How Sensitive Data Protection can help secure generative AI workloads
Scott Ellis
Senior Product Manager
Assaf Namer
Cloud Security Architect
Get original CISO insights in your inbox
The latest on security from Google Cloud's Office of the CISO, twice a month.
SubscribeGenerative AI models are a hot topic across nearly every industry. Enterprises are looking to leverage this technology to enrich their business services and engagement with customers, as well as streamline operations and speed up business processes. However, as with most AI/ML applications, generative AI models are fueled by data and data context. Understanding and protecting this sensitive, enterprise-specific data is critical to ensuring successful deployments and proper use.
In recent surveys conducted by Google among attendees across our Modern Security events at the Google campus in Sunnyvale, respondents said that “data leakage” and “privacy” were two of the top three concerns when asked, “What are you seeing as the top three risks/dangers/security issues with AI today for your company?” Additionally, data leakage is one of the risks associated with prompt injection, which OWASP has identified as one of the top 10 risks for foundation applications. Protecting training data and foundation response data is an important step in building robust gen AI applications.
Below, we explore a data-focused approach to protecting gen AI applications with Google Sensitive Data Protection, and provide a Jupyter Notebook with real-life examples.
Why is data important?
Like other AI/ML workloads, generative AI requires data in order to tune or extend it for specific business needs. Generative AI on Vertex AI already provides robust data commitments to ensure data and models are not used to train our foundation models or leaked to other customers. However, one concern that organizations have is how to reduce the risk of customizing and training models with their own data that may include sensitive elements such as personal information (PI) or personally identifiable information (PII). Often, this personal data is surrounded by context that the model needs so it can function properly.
Finding personal data and removing just the sensitive elements can be a challenge. Additionally, redaction strategies can impact statistical properties of the dataset or make statistically inaccurate generalizations. Our Sensitive Data Protection service, which includes our Cloud Data Loss Prevention (DLP) API, provides a suite of detection and transformation options to help you address these challenges.
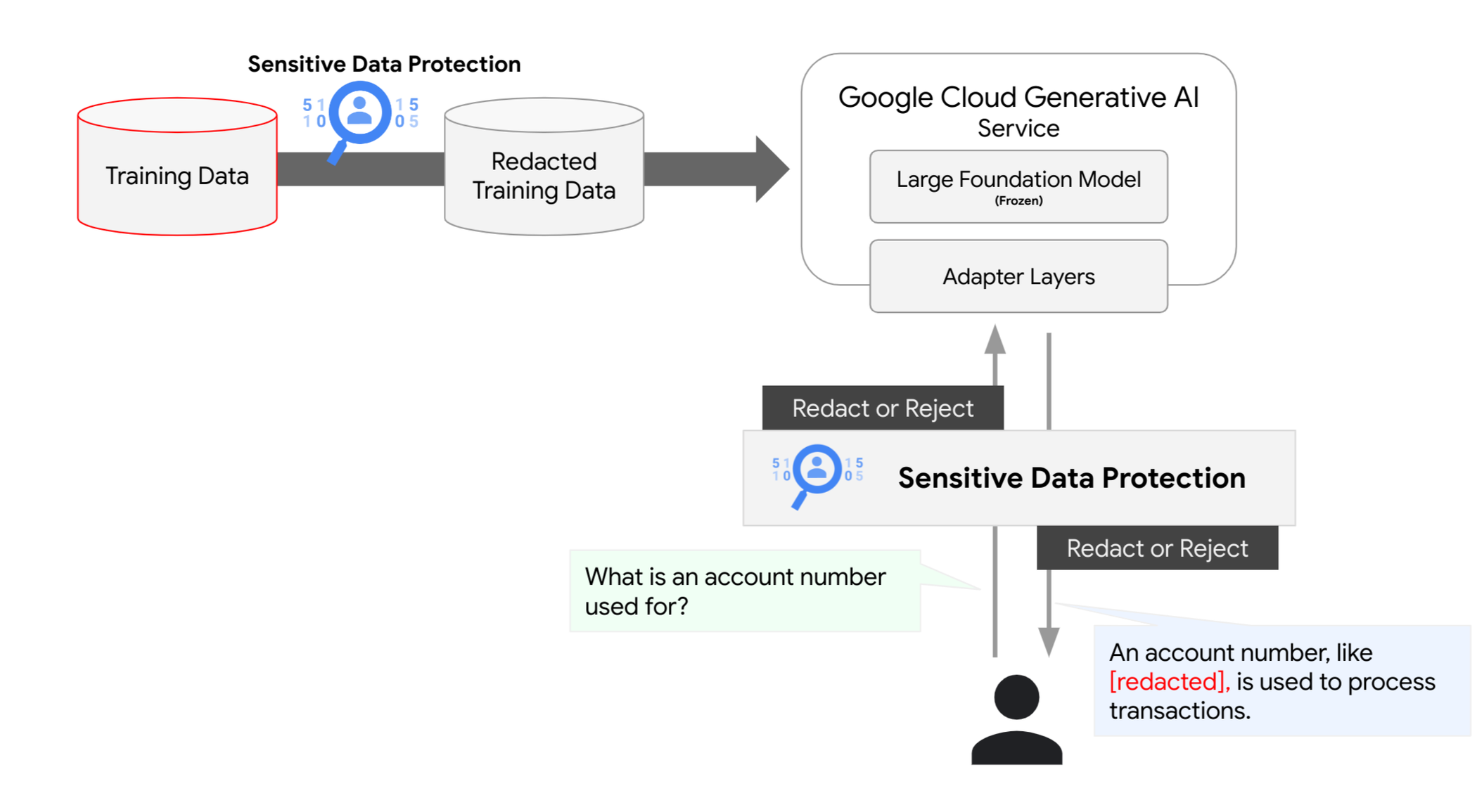
Organizations can use Google Cloud’s Sensitive Data Protection to add additional layers of data protection throughout the lifecycle of a generative AI model, from training to tuning to inference. Early adoption of these protection techniques can help ensure that your model workloads are safer, more compliant, and can reduce risk of wasted cost on having to retrain or re-tune later.
