[Infographic] Achieving Autonomic Security Operations: Why metrics matter (but not how you think)
Tim Nguyen
Director, Detection and Response, Google
Anton Chuvakin
Security Advisor, Office of the CISO
What’s the most difficult question a security operations team can face? For some, is it, “Who is trying to attacks us?” Or perhaps, “Which cyberattacks can we detect?” How do teams know when they have enough information to make the “right” decision? Metrics can help inform our responses to those questions and more, but how can we tell which metrics are the best ones to rely on during mission-critical or business-critical crises?
As we discussed in our blogs, “Achieving Autonomic Security Operations: Reducing toil” and “Achieving Autonomic Security Operations: Automation as a Force Multiplier,” your Security Operations Center (SOC) can learn a lot from what IT operations discovered during the Site Reliability Engineering (SRE) revolution. In this post, we discuss how those lessons apply to your SOC, and center them on another SRE principle—Service Level Objectives (SLOs).
Even though industry definitions can vary for these terms, SLI, SLO, and SLA have specific meanings, wrote the authors of the Service Level Objectives chapter in our e-book, “Site Reliability Engineering: How Google runs production systems.” (All subsequent quotes come from the SLO chapter of the book, which we’ll refer to as the “SRE book.”)
SLI: “An SLI is a service level indicator—a carefully defined quantitative measure of some aspect of the level of service that is provided.”
SLO: “An SLO is a service level objective: a target value or range of values for a service level that is measured by an SLI.”
SLA: An SLA is a Service Level Agreement about the above: “an explicit or implicit contract with your users that includes consequences of meeting (or missing) the SLOs they contain.”
In practice, we measure something (SLI) and we set the target value (SLO); we may also have an agreement about it (SLA).
This is not about cliches like “what gets measured gets done” here, but metrics and SLIs/SLOs will to a large extent determine the fate of your SOC. For example, SOCs (including at some Managed Security Service Providers) that obsessively focus on “time to address the alert” end up reducing their security effectiveness while making things go "whoosh" fast. If you equate mean time to detect or discover (MTTD) with “time to address the alert” and then push the analyst to shorten this time, attackers gain an advantage while defenders miss things and lose.
How to choose which metrics to track
One view of metrics would be that “whatever sounds bad” (such as attacks per second or incidents per employee) needs to be minimized, while “whatever sounds good” (such as successes, reliability, or uptime) needs to be maximized.
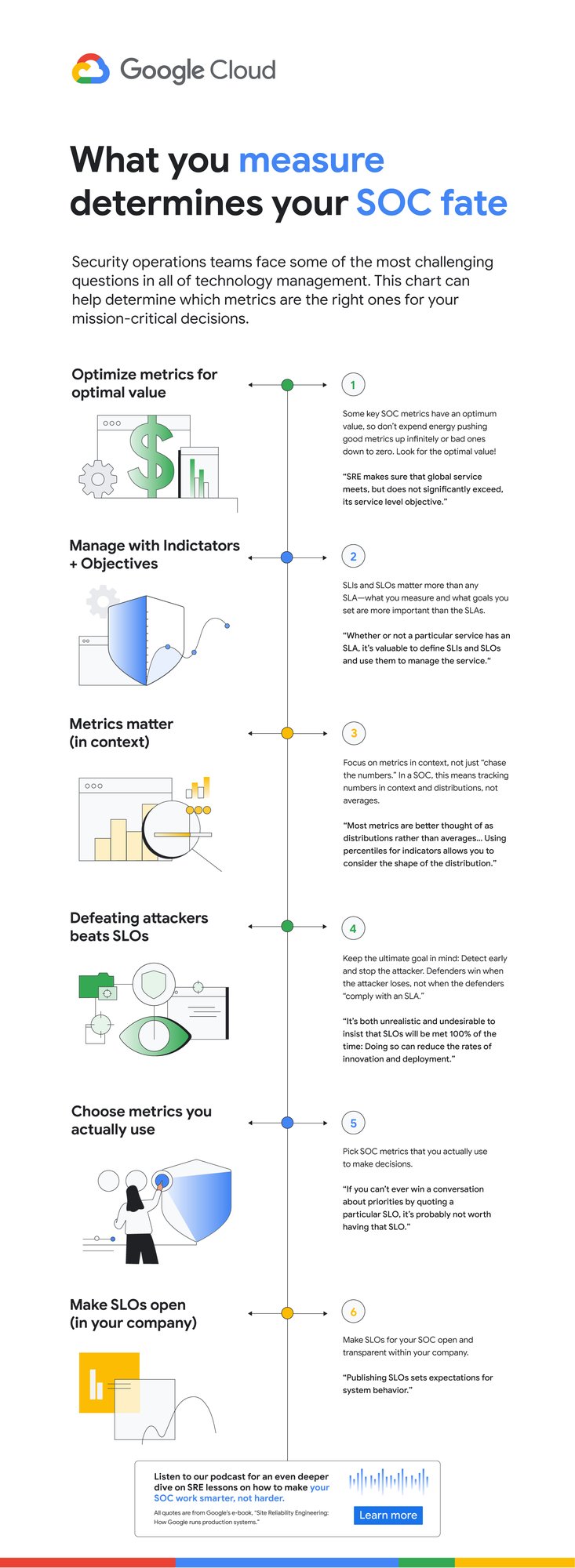
But the SRE experience is that sometimes good metrics have an optimum level, and yes, even reliability (and maybe even security). The book’s authors, Chris Jones, John Wilkes, and Niall Murphy with Cody Smith, cite an example of a service that defied common wisdom and was too reliable.
