Architect your data lake on Google Cloud with Data Fusion and Composer
Neha Joshi
Cloud Consultant, GCP Professional Services
With an increasing number of organisations migrating their data platforms to the cloud, there is also a demand for cloud technologies that allow utilising the existing skill sets in the organisation while also ensuring successful migration.
ETL developers often form a sizable part of data teams in many organisations. These developers are well versed in the use of GUI based ETL tools as well as complex SQL and also have or are beginning to develop programming skills in languages such as Python.
In this series, I will share an overview of:
- a scalable data lake architecture for structured data using data integration and orchestration services suitable for the skill set described above [this article]
- detailed solution design for easy to scale ingestion using Data Fusion and Cloud Composer
I will publish the code for this solution soon for anyone interested in digging deeper and using the solution prototype. Look out for an update to this article with the link to the code.
Who will find this article useful
This article series will be useful for solution architects and designers getting started with GCP and looking to establish a data platform/data lake on GCP.
Key requirements of the use case
There are a few broad requirements that form the premise for this architecture.
- Leverage existing ETL skill set available in the organisation
- Ingest from hybrid sources such as on-premise RDBMS (e.g., SQL Server, Postgres), flat files and 3rd party API sources.
- Support complex dependency management in job orchestration, not just for the ingestion jobs, but also custom pre and post ingestion tasks.
- Design for a lean code base and configuration driven ingestion pipelines
- Enable data discoverability while still ensuring appropriate access controls
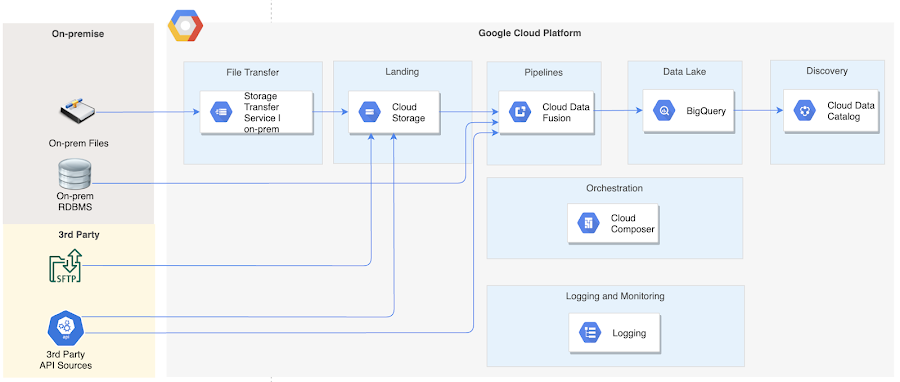
Solution architecture
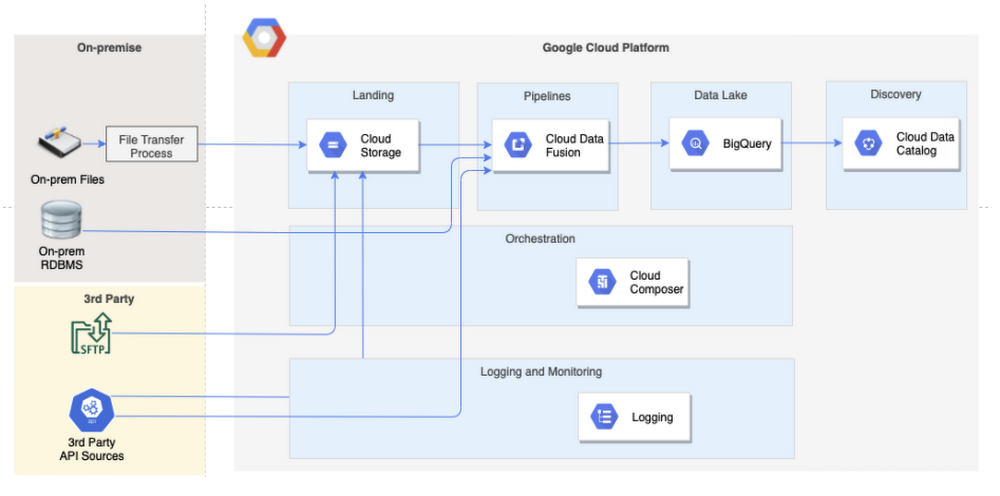
Architecture designed for the data lake to meet above requirements in shown below. The key GCP services involved in this architecture include services for data integration, storage, orchestration and data discovery.
