Using Pacemaker for SAP high availability on Google Cloud - Part 1
Billy Martin
Technical Solution Engineer
Cherry Legler
Senior Technical Solution Engineer
Problem Statement
Maintaining business continuity of your mission critical systems usually demands high availability (HA) solutions that will failover without human intervention. If you are running SAP HANA or SAP NetWeaver (SAP NW) on Google Cloud, the OS-native high availability (HA) cluster capability provided by Red Hat Enterprise Linux (RHEL) for SAP and SUSE Linux Enterprise Server (SLES) for SAP is often adopted as the foundational functionality to provide business continuity for your SAP system. This blog will introduce some basic terminology and concepts about the RedHat and SUSE HA implementation of Pacemaker cluster software for SAP HANA and NetWeaver platforms.
Pacemaker Terminology
Resource
The resource in Pacemaker is the service made highly available by the cluster. For SAP HANA, there are two resources: HANA and HANA Topology. For SAP NetWeaver Central Services, there are also two resources: one for the Central Services instance that runs the Message Server and Enqueue Server (ASCS in NW ABAP or SCS NW Java) and another one for the Enqueue Replication Server (ERS). In the Pacemaker cluster, we also configure other resources for serving other functions such as Virtual IP (VIP) or Internal Load Balancer (ILB) health check mechanism.
Resource agent
A resource agent manages each resource. It defines the logic for resource operations called by the Pacemaker cluster to start, stop or monitor the health of resources. They are usually Linux bash or python scripts which implement functions for resource agent operations.
Resource agents managing SAP resources are co-developed by SAP and OS vendors. They are open sourced in GitHub, OS vendors downstream to SAP resource agent package for their Linux distro.
For HANA scale up, resource agents “SAPHANA” and “SAPHANATopology”
For HANA scale out, resource agents “SAPHANAController” and “SAPHANATopology”
For NetWeaver Central Services, the resource agent is “SAPInstance”
Why are there two resource agents to manage HANA?
“SAPHanaTopology” is responsible for monitoring HANA topology status on all cluster nodes and updating HANA relevant cluster properties. The attributes are read by “SAPHANA” as part of the HANA monitoring function.
Resource agents are usually installed in the directory `/usr/lib/ocf/resource.d/`.
Resource operation
A resource can have what is called a resource operation. Resource operations are major types of actions: monitor, start, stop, promote, demote. These work as described, for example, if a resource operation is a “promote” operation then it will promote a resource in the cluster. The actions are built into the respective resource agent scripts.
Properties of an operation:
interval - If set to a nonzero value, defines how frequently the operation occurs after the first monitor action completes.
timeout - defines the amount of time the operation has to complete before the operation is aborted and considered failed.
on-fail - defines the action to be executed if the operation fails. The default action for operation ‘stop’ is ‘fence’ and the default for all others is ‘restart’.
role - run the operation only on node that the cluster thinks should be in the specified role. A role can be master or slave, started or stopped. The role provides context for pacemaker to make resource location and operation decisions.
Resource group
Resource agents can be grouped into administrative units that are dependent on one another and need to be started sequentially and stopped in the reverse order.
While technically each cluster resource is failed over one at a time, logically (to simplify cluster configuration) failover of resource groups is configured. For SAP HANA, for example, there is typically one resource group containing both the VIP resource and the ILB healthcheck resource.
Resource constraints
Constraints determine the behavior of a resource in a cluster. Categories of constraints are location, order and colocation. The list below includes the constraints in SLES and RHEL.
Location Constraint - determines on which nodes a resource can run; e.g., pins each fence device to the other host VM.
Order Constraint - determines the order in which resources run; e.g., first start resource SAPHANATopology then start resource SAPHANA.
Colocation Constraint - determines that the location of one resource depends on the location of another resource; e.g., the IP address resource group should be on the same host as the primary HANA instance.