“Its high reliability provided a false sense of security because the services could not function appropriately when the service was unavailable, however rarely that occurred... SRE makes sure that global service meets, but does not significantly exceed, its service level objective,” they wrote.
The SOC lesson here is that some security metrics have optimum value. The above-mentioned time to detect has an optimum for your organization. Another example is the number of phishing incidents, which may in fact have an optimum value. If nobody phishes you, it’s probably because they already have credentialed access to many of your systems – so in your SOC, think of SLI optimums, and don't automatically assume zero or infinite targets for metrics.
Three specific quotes from the SRE book remind us that “good metrics” may need to be balanced with other metrics, rather than blindly pushed up:
“User-facing serving systems generally care about availability, latency, and throughput.”
“Storage systems often emphasize latency, availability, and durability.”
“Big data systems, such as data processing pipelines, tend to care about throughput and end-to-end latency.”
In a SOC, this may mean that you can detect threats quickly, review all context related to an incident, and perform deep threat research—but the results may differ for various threats. A fourth guidepost explains why your SOC should care even about this: “Whether or not a particular service has an SLA, it’s valuable to define SLIs and SLOs and use them to manage the service.” Indeed, we agree that SLIs and SLOs matter more for your SOC than any SLAs or other agreements.
Metrics matter, but so does flexibility
When considering the list of most difficult questions a security operations team can face, it’s vital to understand how to evaluate metrics to reach accurate answers. Consider another insight from the book: “Most metrics are better thought of as distributions rather than averages.”
If the average alert response is 20 minutes, does that mean that “all alerts are addressed in 18 to 22 minutes,” or that “all alerts are addressed in five minutes, while one alert is addressed in six hours?” Those different answers point to very different operational environments.
What we’ve seen before in SOCs is that a single outlier event is probably the one that matters most. As the authors put it, “The higher the variance in response times, the more the typical user experience is affected by long-tail behavior.” So, in security land, that one alert that took six hours to respond to was likely related to the most dangerous activity detected.
To address this, the book advises, “Using percentiles for indicators allows you to consider the shape of the distribution.” Google detection teams track the 5% and 95% values, not just averages.
Another useful concept from SRE is the “error budget,” a rate at which the SLOs can be missed, and tracked on a daily or weekly basis. It’s a SLO for meeting other SLOs.
The SOC value here may not be immediately obvious, but it’s vital to understanding the unique role security occupies in technology. In security, metrics can be a distraction because the real game is about preventing the threat actor from achieving their objectives. Based on our own experiences, most blue teams would rather miss the SLO and catch the threat in their environment. The defenders win when the attacker loses, not when the defenders “comply with a SLA.” The concept of the error budget might be your best friend here.
The SRE book takes that line of thinking even further. “It’s both unrealistic and undesirable to insist that SLOs will be met 100% of the time: doing so can reduce the rate of innovation and deployment.”
More broadly, and as we said in our recent paper with Deloitte on SOCs, rigid obeisance is its own vulnerability to exploit. “This adherence to process and lack of ability for the SOC to think critically and creativity provides potential attackers with another opportunity to successfully exploit a vulnerability within the environment, no matter how well planned the supporting processes are.”