Considerations for tool selection
GCP provides a comprehensive set of data and analytics services. There are multiple service options available for each capability and the choice of service requires architects and designers to consider a few aspects that apply to their unique scenarios.
In the following sections, I have described some considerations that architects and designers should make during the selection of different types of services for the architecture, and the rationale behind my final selections for each type of service.
There are multiple ways to design the architecture with different service combinations and what is described here is just one of the ways. Depending on your unique requirements, priorities and considerations, there are other ways to architect a data lake on GCP.
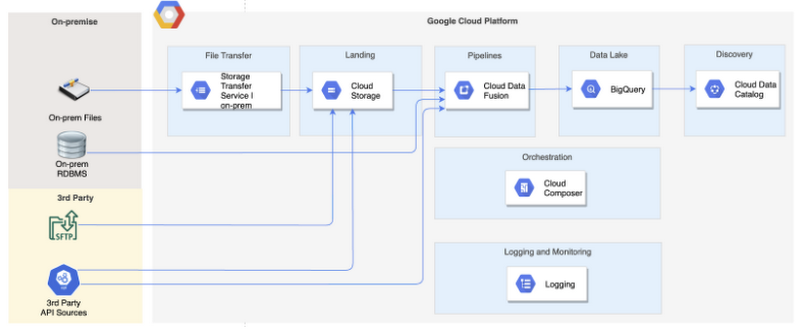
Data integration service
The image below details the considerations involved in selecting a data integration service on GCP.
Integration service chosen
For my use case, data had to be ingested from a variety of data sources including on-premise flat files and RDBMS such as Oracle, SQL Server and PostgreSQL, as well as 3rd party data sources such as SFTP servers and APIs. The variety of source systems was expected to grow in the future. Also, the organisation this was being designed for had a strong presence of ETL skills in their data and analytics team.
Considering these factors, Cloud Data Fusion was selected for creating data pipelines.
What is Cloud Data Fusion?
Cloud Data Fusion is a GUI based data integration service for building and managing data pipelines. It is based on CDAP, which is an open source framework for building data analytics applications for on-premise and cloud sources. It provides a wide variety of out of the box connectors to sources on GCP, other public clouds and on-premise sources.
Below image shows a simple pipeline in Data Fusion.
What can you do with Data Fusion?
In addition to the capability to create code free GUI based pipelines, Data Fusion also provides features for visual data profiling and preparation, simple orchestration features, as well as granular lineage for pipelines.

What sits under the hood?
Under the hood, Data Fusion executes pipelines on a Dataproc cluster. Data Fusion automatically converts GUI based pipelines into Dataproc jobs for execution whenever a pipeline is executed. It supports two execution engine options: MapReduce and Apache Spark.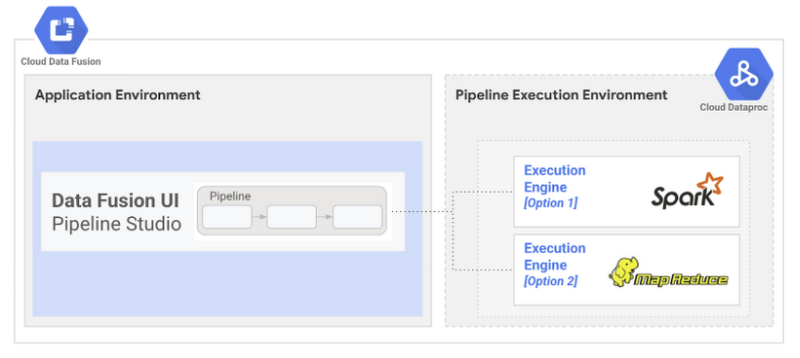
Orchestration
The tree below shows the considerations involved in selecting an orchestration service on GCP.
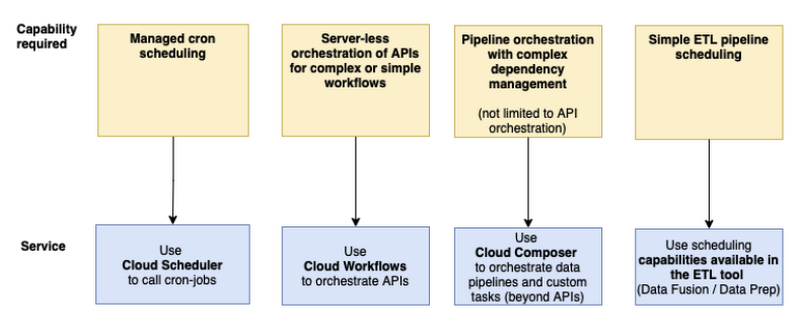
My use case requires managing complex dependencies such as converging and diverging execution control. Also, UI capability to access operational information such as historical runs and logs, and the ability to restart workflows from the point of failure was important. Owing to these requirements, Cloud Composer is selected as the orchestration service.
What is Cloud Composer?
Cloud Composer is a fully managed workflow orchestration service. It is a managed version of open source Apache Airflow and is fully integrated with many other GCP services.
Workflows in Airflow are represented in the form of a Direct Acyclic Graph (DAG). A DAG is simply a set of tasks that needs to be performed. Below is a screenshot of a simple Airflow DAG.
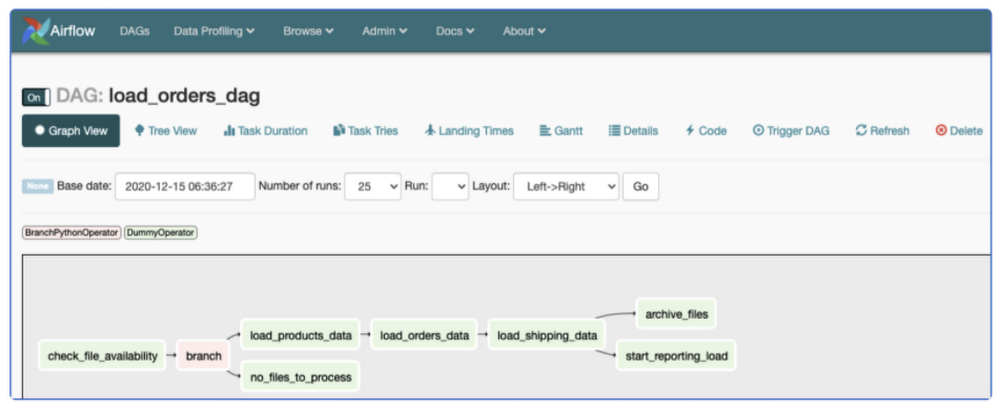
Airflow DAGs are defined using Python.
Here is a tutorial on how you can write your first DAG. For a more detailed read, see tutorials in Apache Airflow documentation. Airflow Operators are available for a large number of GCP services as well as other public clouds. See this Airflow documentation page for different GCP operators available.
Segregation of duties between Data Fusion and Composer
In this solution, Data Fusion is used purely for data movement from source to destination. Cloud Composer is used for orchestration of Data Fusion pipelines and any other custom tasks performed outside of Data Fusion. Custom tasks could be written for tasks such as audit logging, updating column descriptions in the tables, archiving files or automating any other tasks in the data integration lifecycle. This is described in more detail in the next article in the series.
Data lake storage
Storage layer for the data lake needs to consider the nature of the data being ingested and the purpose it will be used for. The image below provides a decision tree for storage service selection based on these considerations.
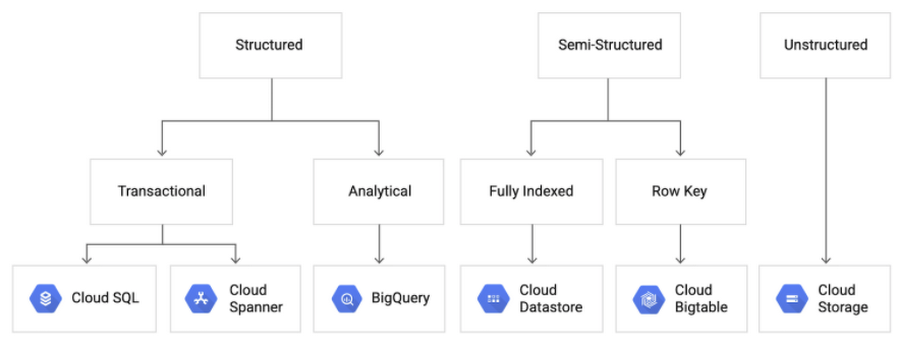
Since this article aims to address the solution architecture for structured data which will be used for analytical use cases, GCP BigQuery was selected as the storage service/database for this data lake solution.
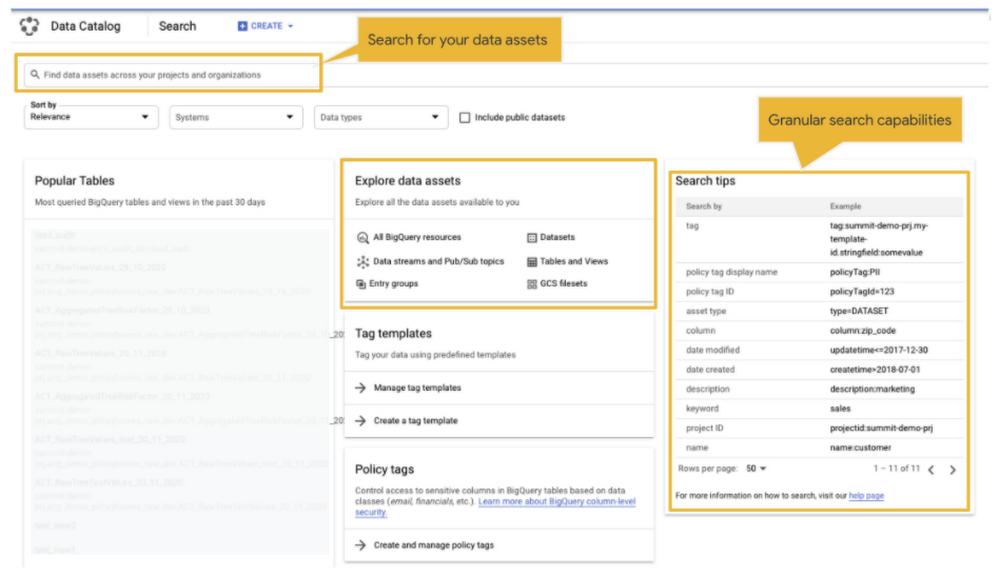
Data discovery
Cloud Data Catalog is the GCP service for data discovery. It is a fully managed and highly scalable data discovery and metadata management service that automatically discovers technical metadata from BigQuery, Pub/Sub and Google Cloud Storage.
There is no additional process or workflow required to make data assets in BigQuery, Cloud Storage and Pub/Sub available in Data Catalog. Data Catalog self discovers data assets and makes it available to the users for further discovery.
A glimpse again at the architecture
Now that we have a better understanding of why Data Fusion and Cloud Composer services were chosen, the rest of the architecture is self explanatory.
The only additional aspect I want to touch upon is the reason for opting for a Cloud Storage landing layer.
To land or not to land files on Cloud Storage?
In this solution, data from on-premise flat files and SFTP is landed into Cloud Storage before ingestion into the lake. This is to address the requirement that the integration service should only be allowed to access selective files and prevent any sensitive files from ever being exposed to the data lake.
Below is a decision matrix with a few points to consider when deciding whether or not to land files on Cloud Storage before loading into BigQuery. It is quite likely that you will see a combination of these factors, and the approach you decide to take will be the one that works for all those factors that apply to you.
Source: On-premise and SFTP Files
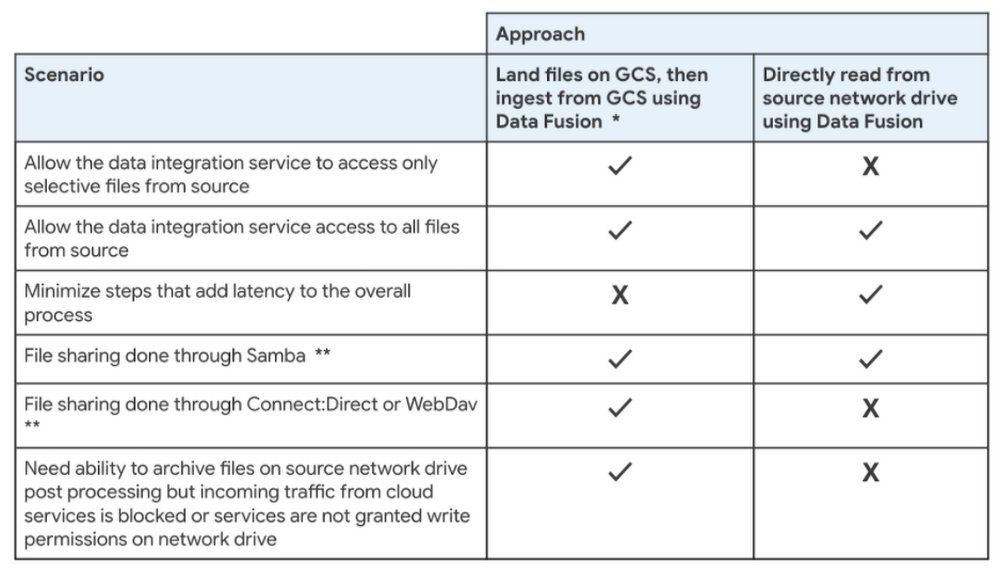
** Samba is supported but other protocols/tools of sharing files such as Connect:Direct, WebDav, etc are not.
3rd Party APIs
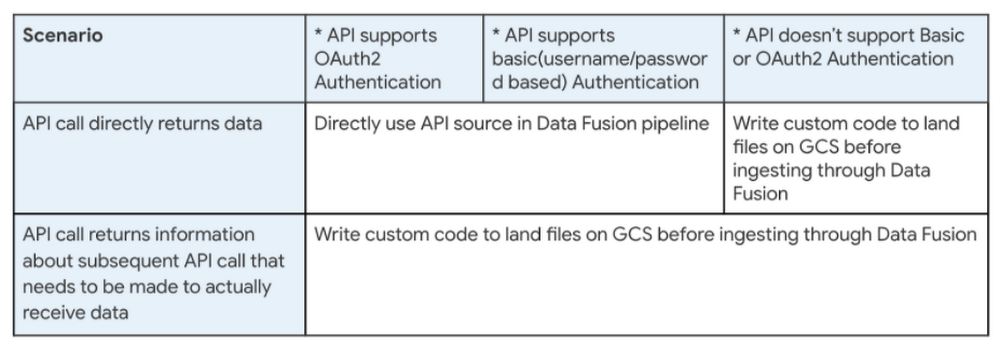
* Data Fusion out of box source connector for API sources (i.e., HTTP source plugin) supports basic authentication (id/password based) and OAUTH2 based authentication of source APIs.
RDBMS
No landing zone is used in this architecture for data from on-premise RDBMS systems. Data Fusion pipelines are used to directly read from source RDBMS using JDBC connectors available out of the box. This is considering there was no sensitive data in those sources that needs to be restricted from being ingested into the data lake.
Summary
To recap, GCP provides a comprehensive set of services for Data and Analytics and there are multiple service options available for each task. Deciding which service option is suitable for your unique scenario requires you to consider a few factors that will influence the choices you make.
In this article, I have provided some insight into the considerations you need to make to decide the right GCP service for your needs in order to design a data lake.
Also, I have described the GCP architecture for a data lake that ingests data from a variety of hybrid sources, with ETL developers being the key persona in mind for skill set availability.
What next?
In the next article in this series, I will describe in detail the solution design to ingest structured data into the data lake based on the architecture described in this article. Also, I will share the source code for this solution.
Learning Resources
If you are new to the tools used in the architecture described in this blog, I recommend the following links to learn more about them.
Data Fusion
Watch this 3 min video for a byte sized overview of Data Fusion or listen to a more detailed talk from Cloud Next. Then try your hand at Data Fusion by following this Code Lab to Ingest CSV data to BigQuery.
Composer
Watch this 4 min video for a byte sized overview of Composer or watch this detailed video from Cloud OnAir. Want to try your hand? Follow these Quickstart instructions.
BigQuery
Watch this quick 4 min video for an overview and access BigQuery with free access using the BigQuery sandbox (subject to sandbox limits).
Try your hand with Code Labs for BigQuery UI Navigation and Data Exploration and to load and query data with the bq command-line tool.
Have a play with BigQuery Public Datasets and query the Wikipedia dataset in BigQuery.
Stay tuned for part 2: "Framework for building a configuration driven Data Lake using Data Fusion and Composer"