Fencing and fence agent
A fencing or fence agent is an abstraction that allows a Pacemaker cluster to isolate problematic cluster nodes or cluster resources for which the state cannot be determined. Fencing can be performed at either the cluster node level or at the cluster resource/resource group level. Fencing is most commonly performed at the cluster node level by remotely power cycling the problematic cluster node or by disabling its access to the network.
Similar to resource agents, these agents are also usually bash or python scripts. The two commonly used fence agents within GCP are “gcpstonith” and “fence_gce”, with “fence_gce” being the more robust successor of “gcpstonith”. Fence agents leverage the compute engine reset API in order to fence problematic nodes.
The fencing resource “gcpstonith” is usually downloaded and saved in the directory `/usr/lib64/stonith/plugins/external` . The resource “fence_gce” comes with the RHEL and SLES images with the HA extension.
Corosync
Corosync is an important piece of a Pacemaker cluster whose effect on the cluster is often undervalued. Corosync enables servers to interact as a cluster, while Pacemaker provides the ability to control how the cluster behaves. Corosync provides messaging and membership functionality along with other functions:
Maintains the quorum information.
Is used by all cluster nodes to communicate and coordinate cluster tasks.
Stores the default location of the Corosync configuration: /etc/corosync/corosync.conf
If there is a communication failure or timeout within Corosync then there will be a membership change or fencing action performed.
Clones and Clone Sets
Clones represent resources that can become active on multiple hosts without requiring the creation of unique resource definitions for them.
When resources are grouped across hosts, we call this a clone set. There are different types of cloned resources. The main clone set of interest for SAP configurations is that of a stateful clone, which represents a resource with a particular role. In the context of the SAP HANA database, the primary and secondary database instances would be contained within the SAPHana clone set.
Conclusion
Now that you have read through the terminology, let's see how an SAP Pacemaker cluster looks on each OS:
SLES:
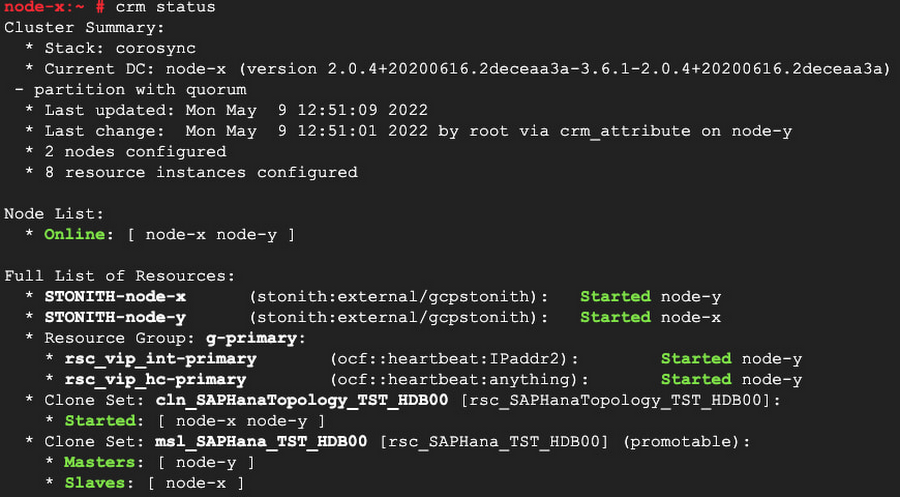
There are have two nodes in the cluster and both are online
* Online: [ node-x node-y ]
The STONITH resource is started on each node and is using the “gcpstonith" fence agent
* STONITH-node-x (stonith:external/gcpstonith): Started node-y
* STONITH-node-y (stonith:external/gcpstonith): Started node-x
There is a resource group called g-primary that contains both the IPAddr2 resource agent, which adds the ILB forwarding rule IP address to the NIC of the active node, and the anything resource agent, which starts a program ‘socat’ to respond to ILB health check probes:
* rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started node-y
* rsc_vip_hc-primary (ocf::heartbeat:anything): Started node-y
There is a Clone Set for the SAPHANATopology resource agent containing the two nodes:
cln_SAPHanaTopology_TST_HDB00 [rsc_SAPHanaTopology_TST_HDB00]
There is a Clone Set for the SAPHANA resource agent containing a master and slave node:
* Clone Set: msl_SAPHana_TST_HDB00 [rsc_SAPHana_TST_HDB00] (promotable)
Note: You can see that one of the clone sets is marked as promotable. If a clone is promotable, its instances can perform a special role that Pacemaker will manage via the promote and demote operations of the resource agent.