Taking a data-focused approach
Sensitive Data Protection includes more than 150 built-in infoTypes to help quickly identify sensitive data elements like names, personal identifiers, financial data, medical context, or demographic data. You can identify these elements to choose which records to remove from pipelines or leverage inline transformation to obscure only the sensitive elements while retaining the surrounding context. This enables you to reduce risk while preserving the utility of your data. Inline transformation can be used when preparing training or tuning data for AI models and can protect AI generated responses in real-time.
In the example below, we remove sensitive elements and replace them with the type of data. This way, you can train models knowing the data-type and surrounding context without revealing the raw content.
Raw Input:
[Agent] Hi, my name is Jason, can I have your name?
[Customer] My name is Valeria
[Agent] In case we need to contact you, what is your email address?
[Customer] My email is v.racer@example.org
[Agent] Thank you. How can I help you?
[Customer] I’m having a problem with my bill.
De-identified Output:
[Agent] Hi, my name is [PERSON_NAME], can I have your name?
[Customer] My name is [PERSON_NAME]
[Agent] In case we need to contact you, what is your email address?
[Customer] My email is [EMAIL_ADDRESS]
[Agent] Thank you. How can I help you?
[Customer] I’m having a problem with my bill.
Sometimes a simple replacement like the example above is not enough. Sensitive Data Protection has several de-identification options that can be tailored to meet your specific needs. First, as the customer, you have full control over which infoTypes are important to detect and redact and which you want to leave intact. Additionally, you can choose what kind of data transformation methods best suit your needs from simple redaction to random replacement to format preserving encryption.
Consider the following example which uses random replacement. It produces an output that looks much like the input sample, but has randomized values in place of the identified sensitive elements:
Input:
[Agent] Hi, my name is Jason, can I have your name?
[Customer] My name is Valeria
[Agent] In case we need to contact you, what is your email address?
[Customer] My email is v.racer@example.org
[Agent] Thank you. How can I help you?
[Customer] I’m having a problem with my bill.
De-identified Output:
[Agent] Hi, my name is Gavaia, can I have your name?
[Customer] My name is Bijal
[Agent] In case we need to contact you, what is your email address?
[Customer] My email is happy.elephant44@example.org
[Agent] Thank you. How can I help you?
[Customer] I’m having a problem with my bill.
Protection for data preparation
Customers' frequently use their own data to create datasets to train custom AI models, such as when deploying an AI model on prediction endpoints. Additionally, to fine-tune a model like language and code using data particular to the customer in order to increase the relevance and the business goals of LLM response.
Some customers use generative AI features to tune a foundation model and deploy foundation models for specific tasks and business needs. This tuning process uses customer-specific datasets and creates parameters that are then used at inference time; the parameters reside in front of the “frozen” foundation model, inside the user’s project. To ensure that these datasets do not include sensitive data, use the Sensitive Data Protection Service to scan the data that was used to create the datasets. Similarly, this method can be used for Vertex AI Search to ensure uploaded data does not include sensitive information.
Protection in-line prompt and response
Protecting training pipelines is important, but it is only part of the defense offered in Sensitive Data Protection. Since generative AI models take unstructured prompts from users and generate new, possibly unseen responses, you may also want to protect sensitive data in-line. Many known prompt-injection attacks have been seen in the wild. The main goal of these attacks is to manipulate the model into sharing unintended information.
While there are multiple ways to protect against prompt injection, Sensitive Data Protection can provide a data-centric security control on data going to and from generative AI foundation models by scanning the input prompt and generated response to ensure that sensitive elements are identified or removed.
Next Steps
Learn more about Sensitive Data Protection and view the Colab Notebook to see how you can take steps forward to protect your data and workloads for AI/ML and generative AI. With Vertex AI, you can interact with, customize, and embed foundation models into your applications, no machine learning expertise required. Access foundation models on Model Garden, tune models using a simple interface on Generative AI Studio, or use models directly in a data science notebook.

