Disaster recovery using Actifio, Google Cloud VMware Engine and Zerto
Rajesh Nanda
Partner Delivery Manager
Waheed Brown
Strategic Cloud Engineer
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialSome of the most desirable applications to move into the cloud are ones that run on proprietary platforms such as VMware, connected to enterprise storage arrays. But because those applications are often mission-critical, they can also be the most challenging—especially if they have demanding disaster recovery time objectives (RTOs) and recovery point objectives (RPOs), and are configured using an isolated, “bubble” network.
We want to help you find the right DR solution for your cloud projects quickly. In this blog post, we review the basic concepts involved in doing DR in the cloud. Then, we present an example use case of a fictionalized customer, Acme Corporation. Acme has a bubble network and very short RPO/RTO of two hours and four hours, respectively. We then evaluate several popular DR solutions that meet their requirements, and show you how to deploy them in Google Cloud.
Getting to know Acme Corp.
Acme Corp. is your classic legacy enterprise, and runs all of its applications on VMware and mainframe infrastructure in two on-premises data centers—one primary and the other for remote DR. Acme wants to move into Google Cloud to modernize infrastructure and reduce costs. As such, it needs to find a robust disaster recovery solution for a Google Cloud environment that can achieve its tight RPO/RTO requirements.
Further complicating the design, Acme practices DR with a bubble or “isolation network,” where the VMs in primary and DR sites have the same set of private IPs. This bubble network requirement brings additional challenges to the disaster recovery architecture in the cloud.
The following diagram illustrates Acme's different stacks of system, application and data, as well as how they perform backups and disaster recovery in their current on-prem data center environment.
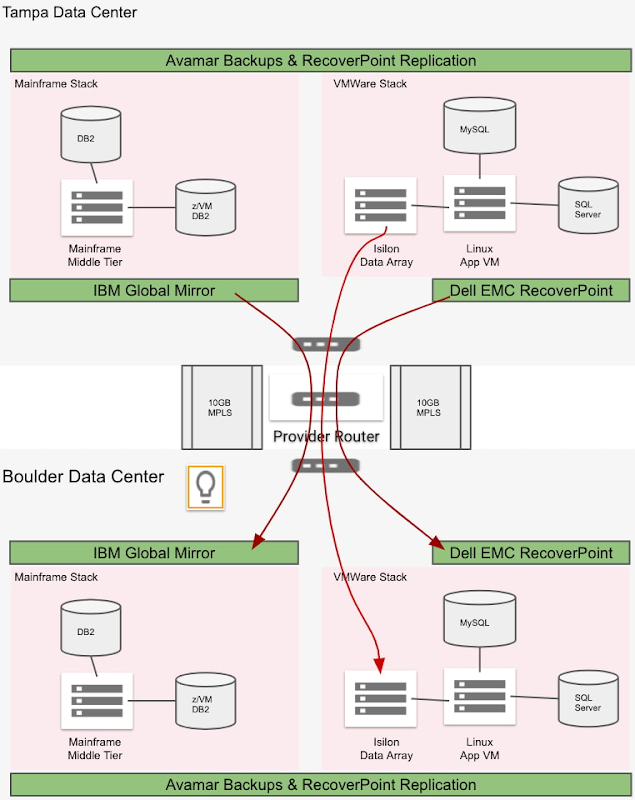
From the diagram, you can see the details of Acme’s setup:
For its current DR strategy, Acme conducts block-level data replication for all the data and resources in its on-prem data centers. Its overall RPO is two hours, and the RTO is four hours.
Acme has 500 VMs for Windows and 3000 servers in total.
Avamar can take daily backups of VMs, OSs, persistent disks and databases. Data is replicated to the DR data center. These backups are not used for DR.
IBM Global Mirror conducts block-level data replication for DR for the IBM mainframe stack, including the mainframe middle tier, the DB2 database (configuration table) and z/VM DB2 database (core server).
Isilon (i.e., PowerScale) SyncIQ conducts data replication for DR for Acme’s Isilon file data.
EMC RecoverPoint conducts data replication for DR for the VMware stack, including VMware VM-based applications, SQL Server, and MySQL databases.
By migrating to Google Cloud, the following changes apply to Acme’s system and applications:
Both IBM DB2 and z/VM DB2 are migrated into Compute Engine-based "Linux/Unix/Windows", LUW DB2
IBM Global Mirror is not applicable in the Google Cloud environment anymore
EMC RecoverPoint is not available in the GCP environment
Isilon, now called PowerScale, is now available as a SaaS solution in the Google Cloud environment
In addition, when it moved to Google Cloud, Acme adopted Apigee to orchestrate its web services, and that environment also needs to be protected.
