Achieving Autonomic Security Operations: Automation as a Force Multiplier

Anton Chuvakin
Security Advisor, Office of the CISO
Iman Ghanizada
Global Head of Security Operations Solutions, Google Cloud
As we discussed in “Achieving Autonomic Security Operations: Reducing toil”, your Security Operations Center (SOC) can learn lessons from Site Reliability Engineering (SRE) This means that applying software engineering practices to security operations challenges can radically improve an organization’s security. In this post, we discuss how you can leverage another core principle of SRE – automation - as a means to achieve better outcomes in your SOC.
Let’s make it very clear – a fully automated Security Operations Center that requires no human involvement is not possible today. The essence of Autonomic Security Operations is the belief that organizations need their threat management functions to scale, involuntarily, on-demand and that such growth needs to be faster than the growth of the threats and the assets to be covered. Once your SOC is able to stay ahead of the rise in assets, threats, and complexities – you’ve effectively achieved an “Autonomic” state of existence within your organization.
This has already happened on the build side of technology – think about how the adoption of DevOps has allowed software teams to become “autonomic”, where businesses are able to enter new markets and build new products on-demand without worrying about the elasticity of their technology teams. These functions certainly are not fully automated, and so these parallels draw us to the same theory – the way we drive to this aspirational state starts with the ideology we align to. Hence, we defined Autonomic Security Operations as a combination of philosophies, practices, and tools that improve an organization's ability to withstand security attacks through an adaptive, agile, and highly automated approach to threat management.
Let’s review specific examples and principles that your SOC can learn from Site Reliability Engineering.
Naturally, building towards an autonomic approach to threat management means that implementing automation where possible is a principle that every practitioner in the SOC should aspire to. Whether you’re a security engineer, an analyst, an incident responder, or an architect – creative ways to automate operations (starting with the mundane tasks first) can be a force multiplier that can reduce the burden of operations on your team.
This is parallel to how things stand in the domain of SRE. However, the SRE book also adds that “multiplying force does not naturally change the accuracy of where that force is applied.” This reminds us that automating a broken process often makes it more broken, but also that automating something that isn't game-changing or systemic for a SOC would only make you slightly better, if that.
In practice, automation is applied across many different areas and various roles in the SOC. Examples span the range of building playbooks for response activities (with tools like Siemplify or other SOAR products), data enrichment, linking your processes to managed security services, and endless other workflows in your SOC. Anytime you do something repetitively, ask yourself whether this can be creatively automated.
It is often suggested that the value of automation is solely about saving time. In fact, our SRE peers remind us that “automation provides more than just time saving, so it’s worth implementing in more cases than a simple time-expended versus time-saved calculation might suggest.” Both SOC practitioners and SREs agree that consistency is also a core element of automation, as is scaling (“scale is an obvious motivation for automation”).
Specifically, consistency also allows you to solve for defects in the process. While defects often align to reliability, let’s consider that reliability in security is both system reliability as well as signal reliability. Your tools and practices should minimize downtime, minimize noise, and maximize true positives – thereby increasing system and signal reliability so your team can focus on the continual resolution and improvement of defenses.
Also, consider that some work in the SOC is manual-by-design, such as threat hunting, which is an analyst-centric process, even if aided by tools. Ideally, once a threat is identified and neutralized during a hunt, the data behind the adversaries tactics and techniques should be leveraged to improve detection use cases, feeding the automation wherever possible.
Speed still comes up a lot in SRE discussions of automation; after all “humans don’t usually react as fast as machines.” In the past, sub-second speed mattered little in security, especially in the day and age of 200+ day response timelines. Today, ransomware has changed things and speed does matter.
Note that speed also doesn’t necessarily have to be only correlated to detection speed and reducing the Mean Time to Detect. Let’s say you detect something that may be affecting a production workload, and you have automation that sends a request with actions to the project owner. If the affected team does not respond and you need to “break glass”, the speed of your response can determine what the outcome will be. So look at how you can automate away the performance bottlenecks.
As a result, the key lesson for SOC automation from SRE is that “the factors of consistency, quickness, and reliability dominate most conversations about the trade-offs of performing automation.” These lessons resonate when working to make your SOC scale faster than the threats you face and also faster than your IT assets grow.
Further, we picked up a particular new insight from the SRE book, namely that automation separates the operation from an operator (“Decoupling operator from operation is very powerful.”). Specifically, “once you have encapsulated some task in automation, anyone can execute the task.” What does this solve? Some of the talent shortage problems in your SOC! This again gives us a chance to scale faster than the growth of threats and assets.
Here is another very useful reminder for your SOC from the world of SRE: “automatic systems also provide a platform.” What does it mean? That script you wrote is not a platform, even if it automates some minor task. The way we think about it, the platform is a programmable entity, a base to develop other important things (a good SOAR is a platform, for example). This means you have a chance to make automation of your activities more systematic.
However, there is a slightly paradoxical consequence here: “A platform also centralizes mistakes. In other words, a bug fixed in the code will be fixed there once and forever”. Think about it for a second. This is not about a SOC being a great place to come and make mistakes, this is about the fact that you go to one place to look for mistakes, rather than chase them over 50 tools and 200 regional offices. Centralizing mistakes is a great way to accelerate continuous improvement.
Finally, “automation as a platform” delivers helpful metrics: “a platform can export metrics about its performance, or otherwise allow you to discover details about your process you didn’t know previously.” For SOC practitioners who follow the Autonomic approach, the quality of your service-level objectives (SLO) are dependent on the data you have on your systems.
Our SRE colleagues have also pointed out a few negatives of automation as well as its risks. The very obvious topic that every SOC team highlights is that automated responses can sometimes result in disastrous outcomes, if not planned correctly. This can happen in both IT operations and Security. The SRE book describes examples where many production systems at a major technology company were deleted by automation, reimaged straight to demagnetized dust with enviable scale and effectiveness. This is a possibility with automation, so it is important to have peer reviews, QA & testing, highly descriptive playbooks, and other processes in place when developing automated responses.
Also in SRE, “Automation needs to be careful about relying on implicit "safety" signals.” In the SOC, a classic example would be blocking access based on badness, without checking for business criticality. We imply that it is safe to block access, but do we have an explicit “this machine is OK to auto-block” list? Is this safe to shut down? Is this safe to block access to? Using explicit safety signals for automation is a useful insight to implement in a SOC.
We have learned about other challenges that are relevant to the world of security operations. For example, some SOAR users complain that when the security tools change their SOAR systems don't always follow quickly enough. This is a well-known problem in the world of SRE: automation “being maintained separately from the core system therefore suffers from “bit rot,” i.e., not changing when the underlying systems change.”
Another lesson that we are starting to see in many security operations centers is that those automations that are infrequent, such as playbooks run upon seeing rare attack indicators are difficult to test. “Automation that is crucial but only executed at infrequent intervals and therefore difficult to test is often particularly fragile because of the extended feedback cycle.” It is easy to refine an efficient playbook that runs 10 times a day, but it's much harder to test and improve a playbook that is aimed at a particular type of an advanced attack that may happen this year … or not. How do we fix that? By more automation – test automation and simulations in this case.
Across most leading security operations centers, and deep in the SRE book is another key lesson and that is that “The most functional tools are usually written by those who use them.” This has been discussed in many detection engineering articles, but it is definitely not common in many mainstream SOCs. This is why in our ASO workshops we explain that “SOC analysts” and “detection engineers” need to converge and become one.
Earlier we discussed the belief of an Autonomic Security Operations practice, but we also have learnings from SRE that chart a path of arriving to the autonomic system itself (that does not need extraneous automation) by starting from a manual approach and then evolving to automation. Here automation evolution example from the SRE book:
“Operator-triggered manual action (no automation)
Operator-written, system-specific automation
Externally maintained generic automation
Internally maintained, system-specific automation
Autonomous systems that need no human intervention”
While some of the above is not obviously related to SOC, there are obvious parallels:
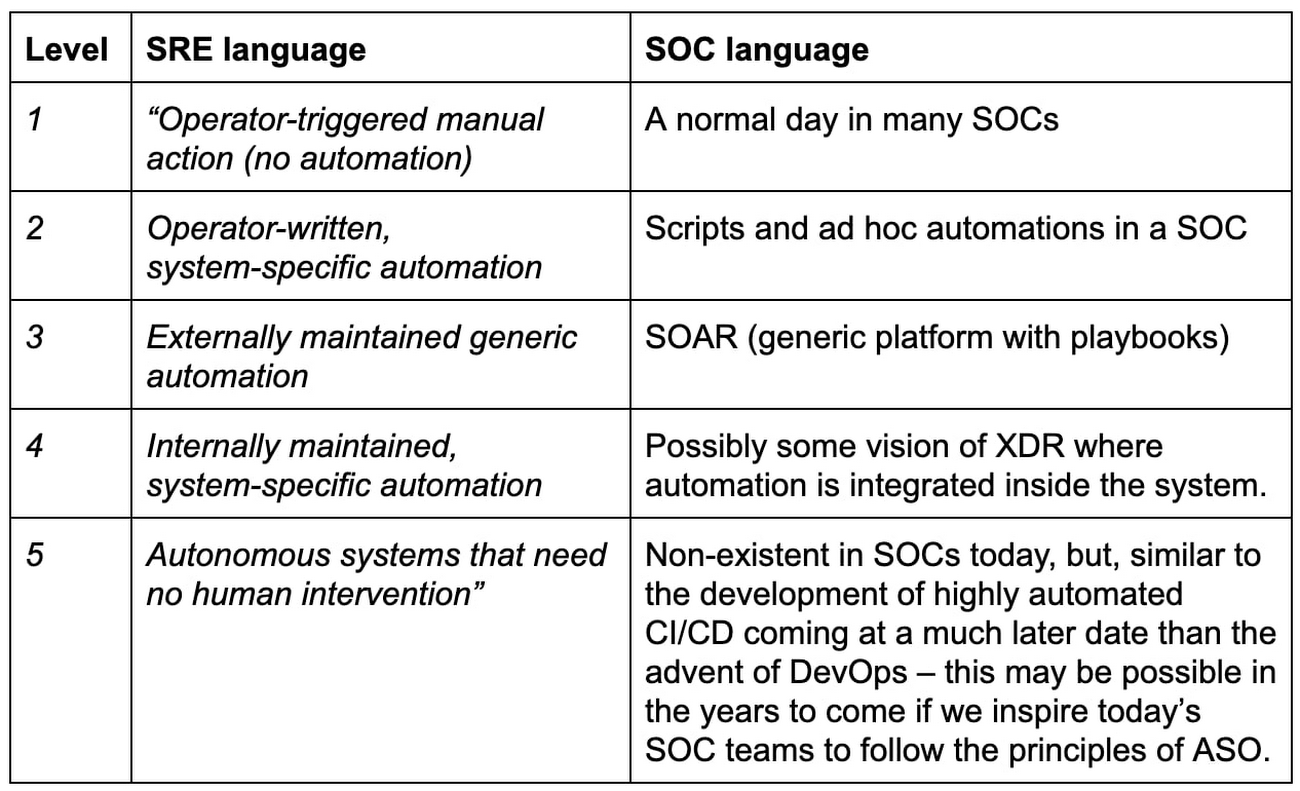
While it is clear that automation is no magic bullet and certainly is not a single tool to buy, the sum of the whole is what makes a system secure, efficient, reliable, and allows businesses to sleep at night.
Consider inspiring your team to do brain-storming exercises and workshops on key areas they can automate within their roles. This shift of incentivizing your staff to think creatively is how DevOps and SRE are so widely successful, and if we want to get ahead of the complexity of modern technology footprints, automation is a core principle of success.
Related posts:


