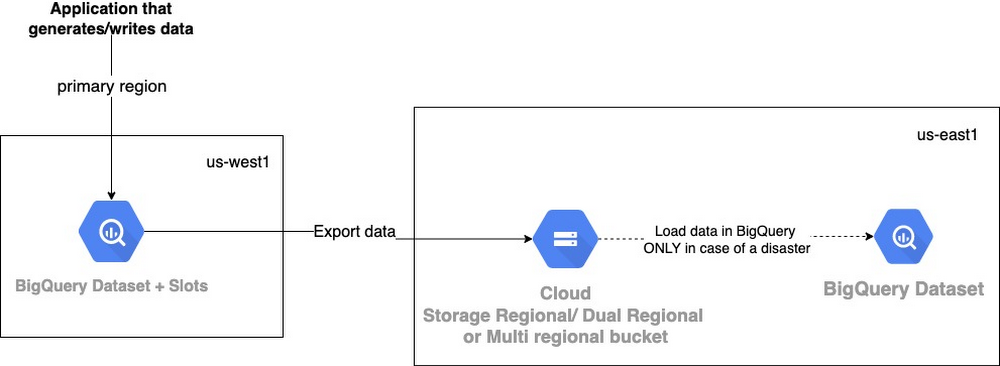
In this approach, the goal is to export your BigQuery data to a GCS bucket. If you are using a BigQuery multi regional bucket, you must ensure your export into GCS is also multi regional, or dual region. This ensures your backup data is never collocated solely with your live data in BigQuery. The data is exported to GCS based on your RPO on regular intervals. The data can be restored into BigQuery in case of a disaster.
For example, if your RPO in case of a regional failure is 1 week, you need to take full backups at least on a weekly basis. With backup available as of last week’s state, we will also have to keep a backup of the incremental data coming from source systems for the last 1 week for the ability to restore the data to its current state. An alternative could be to make sure that we can get the incremental data for the RPO period from source systems.
BigQuery supports exports to Avro, Parquet, CSV, JSON formats with GZIP, DEFLATE or SNAPPY compression types. So data can be compressed while exporting to GCS and will incur low costs as compared to approach 1. Note that this is a complete export, and not an incremental one, so set up versioning on your GCS bucket accordingly.
Based on your RTO it is recommended that you reserve a few slots in the backup region so that you have compute capacity ready in case of a disaster.
What's next
In this blog, we discussed the High Availability SLA and Data durability that BigQuery provides natively and how this is achieved. We discussed capabilities like TimeTravel, Snapshots, and free data export abilities. Customers can use these capabilities to build Backup & DR solutions in case their HA & DR requirements are much more stringent relative to what is natively provided by BigQuery. We proposed a couple of approaches and recommend you to test your solutions regularly to make sure they work as expected.
Keep an eye on BigQuery release notes to keep abreast of new capabilities that may help with your specific requirements. For example, we recently released the capability to read append history from BigQuery tables. For append only tables, you will be able to set up an incremental backup solution using this capability.