Taken together, there are three major requirements that will determine the DR solution that we design for Acme’s systems running in Google Cloud:
Two-hour RPO requirement for production systems
Support for the current bubble network design and implementation, to avoid a major system and application rewrite
The ability to orchestrate the disk remount for thousands of VMs, each of which may have up to 24 disks mounted
A solution for the Apigee stack
Based on our team’s experience implementing this DR architecture for a real-world customer, we created this example DR solution for Acme. We divide Acme's systems and applications in GCP into the following stacks:
Apigee, the Google-provided managed service.
PowerScale (Isilon), running as a third party managed service in GCP.
Databases and applications running in VMs with a maximum of two-hour RPO.
Production applications running in VMs with data that don’t need to meet 2-hour RPO.
Exploring potential solutions
With those requirements in mind, we explored the following approaches.
Native regional DR and snapshots
GCP native regional DR via architecture design works well for cloud-native systems that are designed with HA and DR requirements. However, for Acme, this solution would require major application architecture changes. Also, this solution won't work with bubble network constraints because IP conflicts prevent real-time VM-level traffic between the primary and DR regions.
Further, this architecture relies on taking incremental snapshots for each disk. For Acme, this is unworkable: With its 3,000 servers, it will take great effort to make sure that each disk is restored from its snapshots and then mounted to the restored VM in the right order. This becomes almost impossible to manage without a multi-threading orchestration tool to automate this process under the situation of disaster recovery. We decide not to go down this path.
Actifio
Another promising solution is Actifio GO, a Backup and DRService platform available on Google Cloud. It delivers backup, disaster recovery, migration to Google Cloud, database and VM cloning for test data management (TDM), and ransomware recovery, as well as enabling analytics with BigQuery. Actifio GO’s service architecture comprises several components that work in unison to deliver the service. It also supports our bubble network requirement.
The following diagram illustrates the design of the Actifio DR solution for Acme.
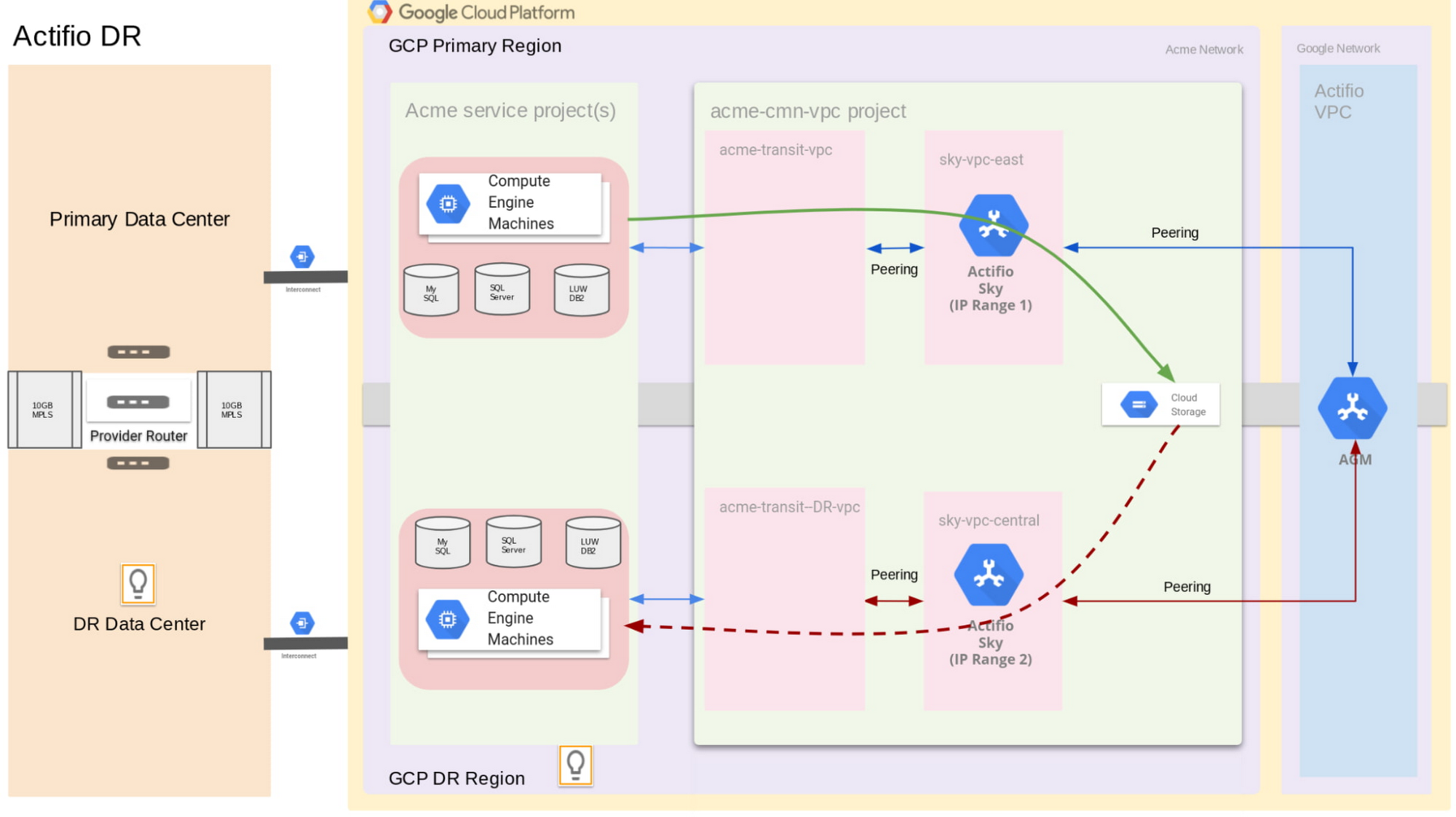
To support Acme’s bubble network and keep the same IP addresses in the DR region, we need the same set of Acme VPC and network settings in Acme’s Google Cloud DR region. Therefore, we have “acme-transit-DR-vpc” in the DR region mirror the “acme-transit-vpc” in the primary Google Cloud region. This is further made possible by the fact that Actifio uses Google Cloud Storage—more on that later.
Actifio Global Manager (AGM) is hosted in Google’s network. AGM needs to establish VPC peering with Acme’ VPC, so it can deploy Actifio Sky into Acme’s network to work as the agents for backup and recovery. The bubble network prevents us from deploying Actifio Sky into “acme-transit-vpc” and “acme-transit-DR-vpc” because AGM will peer with two VPCs with the IP ranges. Therefore, we create separate VPCs in each region, “sky-vpc-east” and “sky-vpc-central”, to run Actifio Sky.
In this configuration, since VPC peering is non-transitive (no more than two VPCs connected sequentially), AGM VPCs don't see the peering details of individual SKY VPCs with DR and Primary VPC CIDR ranges. Thus, the CIDR ranges for “sky-vpc-east” and “sky-vpc-central” need to be carefully selected because they need to peer with AGM VPC, “acme-transit-vpc” and “acme-transit-DR-vpc” respectively.
Actifio GO uses Cloud Storage to store its backup files. For local region backup only, we can use single-region Cloud Storage in the same region. For disaster recovery, we can use a Cloud Storage bucket in the DR region, improving performance. Actifio also can work with multi-region Cloud Storage buckets for high availability. Because Cloud Storage is used mainly for disaster recovery here, we recommended using either near-line or cold-line storage classes.
For general VMs where Actifio cannot meet the required RPO/RTO, Acme can migrate those on-prem VMs into Google Cloud VMware Engine, as described in the next section.
Google Cloud VMware Engine and Zerto
Google Cloud VMware Engine is a fully managed service running the VMware platform natively on Google Cloud bare metal infrastructure in Google Cloud locations and fully integrating with the rest of Google Cloud. To meet Acme’s demanding RTO/RPO requirements for its most demanding applications, we explore coupling it with Zerto, a scalable replication platform that virtually eliminates data loss and downtime to ensure continuous availability.
Google Cloud VMware Engine also works for mainframe applications. For these applications, the migrated OpenFrame instance can also run on VMware VMs in Google Cloud VMware Engine if needed. Then, we achieve cross-region DR using two Google VMware Private Clouds mirroring VMs using Zerto replication and restoration. Designed correctly, the RPO/RTO for this solution can be very small (RPO < 30 mins), easily satisfying Acme’s RPO/RTO (2 hours/4 hours) requirements.
The following two diagrams, replication and recovery, illustrate Acme’s Google Cloud VMware Engine + Zerto disaster recovery solution.
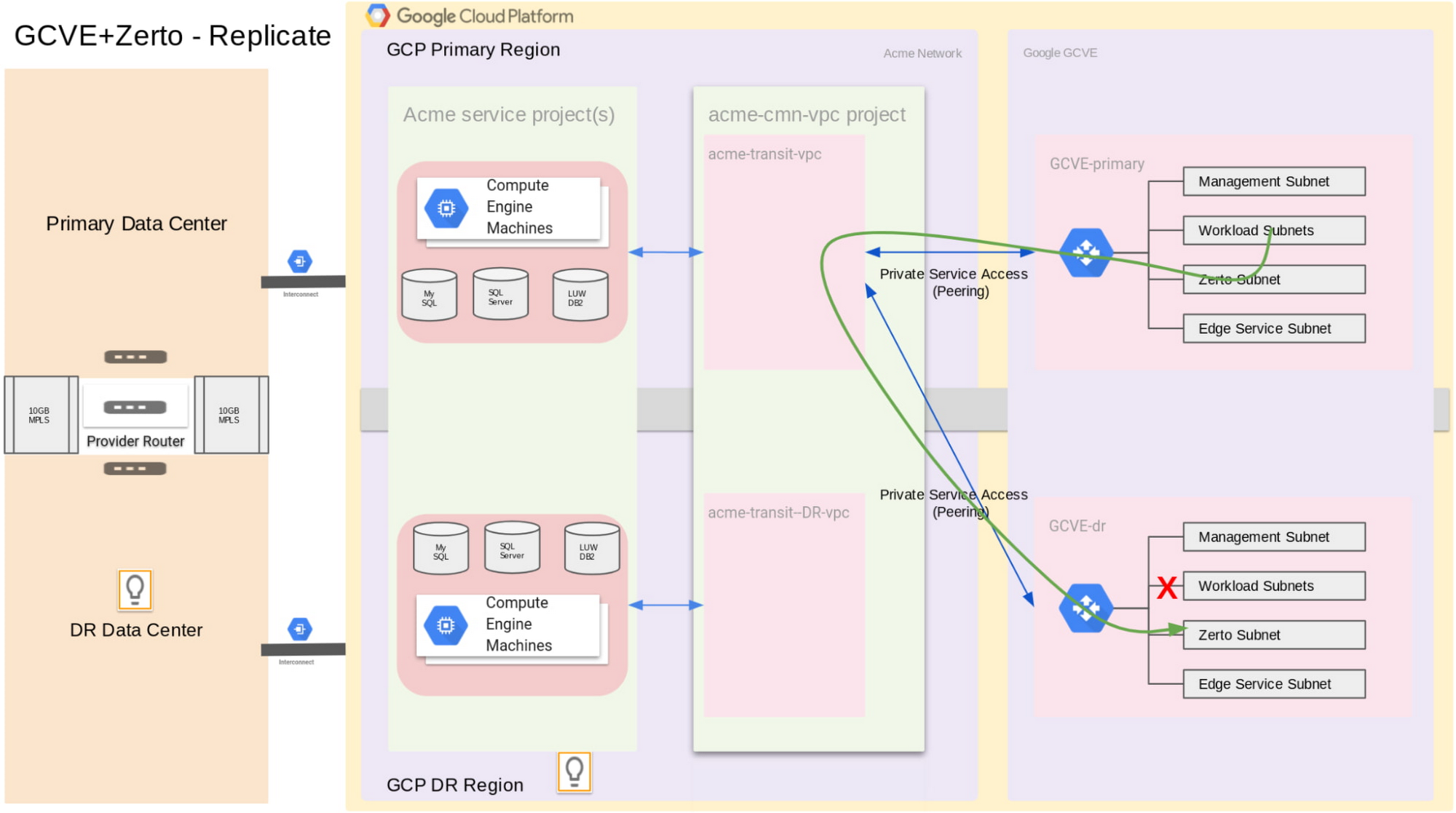
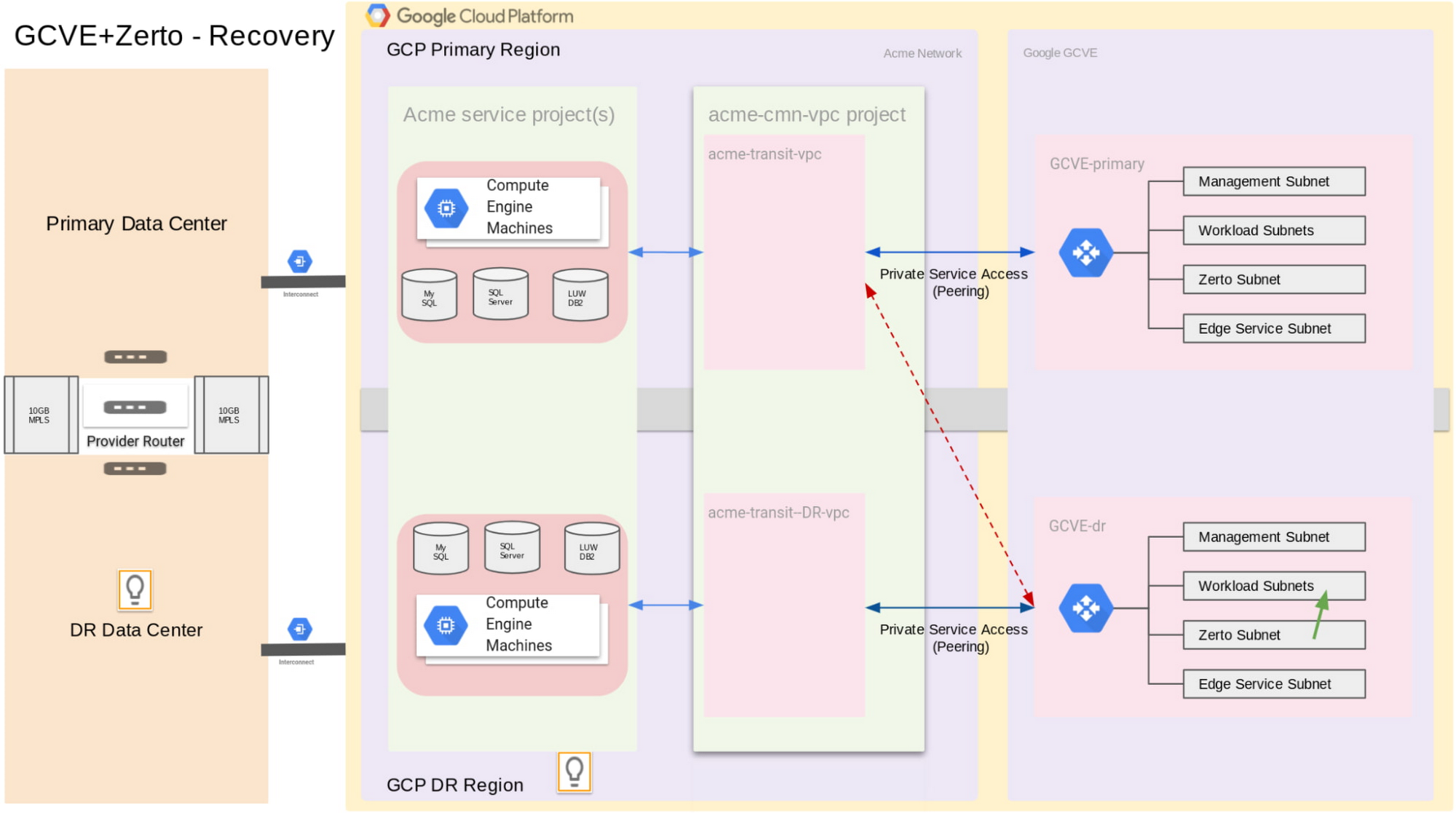
The network configuration happens mainly on the Google Cloud VMware Engine level. Google Cloud VMware Engine uses Private Service Access connection to peer with the Acme VPC to bring its VPC into the Acme network.
Because Acme uses a bubble network with identical IPs in the DR region, we configure “acme-transit-vpc” in the Primary region and “acme-transit-DR-vpc” in the DR region. Also, we have “Workload Subnets” with the same CIDRs in both Google Cloud VMware Engine VPCs.
Under normal circumstances, both Google Cloud VMware Engine VPCs are peered with the “acme-transit-vpc” VPC. Also, the route to the “Workload Subnets” in the GCVE-central (DR region) is turned off, so that there is no IP conflict. We configure Zerto to replicate data from GCVE-primary to GCVE-dr via the peered network connection through “acme-transit-vpc”.
In the event of a disaster in the primary Google Cloud region, the peered connection between GCVE-dr and “acme-transit-vpc” is manually disconnected. Then GCVE-dr is peered with the “acme-transit-DR-vpc”. Also, the route to the “Workload Subnets” in the GCVE-dr region is turned on. Then, Zerto restores the replicated VMs, data and applications into the “Workload Subnets”.
You can find detailed instructions on how to set up the Google Cloud VMware Engine VPC and configure the network connections with an existing Google Cloud VPC in the following document: Setting up private services access.
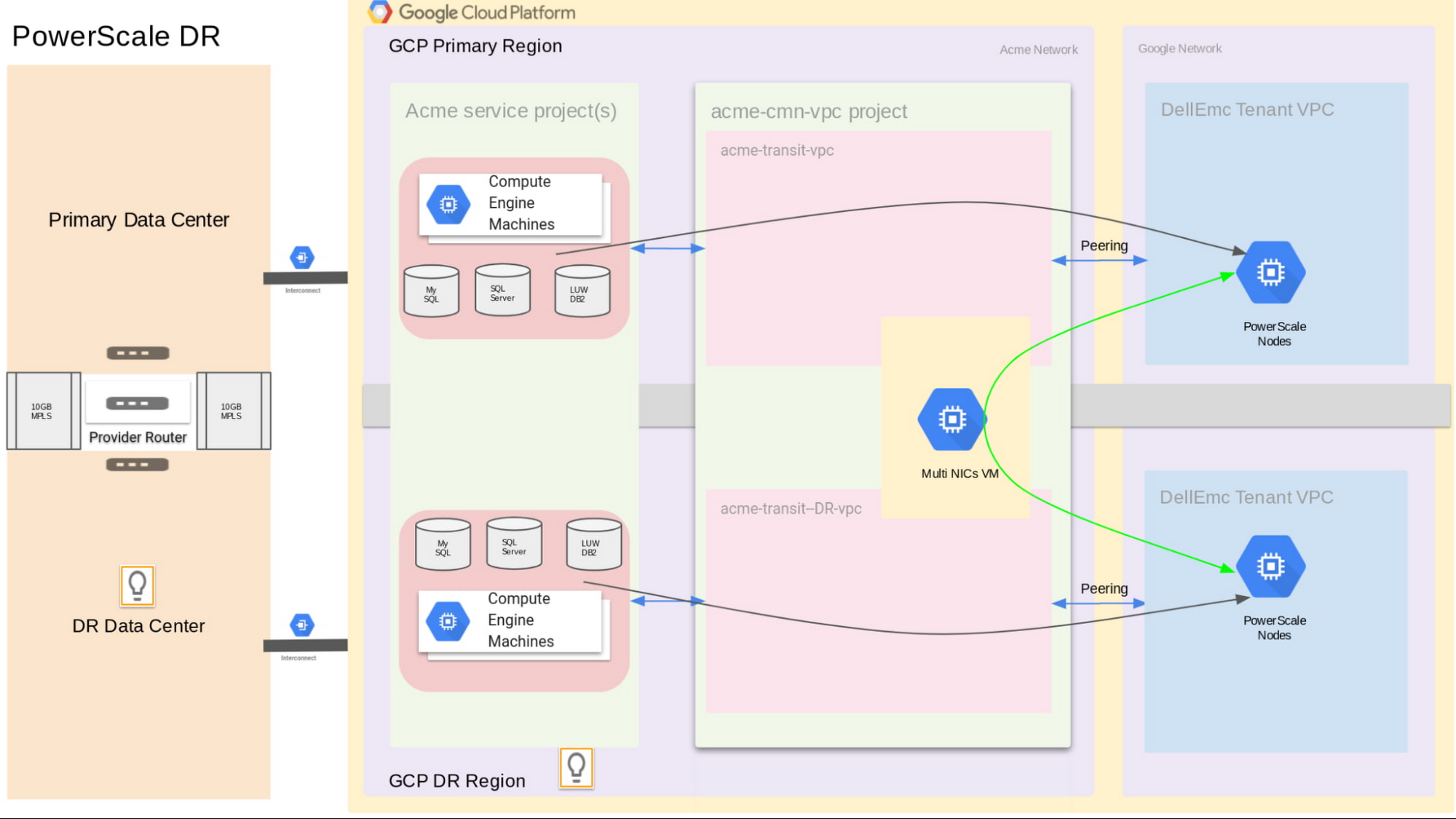
PowerScale (Isilon)
To protect Acme’s PowerScale (Isilon) array, we use Dell EMC Powerscale SyncIQ to replicate data between PowerScale nodes across regions via multi-NICs VM that reside in the primary region but which have a secondary Network Interface (NIC) for the bubble network in the DR region.
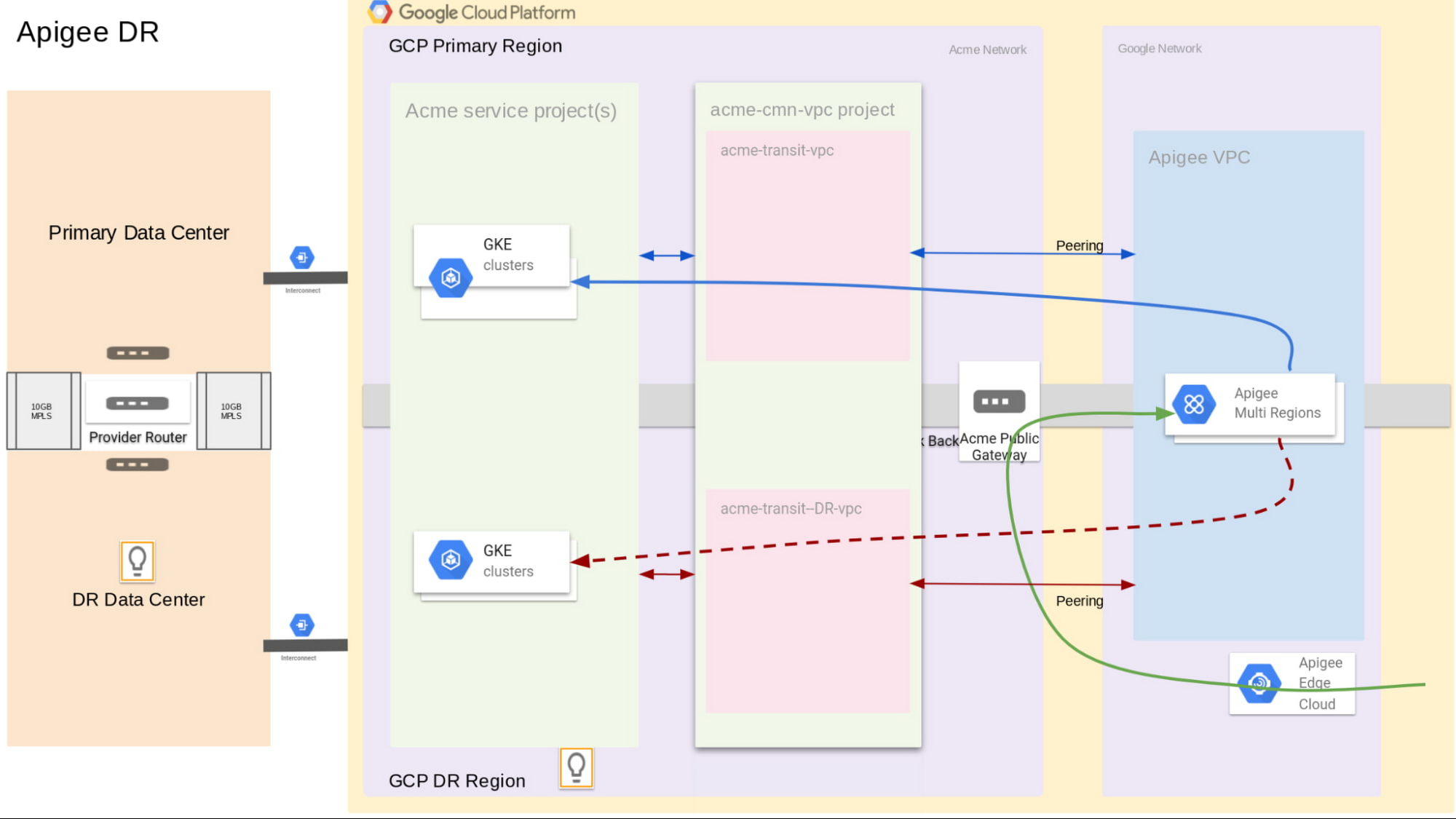
Apigee
Last but not least, we need to protect Acme’s Apigee environment, which it uses for microservices deployed in Google Cloud. Apigee offers a globally redundant level of data centers where traffic can be serviced in multiple regions or countries so that if an entire region goes offline, the data still flows. As shown in the diagram below, with a multi-region Apigee license in place, network traffic can be automatically routed to the disaster recovery region.
Summary
It’s a complicated setup, but that’s not unusual for enterprises looking to migrate a variety of demanding applications to the cloud. You can see our final Acme disaster recovery architecture in the following diagram, with current on-prem DR architecture on the left and Google Cloud DR architecture on the right.
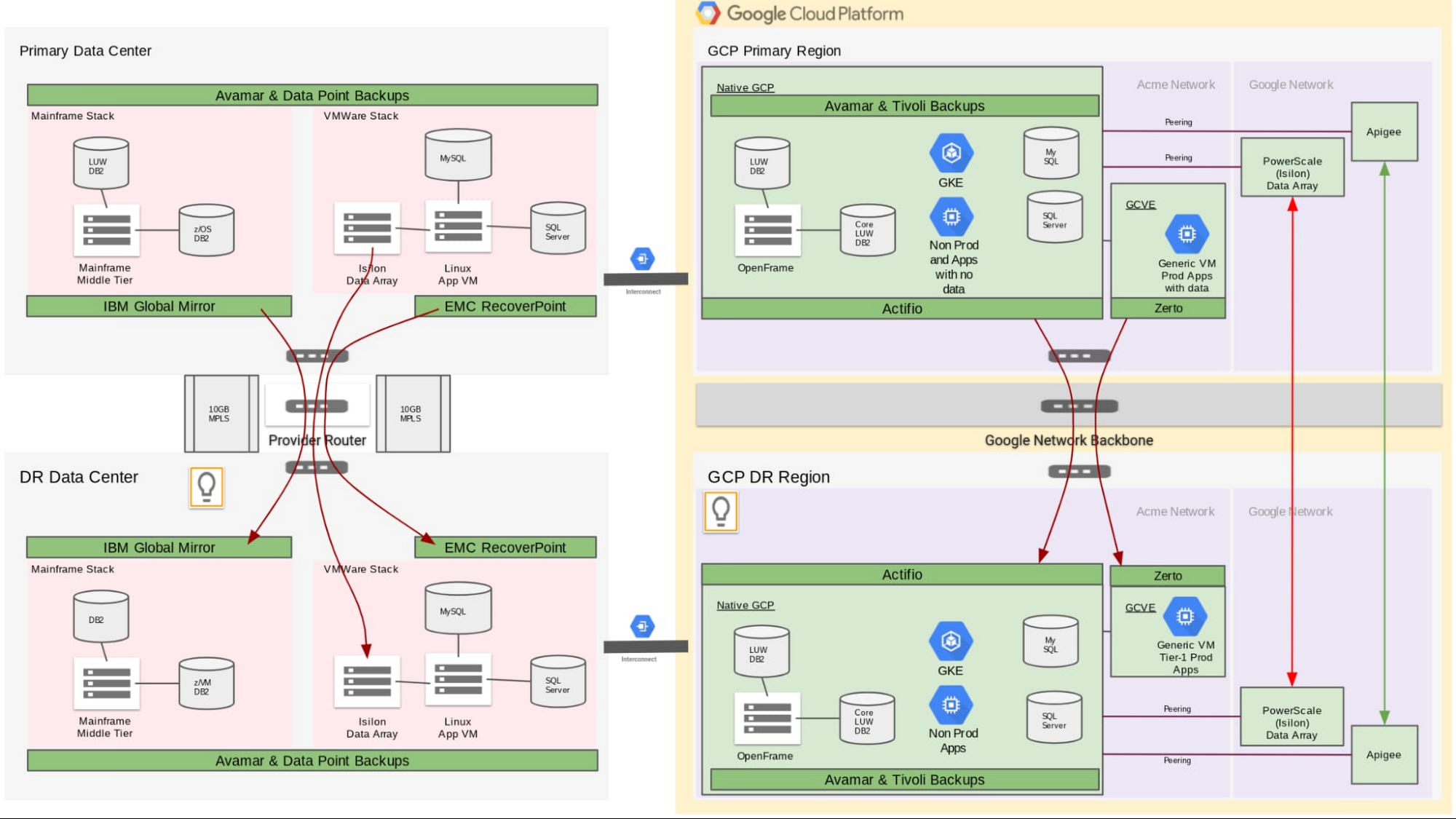
To learn more about how to configure your DR environment for Google Cloud, check out the following documentation: Actifio GO Documentation Library and Configuring disaster recovery using Zerto. Alternatively, please reach out to us—we’d be happy to explore your particular use case with you!
Special thanks to our former colleague Jianhe Liao for his contributions to this blog post.