To be successful at defending their organizations, SOCs must be less like the unbending oak and more like the pliant but resilient willow.
Track metrics but stay focused on threats
A third interesting puzzle from our SRE brethren: “Don’t pick a target based on current performance.”
We all want to get better at what we do, so choosing a target goal for improvement based on our existing performance can’t be bad, right? It turns out, however, that choosing a goal that sets up unrealistic or otherwise unhelpful, or woefully insufficient, expectations can do more harm than good.
Here is an example: An analyst handles 30 alerts a day (per their SLI), and their manager wants to improve by 15% so they set the SLO to 35 alerts a day. But how many alerts are there? Leaving aside the question of whether it is the right SLI for your SOC, what if you have 5,000 alerts, and you drop 4,970 of them on the floor. When you “improve,” you still drop 4,965 on the floor. Is this a good SLO? No, you need to hire, automate, filter, tune, or change other things in your SOC, not set better SLO targets that seemingly improve upon today’s numbers.
To this, our SRE peers say: “As a result, we’ve sometimes found that working from desired objectives backward to specific indicators works better than choosing indicators and then coming up with targets… Start by thinking about (or finding out!) what your users care about, not what you can measure.”
In the SOC, this probably means start with threat models and use cases, not the current alert pipeline performance.
SOC guidance can sometimes be more cryptic than we’ve let on. One challenging question is determining how many metrics we really need in a typical SOC. SREs wax philosophical here: “Choose just enough SLOs to provide good coverage of your system’s attributes.”
In our experience, we haven’t seen teams succeed with more than 10 metrics, and we haven’t seen people describe and optimize SOC performance with fewer than 3. However, SREs offer a helpful, succinct test: “If you can’t ever win a conversation about priorities by quoting a particular SLO, it’s probably not worth having that SLO.”
SLOs will get to define your SOC, so define them the way you want your SOC to be, the book advises. “It’s better to start with a loose target that you tighten than to choose an overly strict target that has to be relaxed when you discover it’s unattainable. SLOs can—and should—be a major driver in prioritizing work for SREs and product developers, because they reflect what users care about.”
Importantly, make SLOs for your SOC transparent within the company. As the SREs say, “Publishing SLOs sets expectations for system behavior.” The benefit is that nobody can blame you for non-performance if you perform to those agreed upon SLOs.
Finally, here are some examples of metrics from our teams at Google. In addition to reviewing all escalated alerts, they collect and review weekly:
event volume
event source counts
pipeline latency
triage time median
triage time at 95%
Analyzing these metrics can reveal useful guidance for applying SRE principles and ideas with their detection and response teams.
Event volume: What we need to know here is what is driving the volume. Is the event volume normal, high, or low—and why? Was there a flood of messages? New data source causing high volume? What caused it? Any bad signals? Or is there a problematic area of the business that needs strategic follow-up to implement additional controls?
Event source count: Are there signals or automation that's behaving abnormally? Is there new automation that's misbehaving? Counting events for each source call makes for a decent SLI.
Pipeline latency: Here at Google, we aim for a confirmed detection within an hour of an event being generated. The aspirational time is 5 minutes. This means that the event pipeline latency is something that must be tracked very diligently. This also means that we must scrutinize automation latency. To achieve this, we try to remove self-caused latency so that we're not hiding the pain of bad signals or bad automation.
We triage median and 95p time: We track the response time to events. As the SRE book points out, tracking only a single average number can get you in trouble very quickly. Note that triage time is not the same as time to resolution, but more of a dwell time for an attacker before they are discovered.
Incident resolution times: When you have a SLI but not a SLO, this can be the proverbial elephant in the room and create all sorts of bad incentives to “go fast” instead of “go good.” Specifically, SLO without SLI causes harm from encouraging the analysis to resolve quickly and potentially increase the risk of missing serious security incidents, especially when subtle signals are involved.
When reviewing alert escalations, we look to determine if the analysis is deep enough, if handoffs contain the right information for our response teams, and to get a sense of analyst fatigue. If analysts are phoning in their notes, it's a sign that they're over a particular signal or that there are a ton of duplicate incidents and we need to drive the business in some way.
By measuring these and other factors, metrics allow us to drive down the cost of each detection. Ultimately, this can help our detection and response operation scale faster than the threats.
Related posts:


