Effingo: the internal Google copy service moving data at scale
Monika Nawrot
Engineering Manager
Stephanie Morton
Technical Editor
Every hour of every day, Google moves a lot of data around the world. But how? With the Effingo (Latin for ‘to duplicate’ or ‘copy’) data copying service, a Google-only service that moves data internally and on Google Cloud customers’ behalf.
As a Google Cloud customer perhaps you move data with Storage Transfer Service, a managed transfer option that provides out-of-the-box security, reliability, and performance, that eliminates the need to optimize and maintain scripts, and handle retries. Storage Transfer Service is useful for consolidating data from separate projects, to move data into a backup location, or to change the location of your data.
Likewise, Google’s internal services need very similar functionality to manage their data. This includes data that is in charge of the ecosystem of Google Cloud services, such as BigQuery and Cloud Spanner.
Effingo solves a challenging problem of data movement at a global scale. It supports a wide range of workloads with different traffic characteristics and different requirements for data replication, durability, and latency. In this article we will explore the main motivations behind data movement and solutions to core infrastructure problems that we face when copying exabytes of data on a daily basis.
Why move data in the first place?
But first, let’s think about why you even want to move or geographically distribute your data.
For one thing, you want to replicate your data for durability and reliability. You definitely don’t want to keep a single copy of your data. In the end, we’re talking about a file that is stored on a hard drive. Any hard drive can fail at any point. For this reason, keeping copies of your data in different locations helps ensure that at any point of time there is a copy of your file that you can read from. Moreover, these locations should be geographically distant from each other to avoid even temporary data loss due to natural disasters, network cuts, and other incidents that can impact a local area.
Second, you want your data to be close to your users to reduce latency. You want to serve data with minimal delay to give a great user experience. In many cases, delays caused by data transfers from remote locations can spoil the usability of your application or create the perception that your service doesn’t work. According to Google research, 53% of mobile users abandon sites that take over 3 seconds to load. There are other consequences of lack of data proximity: for example, transferring data from distant locations wastes network resources, which can have a negative impact on the environment. Google has been carbon-neutral for our operations since 2007, and we have matched 100% of the electricity consumption of our operations with renewable energy purchases annually since 2017, but we aim higher: Our goal is to run all our data centers and offices on carbon-free energy, 24/7, by 2030.
The third reason to geographically distribute your data is to balance storage capacity between clusters. This reduces the cost of storing data because it enables us to increase the overall capacity of our data centers and use computation power in less loaded clusters. We can then limit the amount of wasted resources and use otherwise idle hardware. This is especially relevant for batch processing and storing cold data where the exact storage location is not that important.
What are the challenges?
Operating at such a large scale as Google makes data movement a challenging problem for several reasons. Here are a few examples.
Data must be secure and consistent at its destination. Achieving this is complex. For example, to copy a file from one location to another, you need the following: throughput to read and write to disks, network capacity to transfer bytes between data centers, and compute resources to instrument the whole operation.
Considering the volume of data that Google operates on, high and predictable throughput is one of the key features of a copy service at scale. It is typical to transfer terabytes of data per second, and so it’s essential to have a scalable service that can handle traffic with sometimes rapidly changing patterns. It poses a further question: how to run such a service and still be resource efficient?
Finally, it’s crucial to ensure high system availability. Google infrastructure is dynamic and copying data between any two clusters may behave differently at different points of time. Effingo needs to be resilient to cluster turndowns, network bottlenecks, rapid changes in resource demands and capacity, and so on.
How do we solve (some) of these problems?
One of the core use cases for data movement is replication. If you want to ensure that your data is reliable, you want to keep more than one copy, ideally in different locations, to be less prone to data loss.
Let’s consider the following example. You have a file in cluster A, and you want to make copies in destinations B – G.