RHEL:
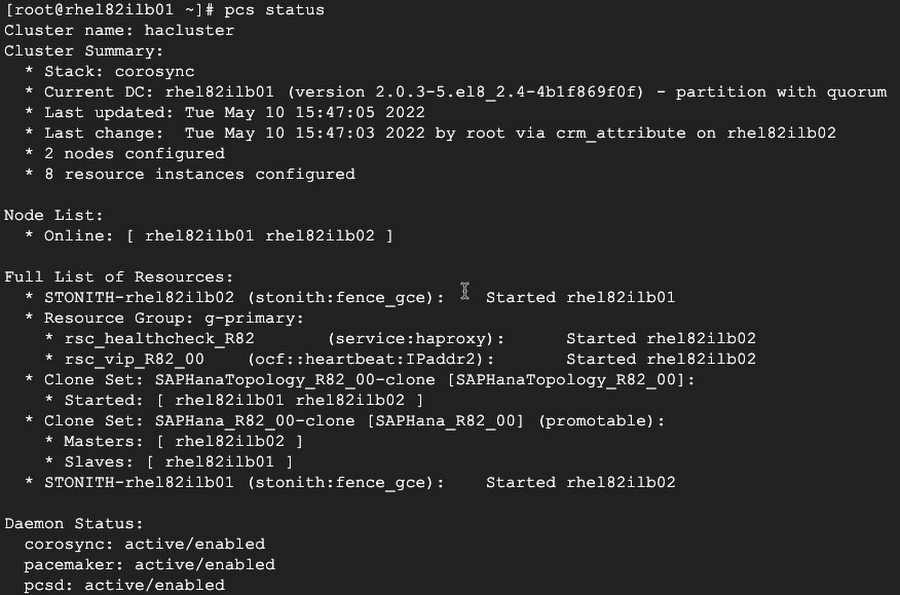
There are two nodes in the cluster and both are online:
* Online: [ rhel182ilb01 rhel182ilb02 ]
The STONITH resource is started on the opposite node and is using the more robust “fence_gce" fence agent:
STONITH-rhel182ilb01 (stonith:fence_gce): Started rhel182ilb02
STONITH-rhel182ilb02 (stonith:fence_gce): Started rhel182ilb01
There is a resource group called g-primary that contains both the IPAddr2 resource agent, which adds the ILB forwarding rule IP address to the NIC of the active node, and the haproxy resource agent, which starts a program ‘haproxy’ to respond to ILB health check probes:
* rsc_healthcheck_R82 (service:haproxy): Started rhel182ilb02
* rsc_vip_R82_00 (ocf::heartbeat:IPaddr2): Started rhel182ilb02
There is a Clone Set for the SAPHanaTopology resource agent containing the two nodes:
* Clone Set: SAPHanaTopology_R82_00-clone [SAPHanaTopology_R82_00]
There is a Clone Set for the SAPHana resource agent containing a master and slave node:
* Clone Set: SAPHana_R82_00-clone [SAPHana_TST_HDB00] (promotable)
If you compare both SLES and RHEL clusters above, even though they are completely different clusters, you can see the similarities and technologies which are used to perform cluster operations.
Congratulations. Now you should have a firm grasp of the key areas and terms of a SAP Cluster running on Google Cloud Platform.
Where to go from here? Learn more about running SAP on Google Cloud in our public documentation or review the other blogs in this series to become an expert in understanding your Pacemaker cluster and its behavior:



