Why Apache Beam? A Google Perspective
Tyler Akidau
Staff Software Engineer, Apache Beam committers
When we made the decision (in partnership with data Artisans, Cloudera, Talend, and a few other companies) to move the Google Cloud Dataflow SDK and runners into the Apache Beam incubator project, we did so with the following goal in mind: provide the world with an easy-to-use, but powerful model for data-parallel processing, both streaming and batch, portable across a variety of runtime platforms. Now that the dust on the initial code drops is starting to settle, we wanted to talk briefly about why this makes sense for us at Google and how we got here, given that Google hasn’t historically been directly involved in the OSS world of data-processing.
Why does this make sense for Google?
Google is a business, and as such, it should come as no surprise there’s a business motivation for us behind the Apache Beam move. That motivation hinges primarily on the desire to get as many Apache Beam pipelines as possible running on Cloud Dataflow. Given that, it may not seem intuitive to adopt a strategy of opening the platform up to other runners. However, it’s quite the contrary. Opening up the platform yields many benefits:- The more runners Apache Beam supports, the more attractive it becomes as a platform
- The more users adopt Apache Beam, the more users there are that might possibly want to run Apache Beam on Google Cloud Platform
- The more folks we get involved in developing Apache Beam, the more we can push forward the state of the art in data processing
How did this even happen?
Google has historically adopted a lob-a-paper-over-the-wall sort of approach to sharing our innovations with the OSS community. It wasn’t until we co-founded Apache Beam that we moved to sharing innovations through working open-source code for data processing. This begs the question: why now?There are a few reasons for this:
- Whereas we used to work primarily within Google, our interactions with Cloud customers have made clear the value of OSS — the success of the Hadoop community being a great example. This shift has made moves like Apache Beam possible.
- For Beam specifically, the move really only made sense if there was an existing OSS runner that supported enough of the sophisticated Beam Model (formerly the Dataflow model) to make for a compelling option in on-premise and non-Google cloud scenarios. That requirement was fulfilled late last year as Apache Flink rapidly adopted the Beam Model within their system.
To help frame sets of related functionality, we’ve broken the matrix up into four tables, with capabilities grouped by the What / Where / When / How questions they relate to (see Streaming 102 if you’re unfamiliar with these questions and why they’re important).
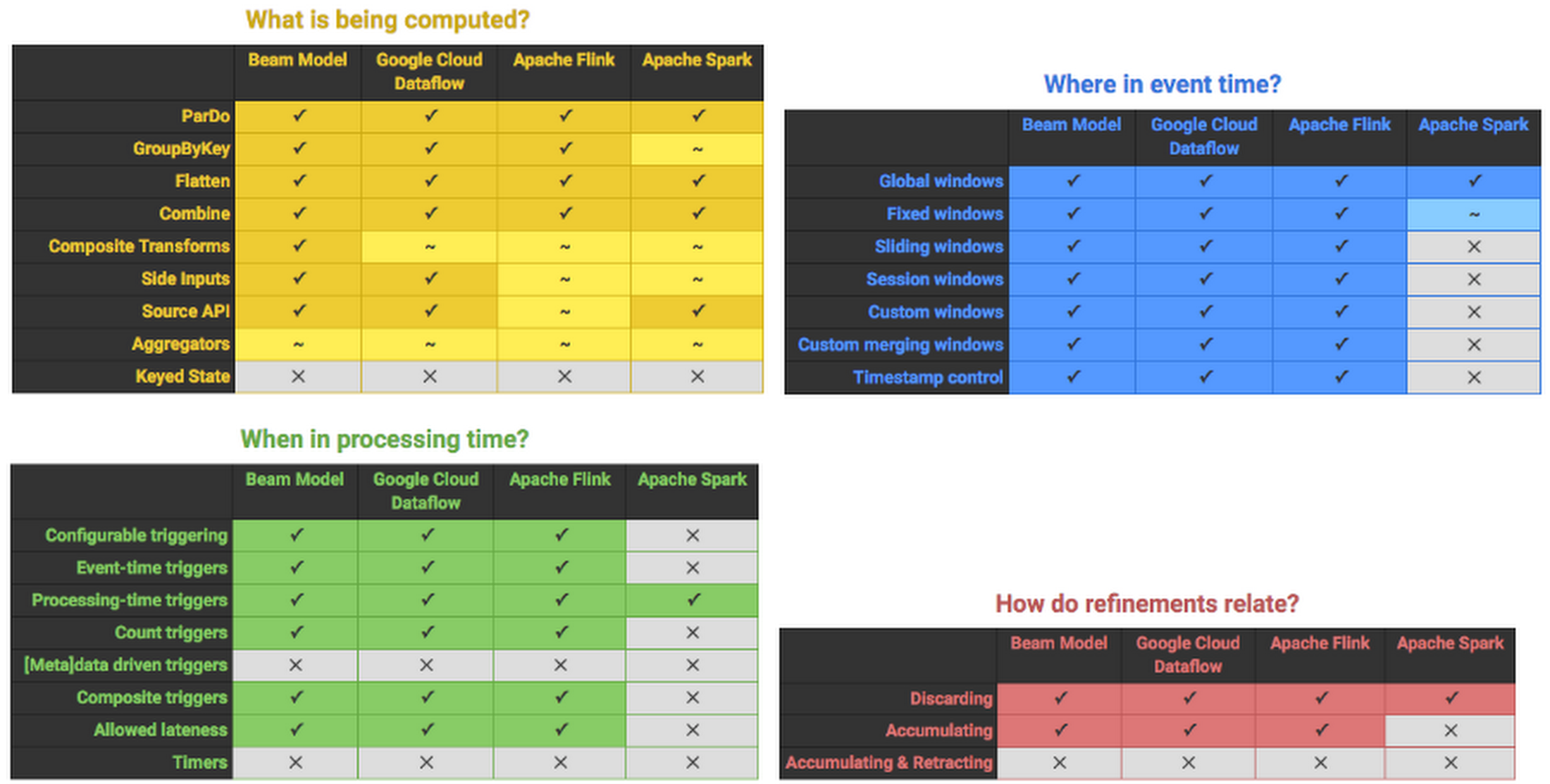
Apache Beam Capability Matrix, summarizing the capabilities of the current set of Apache Beam runners across a number of dimensions as of April 2016.
For Apache Beam to achieve its goal of pipeline portability, we needed to have at least one runner that was sophisticated enough to be a compelling alternative to Cloud Dataflow when running on premise or on non-Google clouds. As you can see from these tables, Flink is the runner that currently fulfills those requirements. With Flink, Beam becomes a truly compelling platform for the industry.
Flink got to where it is today because they were sold on the power and simplicity of the Beam model. As Kostas Tzoumas, CEO of data Artisans, the company behind Flink, puts it:
Our involvement with Beam started very early [...] Very quickly, it became apparent to us that the Dataflow model [...] is the correct model for stream and batch data processing. We fully subscribed to Google’s vision to unify real-time and historical analytics under one platform [...]. Taking a cue from this foundational work, we rewrote Flink’s DataStream API [...] to incorporate many of the concepts described in the Dataflow paper [...].
As the Dataflow SDK and the Runners were moving to Apache Incubator as Apache Beam, we were asked by Google to bring the Flink runner into the codebase of Beam [...]. We decided to go full st(r)eam ahead with this opportunity as we believe that [...] the Beam model is the future reference programming model for writing data applications in both stream and batch [...].
One question that remains is what is the relationship between Flink’s own native API (DataStream), and the Beam API? [...] The differences between the two APIs are largely syntactical (and a matter of taste), and, we are working together with Google towards unifying the APIs, with the end goal of making the Beam and Flink APIs source compatible.
What does the future hold?
Flink may be at the forefront currently, but that isn’t to say that other runners won’t catch up. Given the breadth of interesting options available across the industry, we of course intend to support as many runners as possible within Beam (this is how the free market of execution engines starts to come into play), and we want all of them to support as much of the model as possible (this is how the promise of portability is realized). Storm 1.0 recently added basic event-time support. Spark 2.0 will incorporate a subset of the Beam model into their Structured Streaming semantics (they lack watermarks and unaligned windows, and appear to hard code triggers to match their micro-batch heartbeats). Both should be good options for a limited set of use cases, and Beam runner implementers will then have the option of providing a more comprehensive suite of semantics by augmenting the missing functionality within their runner implementation. Others somewhat newer to the scene, such as Gearpump, also look quite promising as Beam runners.Even better, within this open market for data processing execution engines, there’s still room for innovation and differentiation, in interesting (and largely unsolved) areas, such as performance, latency, scalability, ease-of-operational-maintenance, automatic tuning, etc. This leads to the battle on the runner side becoming one of user satisfaction, not one of achieving market dominance through API lock-in, which is a good thing for the industry as a whole.
Conclusion
We firmly believe Apache Beam is the future of streaming and batch data processing. We hope it will lead to a healthy ecosystem of sophisticated runners that compete by making users happy, not by maximizing market share via API lock in. The most capable runners at this point in time are clearly Google Cloud Dataflow (for running on GCP) and Apache Flink (for on-premise and non-Google cloud), as detailed by the capability matrix recently published. But others are catching up, and the industry as whole is shifting towards supporting the semantics in the Beam Model. This will only lead to more good things for Apache Beam users down the road.The future of streaming and batch is Apache Beam. The choice of runner is up to you.


