Otto Group CLASH: an open-source tool to run bash scripts directly on GCP
Dr. Mahmoud Reza Rahbar Azad
Otto Group data.works GmbH
Mike Czech
Otto Group
Editor’s note: Founded in Germany in 1949, today the Otto Group is a globally active retail and services group with around 51,800 employees and generated revenues of 13.7 billion euros. Today, business intelligence experts Dr. Mahmoud Reza Rahbar Azad and Mike Czech describe an open-source tool they built to run bash-based data processing scripts directly in Google Cloud. Read on to learn why they built it, how they built it, and how you can use it in your own environment.
We here at Otto Group Business Intelligence build machine learning and data-driven products for online retailers such as otto.de or aboutyou.de, to enhance our customers’ user experience. A part of that is a big data lake that we recently migrated to Google Cloud Platform (GCP). As data engineers, we sometimes need to perform data processing jobs. Since these jobs can take a long time or require a lot of compute power, we didn’t want to perform these tasks on a local machine or via a web frontend: we wanted a tool that uses the full power of GCP.
A few months back, we were at a point where we understood our requirements but couldn’t find a good tool to fulfill them. So we built it ourselves: During a recent internal hacking day, we wrote CLoud bASH, or CLASH, which takes a bash script as an input and simply runs it inside a cloud environment.
Running scalable data processing scripts in the cloud
Before we dive into the nitty gritty details, let me give you a little bit of a background about what we do and why we built CLASH.
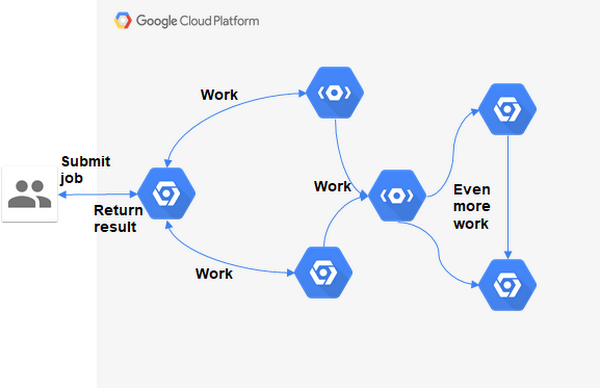
As mentioned above, we needed a tool that takes a bash script as an input and simply runs it inside a cloud environment. The user should have the option to either wait for the result or to be notified asynchronously when the job is finished. If the user waits for the result, log messages from the script should be forwarded to the user console and the user can cancel the job execution. This feature comes in very handy during fast development iteration cycles.
The following image illustrates what we roughly had in mind.
How we built it
We quickly came up with two implementations built on GCP. The first one was based on Google Kubernetes Engine (GKE), the other on Google Compute Engine. We expected the GKE variant to be a simple 'one size fits all' solution, whereas Compute Engine to be more customizable, allowing us, for instance, to attach a GPU to the compute unit, for additional performance.
Since Kubernetes already brings a lot of scheduling primitives to the table, it was very easy to get a prototype up and running quickly. The following image shows the CLASH architecture running on GKE:
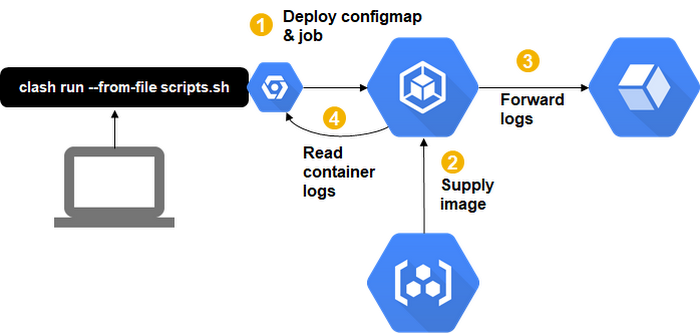
The user calls the CLASH CLI to submit the scripts.sh job. Internally, CLASH utilises the gcloud CLI to spin up a Kubernetes cluster and afterwards uses kubectl to deploy the contents of the script as a ConfigMap as well as a Kubernetes job. The container logs of the job are automatically saved to Stackdriver as well as forwarded to the user’s terminal via kubectl logs. For example, here is a simple “hello world” example in the terminal:
While this architecture fulfilled our requirements, it had some drawbacks. Not every user has a Kubernetes cluster lying around, so we had to spin up a cluster every time we wanted to run a job, which actually can take quite a while. Secondly, if a job only needs an individual node, we end up with a single-node node-pool. But what if a second job has different resource requirements? We would try to reuse the same cluster, but had to create again a second single-node node-pool. So while Kubernetes’ orchestration features are very nice, we switched gears and chose to go with the more straightforward Compute Engine approach.
Here is the CLASH architecture on Compute Engine.
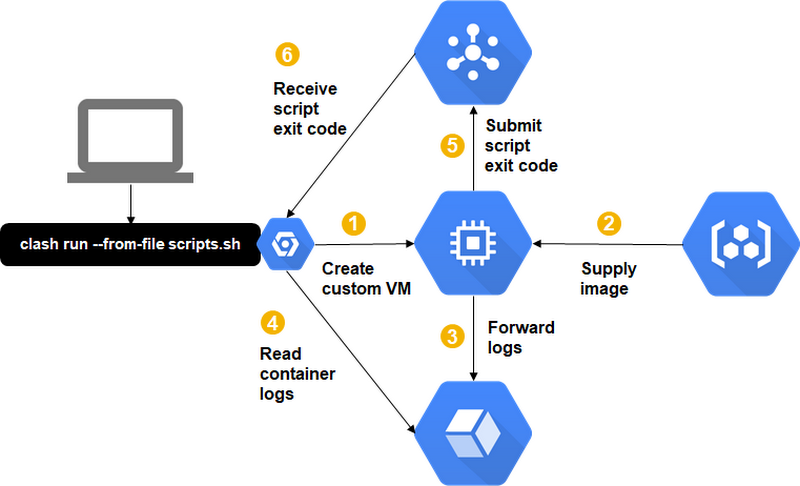
From the user perspective, the functionality of this approach is the same as before, but this time, instead of spinning up a Kubernetes node, it spawns a GCE instance. We take care that the VM has the Docker engine installed so that the bash script can run again inside a docker container—more on this later. Then, since doing SSH into a machine is considered undesired overhead, we also decided not to integrate CLASH with a PKI. Instead, we use Cloud Pub/Sub to get notified about the result of a job and Stackdriver for the job logs. After the job finishes we initiate an automatic VM shutdown.
We also reused the clash init function that we developed for the GKE-based deployment. The init command creates a configuration file where you can tune a lot of aspects when executing a CLASH job. A basic configuration file looks like this:
The most prominent configuration is the machine_type which lets you specify how much resources the Compute Engine instance should provide, as well as basic region and networking configurations. Because CLASH needs Docker as well as the gcloud CLI present on the target machine, the fields disk_image and container_image are pre-populated accordingly. The actual script can then be deployed via cloud-init without any SSH connection to the machine. Another feature we built early on in CLASH is templating support for the configuration file using Jinja2. With this feature you can reuse the same configuration and overwrite single fields via an environment variable as shown in the example configuration with MACHINE_TYPE and PROJECT_ID.
Using this design led to good results. Altogether the time to provision the infrastructure is between three and five minutes, which is manageable. For repetitive jobs we added the option to reuse an instance by specifying an instance-id. We noticed that the implementation of a job scheduling feature in the way of Kubernetes cron jobs was quite a hassle, so we dropped it for now—especially given the fact that GCP offers great services like Cloud Scheduler and Cloud Tasks.
Using CLASH in the wild
Now let's dive into some use cases.
One of the early use cases for CLASH was to run data synchronization jobs for BigQuery, running a script to shovel data via the bq command-line tool from one source to another. Nowadays this use case is covered by BigQuery’s scheduling feature, but that wasn’t available to us at the time. Even though the bq command is quite simple, it can also take quite a long time to complete, making it a poor fit for using Cloud Functions.
Another use case is importing compressed data from a Google Cloud Storage bucket. We have set up a data importing pipeline where a new archive in a bucket triggers a cloud function which then triggers CLASH in detached mode to call the actual importing script. The script then unpacks the archive, performs some consistency checks, potentially does some data filtering and cleaning, and finally archives the result back into the target bucket.
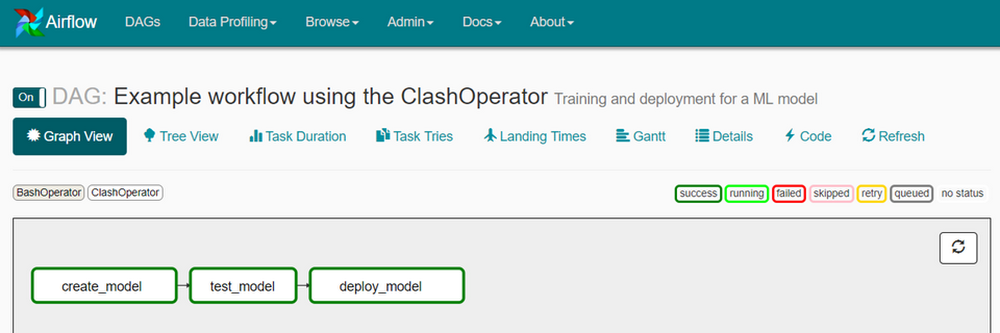
Finally, yet another use case for CLASH is specific to data scientists, namely model training. When we push new code to a model repository, we want to be able to perform regression tests for different model versions, so we have to train the model against a dataset. For obvious reasons we don't want to do this in our CI environment, so we use CLASH to spin up a high-mem instance, perform the model training and save the model in a bucket where we can pick it up later for further investigation. We built this workflow with Google Cloud Composer, integrated CLASH via a ComputeEngineJobOperator into Airflow, and then used it in our Airflow pipelines.
An example pipeline with the corresponding DAG definition looks like this:
As mentioned, we use Cloud Pub/Sub to notify CLASH once a job has finished. Hence it is possible to subscribe a cloud function to the model training topic and on a successful event, trigger another CLASH job that does the regression test automatically. This is something we are currently thinking about. This also shows the potential of building workflows by combining CLASH with existing Google Cloud services.



