We tested Intel’s AMX CPU accelerator for AI. Here’s what we learned
Erdem Aktas
Staff Software Engineer
Zhimin Yao
Staff Software Engineer
At Google Cloud, we believe that cloud computing will increasingly shift to private, encrypted services where users can be confident that their software and data are not being exposed to unauthorized actors. In support of this goal, our aim is to make confidential computing technology ubiquitous across our Cloud without compromising usability, performance, and scale.
The latest C3 Confidential VMs we’ve developed with Intel have a built-in, on by default accelerator: Intel AMX. Intel AMX improves the performance of deep-learning training and inference on the CPU, and is ideal for workloads including natural-language processing, recommendation systems, and image recognition.
These Confidential VMs leverage confidential computing technology called Intel Trust Domain Extensions (Intel TDX). Confidential VMs with Intel TDX can help safeguard against insider attacks and software vulnerabilities and ensure data and code confidentiality and integrity. Together, Intel’s AMX and TDX technologies can make it easier for customers to secure their AI inference, fine tuning, and small-to-medium sized training jobs.
“We are excited to partner with Google, delivering Confidential Computing and AI acceleration on C3 instances with Intel TDX and Intel AMX and software acceleration available in the popular AI libraries, to democratize access to secured, accelerated computing,” Andres Rodriguez, Intel Fellow and datacenter AI architect.
Performance testing AI/ML workloads on Confidential VMs
We know that sometimes performance concerns arise when security extensions are enabled, so we conducted ML training and inference experiments to evaluate the performance of Confidential VMs with Intel TDX and Intel AMX.
For our experiments, we compared three VMs that were the largest machine types by vCPU available:
- N2 VM: N2 machine series VMs that do not have Intel AMX or Intel TDX enabled.
- C3 VM: C3 machine series VMs that only have Intel AMX enabled.
- C3+TDX VM: C3 machine series VMs have both Intel TDX and Intel AMX enabled.
AI Training findings
We compared the training time (in minutes) on the aforementioned N2, C3, and C3+TDX VMs. Compared to the N2 VM, the C3 VM provided a 4.54x speedup on training time whereas the C3+TDX VM provided a 4.14x speedup on training time for one workload, with the same hyperparameters such as global batch size and on-par quality metrics.
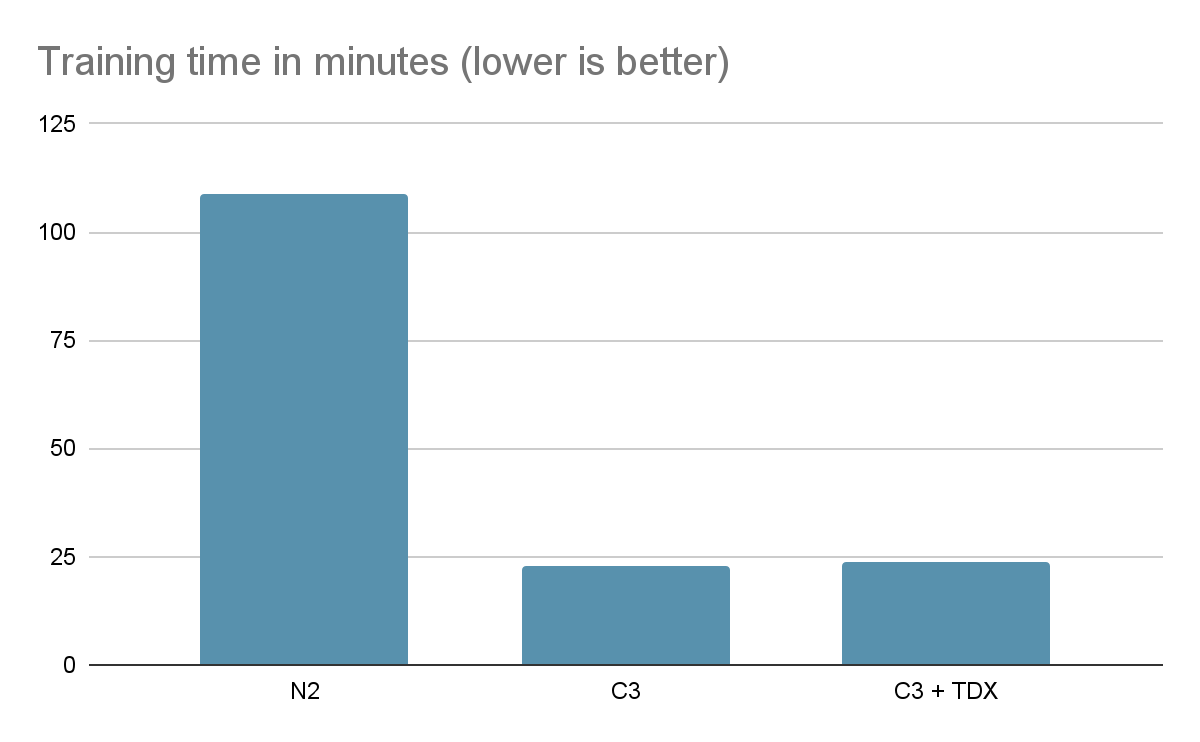
Training time by virtual machine.
We found that workloads running in Confidential VMs with Intel TDX may experience some performance overhead. A greater batch size may speed up training and reduce the Intel TDX overhead. This is due to reduced memory encryption cost involved in I/O operations, given the same amount of ingested data.
AI Inference findings
We saw similar improvements on inference workloads using Intel AMX and observed some performance overhead from Intel TDX.
We ran a text generation task on two LLMs, Llama-2-7B and Llama-2-13B. Using the aforementioned N2, C3, and C3+TDX VMs, we evaluated task performance based on two metrics:
- Time Per Output Token (TPOT): Time to generate an output token for a single request. This metric corresponds to how a user would perceive the "speed" of the model. For example, a TPOT of 100 milliseconds per token would be approximately 450 words per minute (WPM), which is faster than an average person’s reading speed.
- Throughput (token per sec): The number of output tokens per second an inference server can generate for batch requests.
We compared the N2 VM to C3 and C3+TDX VMs and found that Intel AMX on the C3 VM and C3+TDX VM provided a speedup of approximately a three-fold improvement in latency (TPOT with a batch size of one) and approximately a seven-fold increase in throughput (with a batch size of six).
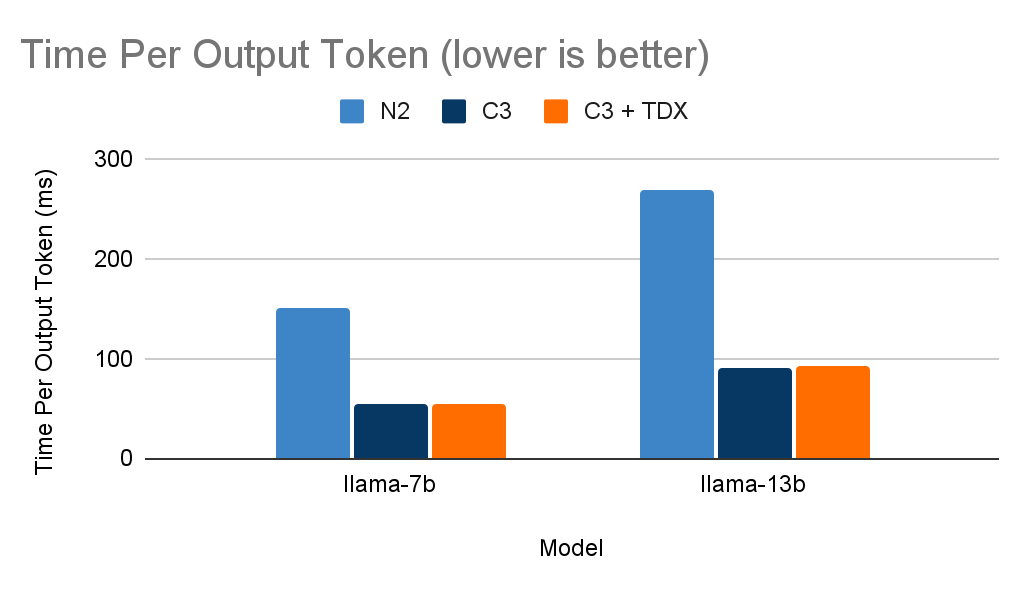
Time per output token by virtual machine.
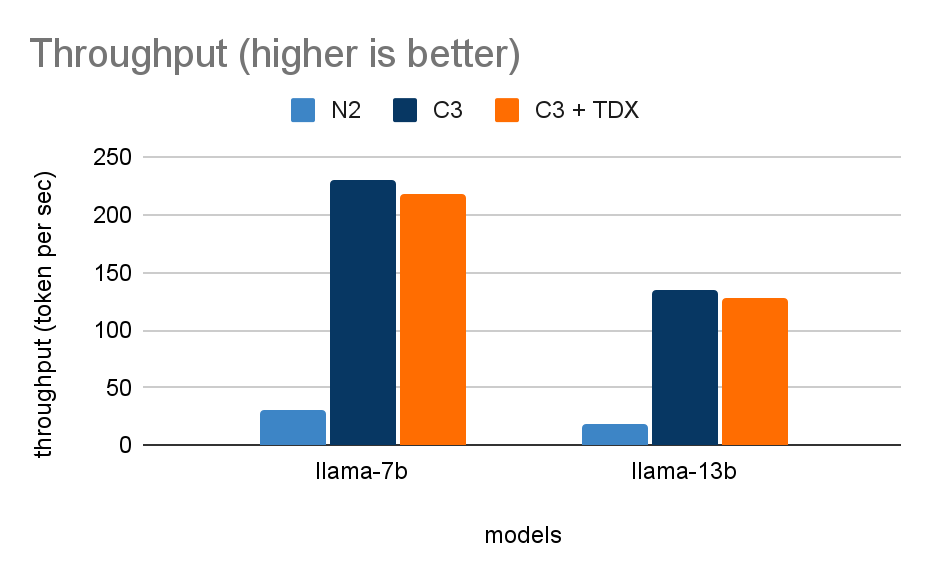
Throughput by virtual machine.
Try Intel AMX on Confidential VMs today
For a full report on our testing and results, read our whitepaper here. You can collect your own benchmarks for LLMs by following the Intel® Extension for PyTorch instructions. Learn more about Google Cloud’s Confidential Computing products here, and get started today with your own confidential VMs using Intel AMX and TDX.