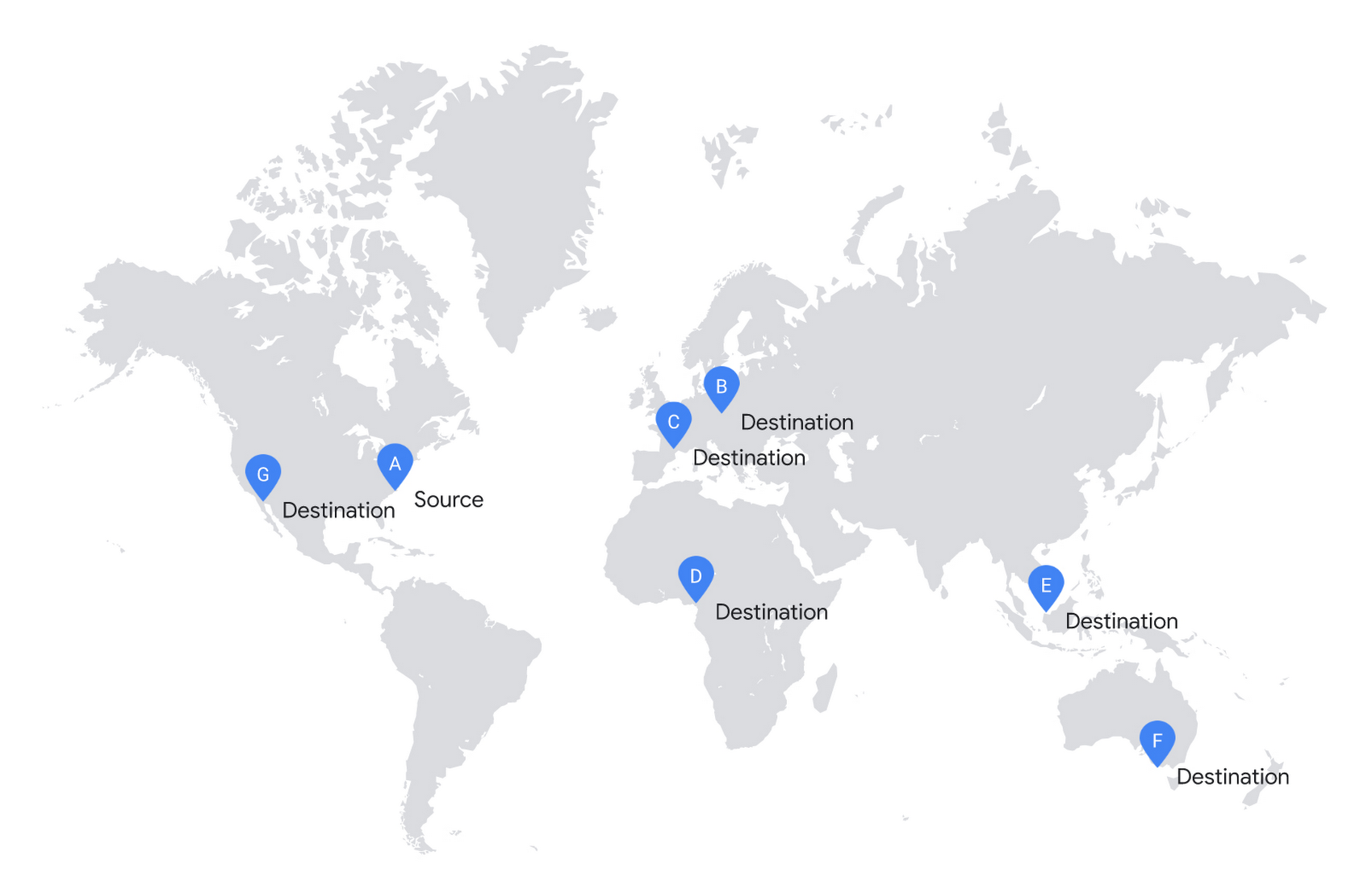
In the simplistic approach, you would start copying to all destinations in parallel.
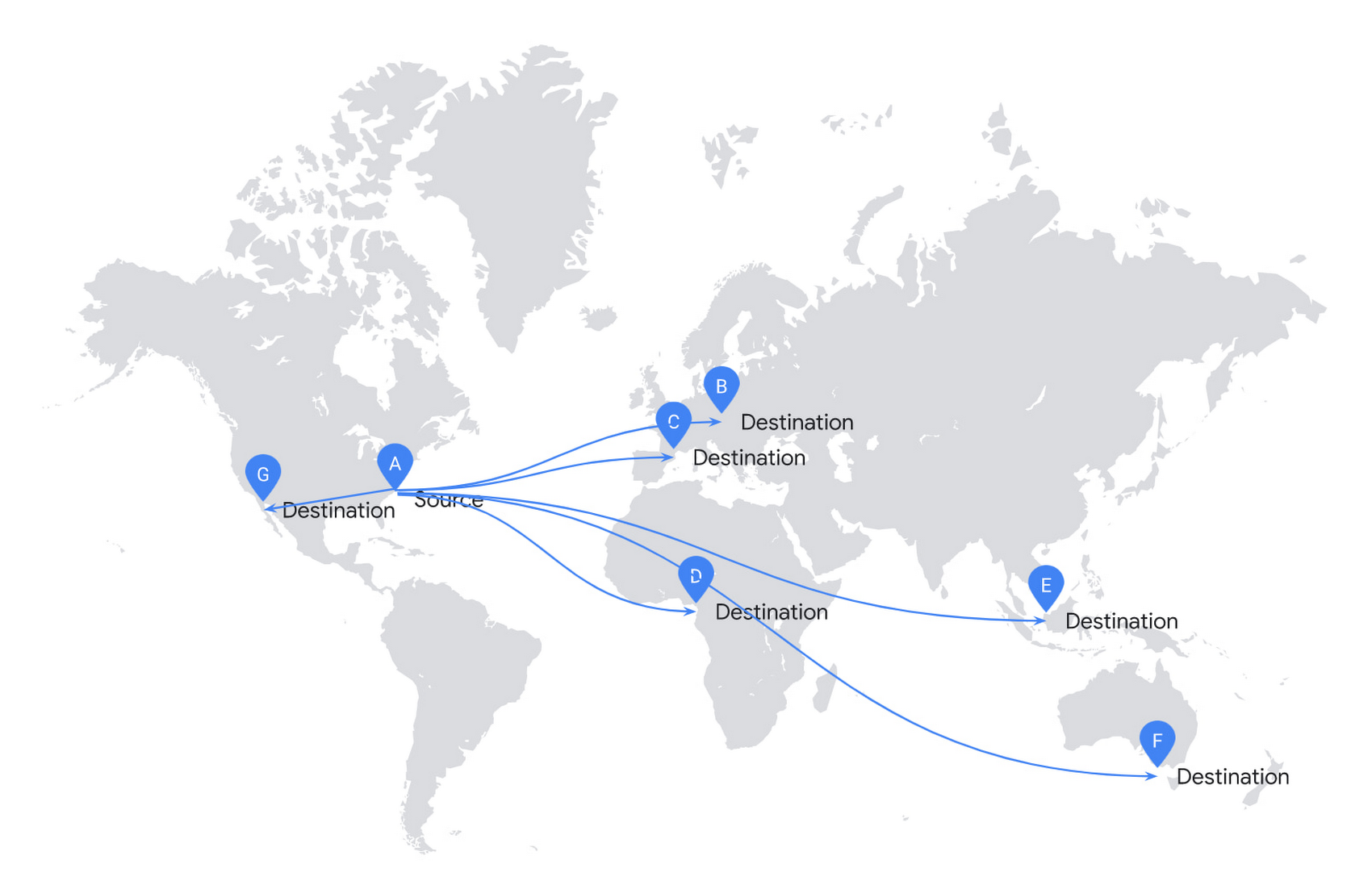
Unfortunately, it is highly inefficient to replicate your file this way. This solution doesn’t scale and requires significant investment in infrastructure.
If you consider the cost of network infrastructure, moving data across the ocean is an expensive operation. Effingo creates data transfer plans that reduce the volume of data to transfer across the ocean. If possible, it reuses already replicated data as a new source.
To create data transfer plans Effingo needs to know alternative data sources and be aware of the network topology.
If it goes to the alternative sources, Effingo stores a recent history of transferred files together with their metadata and time-bound permissions to access the files. Whenever a new copy is issued, Effingo checks whether there were copies of the original file that could serve as the same source but in the alternative location. Worth noting is that Effingo is very strict in verifying that both files — the requested source file and the alternative transfer file — are indeed the same to follow high security standards. Effingo not only checks whether the same user issued a copy from the same source but also if file properties including checksum, ciphertext checksum, mtime and several others match.
Once Effingo knows the source files and their alternative sources, it creates a transfer plan over the Google network. Effingo has a model of the network in the form of a graph where each location is a node and each edge is a weighted link between each node. For each copy Effingo creates a Minimum Spanning Tree over such a graph, which serves as an input to the transfer engine. Thanks to this approach we can select a plan that is optimal for each copy.
In the next example, we show a more efficient approach. Effingo first makes an expensive copy to a remote location and then uses it as a new source. For instance, Effingo first copies a file from the US (source A) to Europe (destination C) and then uses the Europe-based file as a copy source for copies on the same continent. Note that Effingo never stores files in temporary locations for optimization purposes – the service only uses locations explicitly requested by our users.
