Google Cloud networking in depth: How Andromeda 2.2 enables high-throughput VMs
Philip Wells
Software Engineer, Google Madison
Manoj Jayadevan
Group Product Manager, Networking
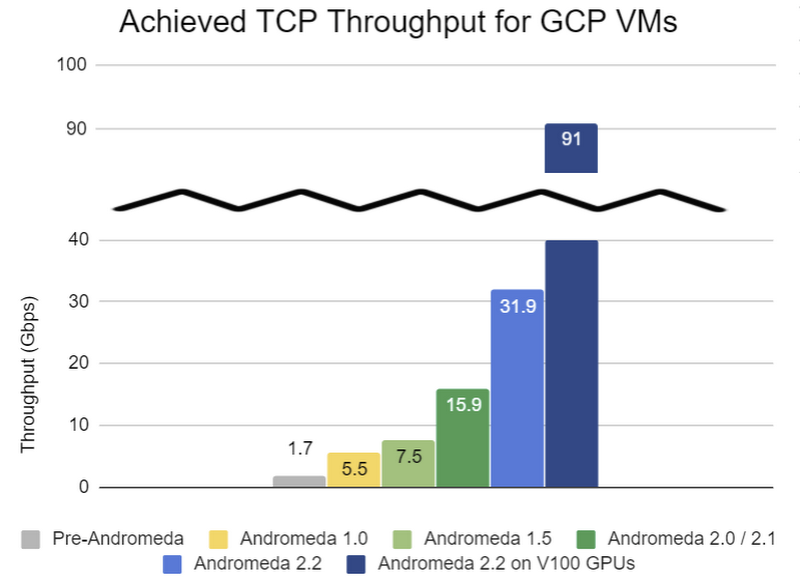
Here at Google Cloud, we’ve always aimed to provide great network bandwidth for Compute Engine VMs, thanks in large part to our custom Jupiter network fabric and Andromeda virtual network stack. During Google Cloud Next ‘19, we improved that bandwidth even further by doubling the maximum network egress data rate to 32 Gbps for common VM types. We also announced VMs with up to 100 Gbps bandwidth on NVIDIA V100 and T4 GPU accelerator platforms—all without raising prices or requiring you to use premium VMs.
Specifically, for any Skylake or newer VM with at least 16 vCPUs, we raised the egress bandwidth cap to 32 Gbps for same-zone VM-to-VM traffic; this capability is now generally available. This includes n1-ultramem VMs, which provide more compute resources and memory than any other Compute Engine VM instance type. There is no additional configuration needed to get that 32 Gbps throughput.
Meanwhile, 100 Gbps Accelerator VMs are in alpha, soon in beta. Any VM with eight NVIDIA V100 or four T4 GPUs attached will have bandwidth caps raised to 100 Gbps.
These high-throughput VMs are ideal for running compute-intensive workloads that also need a lot of networking bandwidth. Some key applications and workloads that can leverage these high-throughput VMs are:
High-performance computing applications, batch processing, scientific modeling
High-performance web servers
Virtual network appliances (firewalls, load balancers)
Highly scalable multiplayer gaming
Video encoding services
Distributed analytics
Machine learning and deep learning
In addition, services built on top of Compute Engine like CloudSQL, Cloud Filestore and some partner solutions can leverage 32 Gbps throughput already.
One use case that is particularly network- and compute-intensive is distributed machine learning (ML). To train large datasets or models, ML workloads use a distributed ML framework, e.g., TensorFlow. The dataset is divided and trained by separate workers, which exchange model parameters with each other. These ML jobs consume substantial network bandwidth due to large model size and frequent data exchanges among workers. Likewise, the compute instances that run the worker nodes create high throughput requirements for VMs and the fabric serving the VMs. One customer, a large chip manufacturer, leverages 100 Gbps GPU-based VMs to run these massively parallel ML jobs, while another customer uses our 100 Gbps GPU machines to test a massively parallel seismic analysis application.
Making it all possible: Jupiter and Andromeda
Our highly-scalable Jupiter network fabric and high-performance, flexible Andromeda virtual network stack are the same technologies that power Google’s internal infrastructure and services.
Jupiter provides Google with tremendous bandwidth and scale. For example, Jupiter fabrics can deliver more than 1 Petabit/sec of total bisection bandwidth. To put this in perspective, this is enough capacity for 100,000 servers to exchange information at a rate of 10 Gbps each, or enough to read the entire scanned contents of the Library of Congress in less than 1/10th of a second.
Andromeda, meanwhile, is a Software Defined Networking (SDN) substrate for our network virtualization platform, acting as the orchestration point for provisioning, configuring, and managing virtual networks and in-network packet processing. Andromeda lets us share Jupiter networks for many different uses, including Compute Engine and bandwidth-intensive products like Cloud BigQuery and Cloud Bigtable.
Since we last blogged about Andromeda, we launched Andromeda 2.2. Among other infrastructure improvements, Andromeda 2.2 features increased performance and improved performance isolation through the use of hardware offloads, enabling you to achieve the network performance you want, even in a multi-tenant environment.
