Cloud Run min instances: Minimize your serverless cold starts
Kelsey Hightower
Principal Engineer
Vinod Ramachandran
Senior Product Manager, Google
One of the great things about serverless is its pay-for-what-you-use operating model that lets you scale a service down to 0. But for a certain class of applications, the not-so-great thing about serverless is that it scales down to 0, resulting in latency to process the first request when your application wakes back up again. This so-called “startup tax” is novel to serverless, since, as the name implies, there are no servers running if an application isn’t receiving traffic.
Today, we’re excited to announce minimum (“min”) instances for Cloud Run, our managed serverless compute platform. This important new feature can dramatically improve performance for your applications. And as a result, it makes it possible to run latency-sensitive applications on Cloud Run, so they too can benefit from a serverless compute platform. Let’s take a deeper look.
Cut your cold starts
With this feature, you can configure a set of minimum number of Cloud Run instances that are on standby and ready to serve traffic, so your service can start serving requests with minimal cold starts.
To use Cloud Run’s new min instances feature, simply configure the number of min instances for your Cloud Run service with a simple gcloud command or the UI.
Once configured, the min instances will be ready and waiting to serve traffic for your application, thereby minimizing the cold starts for your application and enabling you to run latency sensitive applications on Cloud Run.
Reuse bootstrapping logic
In addition to minimizing cold starts, Cloud Run min instances also helps you cut down on bootstrapping time for key operations such as opening database connections or loading files from Cloud Storage into memory. By lowering bootstrapping time, min instances help reduce request latency further, since you only need to run your bootstrapping logic once, and then leverage it across multiple requests for your configured number of min instances.
Consider the following golang serverless function, which shows how you can run your bootstrapping logic once, and reuse it across your min instances:
Run bootstrapping logic once, and reuse it across Min Instances
Reap benefits of serverless at lower cost
In addition to setting a minimum number of instances, Cloud Run min instances also lets you configure them with throttled CPU, so you can take advantage of this capability at a much lower cost. This way, you can have your cake and eat it too: leverage the efficiency and cost advantages of serverless, while moving latency sensitive workloads to serverless.
Cloud Run min instances in action
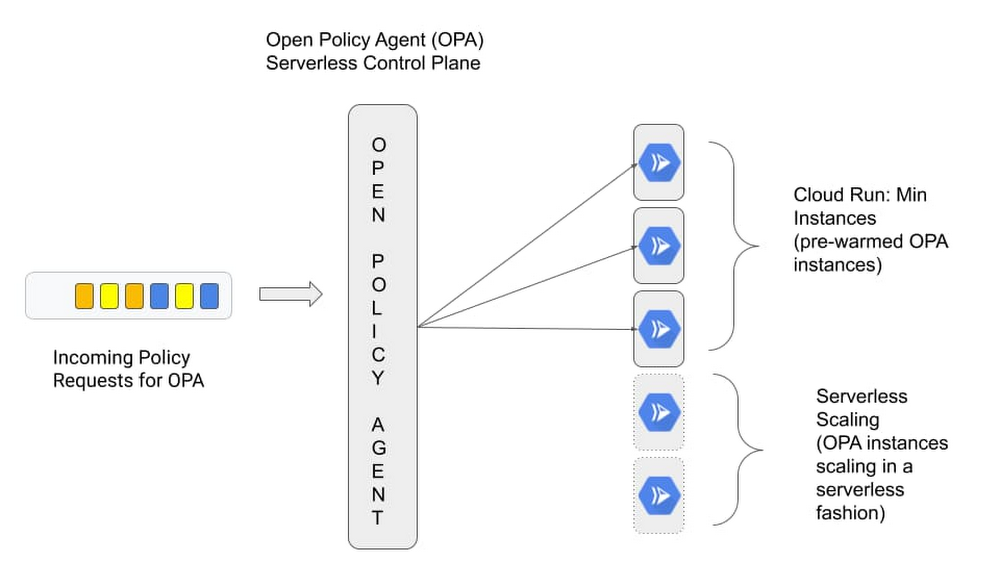
So we talked about the benefits that Cloud Run min instances can bring, and how to use the feature, but how does it work in real life and why would you want to use it?
Traditionally serverless platforms cater to applications that benefit from scaling to zero, but make certain trade offs on initial response times due to cold start latency during the bootstrap period. This is acceptable for applications you’ve built from the ground up and for which you have full control over the source and how it behaves at runtime. But there’s a whole class of applications that people use off the shelf for which a traditional serverless approach isn’t a great fit. Think custom control planes such as Prometheus for collecting metrics and Open Policy Agent (OPA) for making policy decisions. These control planes typically require advanced configuration and a bit of bootstrapping during the initial start up, and can’t tolerate additional latency.
When you’re starting up OPA, for instance, you typically fetch policies from a remote source and cache them to speed up future policy decisions. In a typical serverless environment, control planes such as OPA would take a performance hit when scaling to zero and back up again to handle policy requests, as it sits in the request path for critical user transactions.
Cloud Run min instances allows you to address this problem head on. Instead of scaling to zero and possibly having to bootstrap the policy engine between each request, we can now ensure each request will be handled by a “warm” instance of OPA.
Let's look at this in action. In the following section we deploy OPA to run as a central control plane and enable min instances to meet our performance requirements.
We configure the OPA server to pull a policy bundle from a Cloud Storage bucket at run time, which, when queried will allow http GET requests for the “/health” HTTP path. Here is what the OPA policy looks like:
The policy is packaged in a policy bundle and uploaded to a Cloud Storage bucket. But first, we need to bootstrap some dependencies, as we show in this tutorial about the bootstrapping process. To keep things simple we leverage a helper script.
Change into the min-instances-tutorial directory:
Before we can deploy the OPA Cloud Run instance we need to perform the following tasks:
Create an OPA service account
Create a Cloud Storage bucket to hold the OPA policy bundle
Upload the OPA policy bundle (bundle.tar.gz) to Cloud Storage
Grant permission to the OPA service account to access the OPA bundle
At this point all the dependencies to host OPA are in place. We are ready to deploy OPA using the ‘gcloud’ command. The bucket name and the service account email address are stored in the ‘.env’ file created by the bootstrapping script run in the previous step.
$ source .env
Create the open-policy-agent Cloud Run instance:
Here’s the output from the command, signaling that we’ve successfully bootstrapped our environment:
Now, when the OPA server starts up for the first time, it downloads the policy bundle from Cloud Storage and caches it. But thanks to the min instances, this only happens once.
Now we are ready to test making a policy decision. We can do that with curl. Retrieve the open-policy-agent cloud run URL:
Query the OPA server by providing a set of input and retrieve a policy decision based on the policy bundle stored in Cloud Storage:
Here’s the response:
Now if you wait for a few minutes you’ll observe that OPA does not scale to zero, and that the process is frozen in the background, and will only be thawed when the next request hits the instance. If you would like to learn more about how this affects pricing be sure to check out the Pricing Page.
Min instances for a maximum of applications
At first glance, Cloud Run min instances may seem like a small thing, but we believe that this feature is going to enable more off-the-shelf applications to run under the serverless model and be more cost efficient—and give you more control over the trade-offs inherent in serverless compute. To get started with Cloud Run, check out these Quickstarts.