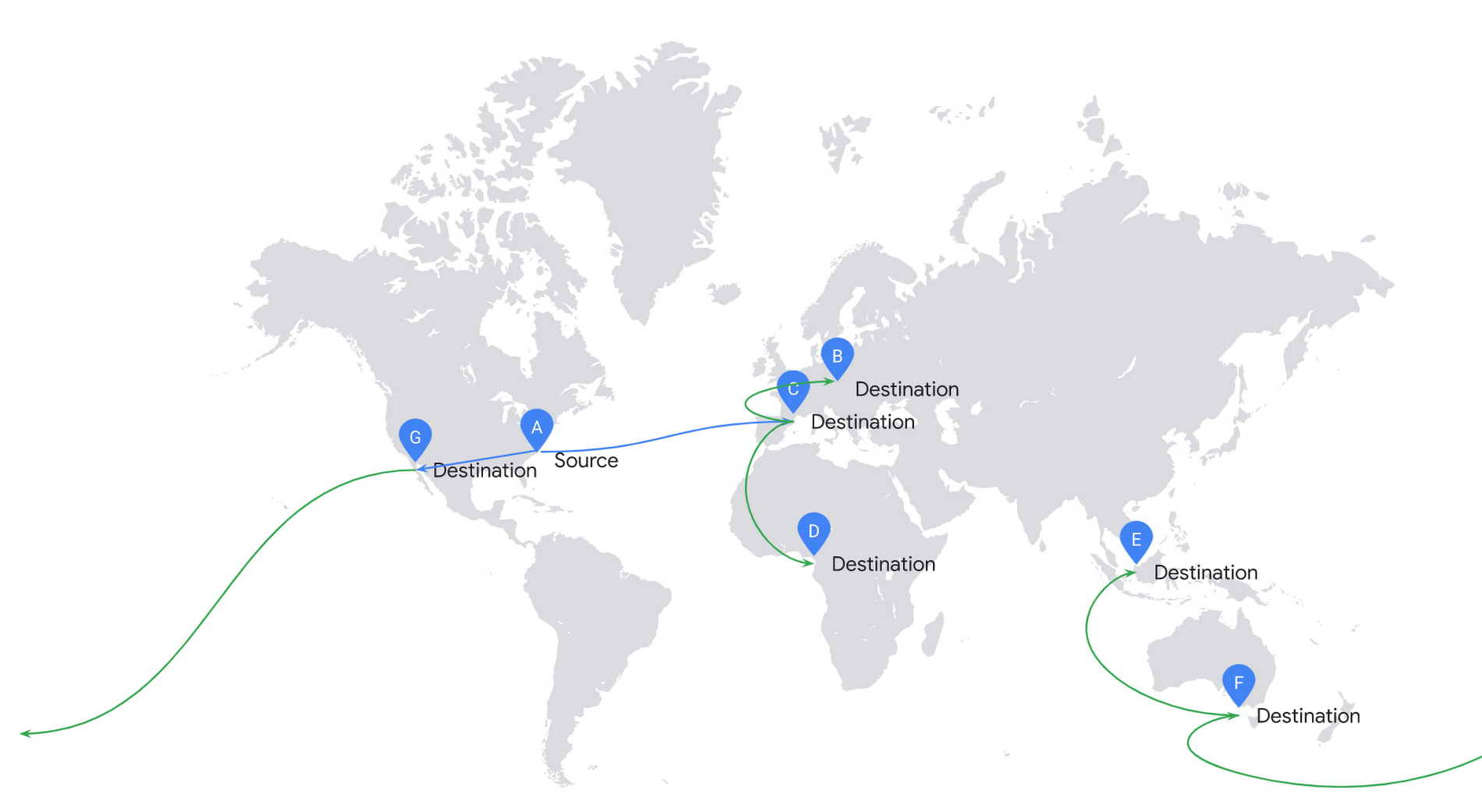
In addition to resource efficiency, the main challenge is to ensure high throughput of data transfer. We solve this problem by applying several approaches that address different problems that may arise.
As described above, our customers’ workloads exhibit a range of different traffic patterns, which results in dynamic changes in capacity on each network link. For this reason, Effingo not only needs to respond to altering resource availability, but also to ensure user fairness in such conditions. In other words, Effingo wants all copy operations to progress while using resources in the best possible way. To achieve this, it uses sophisticated parallelism controls. These controls scale the service up to meet increased demand and limit service capacity if there is service overload, performance degradation, or resource waste.
Further, Effingo must be very resilient and react quickly to errors. On the file level, the service extensively uses retries for transient failures and aborts transfers quickly if it detects non-retryable errors. Effingo uses metrics, logs, and other observability signals to adjust data transfers when needed. For example, it can detect that copies from a specific source are slow and there is another file replica available. Effingo then reconfigures the copy operation to use the other replica to complete the data move.
Data movement at global scale is hard
Hopefully at this point you have a better understanding of why moving data is a challenging problem for infrastructure that operates at Google’s global scale. Effingo supports a range of services that run on Google infrastructure, including Google Cloud services and many internal Google services. While moving data at large scale requires a lot of attention to resource usage and resilience to support high throughput, there is good news: We keep working on this problem and make our infrastructure better every day, so you can run your business on Google Cloud and all data movement is transparent to you.