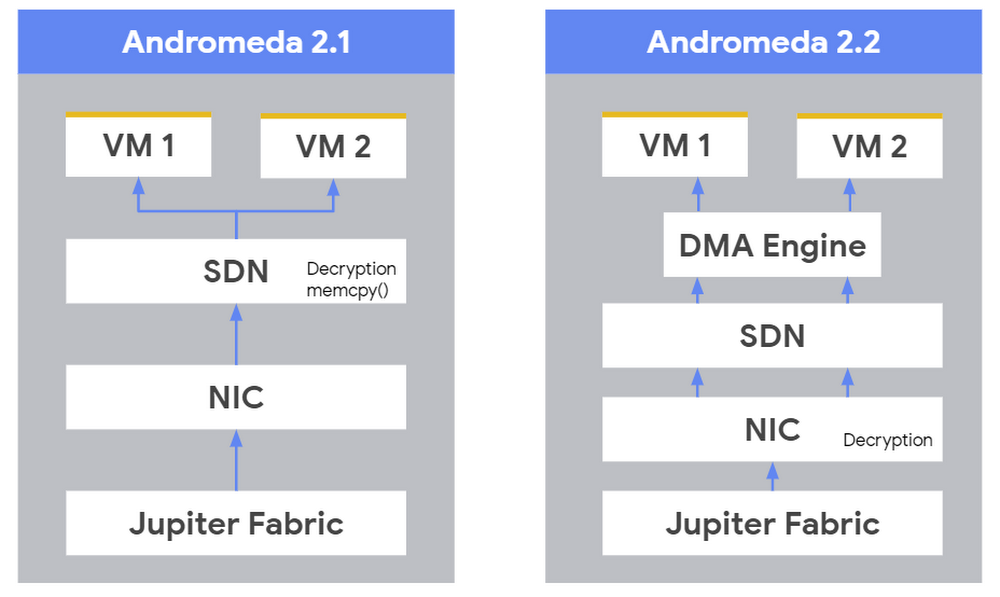
Increasing performance with offload engines
In particular, Andromeda now takes full advantage of the Intel QuickData DMA Engines to offload payload copies of larger packets. Driving the DMA hardware directly from our OS-bypassed Andromeda SDN enables the SDN to spend more time processing packets rather than moving data around. We employ the processor's IOMMU to provide security and safety isolation for DMA Engine copies.
In Google Cloud Platform (GCP), we encrypt all network traffic in transit that leaves a physical boundary not controlled by Google or on behalf of Google. Andromeda 2.2 now utilizes special-purpose network hardware in the Network Interface Card (NIC) to offload that encryption, freeing the host machine's CPUs to run guest vCPUs more efficiently.
Furthermore, Andromeda's unique architecture allows us to offload other virtual network processing to hardware opportunistically, improving performance and efficiency under the hood without requiring the use of SR-IOV or other specifications that tie a VM to a physical machine for its lifetime. This architecture also enables us to perform a "hitless upgrade" of the Andromeda SDN as needed to improve performance, add features, or fix bugs.
Combined, these capabilities have allowed us to seamlessly upgrade our network infrastructure across five generations of virtual networking—increasing VM-to-VM bandwidth by nearly 18X (and more than 50X for certain accelerator VMs) as well as reducing latency by 8X—all without introducing downtime for our customers.
Performance isolation
All that performance is meaningless if your VM is scheduled on a host with other VMs that are overloading or abusing the network and preventing your VM from achieving the performance you expect. Within Andromeda 2.2, we've made several improvements to provide isolation, ensuring that each VM receives its expected share of bandwidth. Then, for the rare cases when too many VMs are trying to push massive amounts of network traffic simultaneously, we reengineered the algorithm to optimize for fairness.
For VM egress traffic, we schedule the act of looking for work on each VM's transmit queues such that each VM gets its fair share of bandwidth. If we need to throttle a VM because it has reached its network throughput limits, we provide momentary back-pressure to the VM, which causes a well-behaved guest TCP stack to reduce its offered load slightly without causing packet loss.
For VM ingress traffic, we use offloads in the NIC to steer packets into per-VM NIC receive queues. Then, similarly to egress, we look for work on each of those queues in proportion to each VM’s fair share of network bandwidth. In the rare event that a VM is receiving an excessive amount of traffic, its per-VM queue fills up and eventually starts dropping packets. Those drops will again cause a well-behaved TCP connection, originating perhaps from another VM or the internet, to back off slightly, preserving performance for that connection. A VM with a badly behaved connection might not back off, due possibly to bugs in a customer's workload, or even malicious intent. Either way, per-VM receive queues mean we don't need to drop packets for other VMs on the host, protecting those VMs from the performance pathologies of a bad actor.
You can never have too good a network
At Google we’re constantly working to improve the performance and reliability of our network infrastructure. Stay tuned for new networking advances from Google Cloud, including low-latency products focused on HPC use cases, and even higher bandwidth VMs.



