Toward better node management with Kubernetes and Google Container Engine
Maisem Ali
Software Engineer
Using our Google Container Engine managed service is a great way to run a Kubernetes cluster with a minimum of management overhead. Now, we’re making it even easier to manage Kubernetes clusters running in Container Engine, with significant improvements to upgrading and maintaining your nodes.
Automated Node Management
In the past, while we made it easy to spin up a cluster, keeping nodes up-to-date and healthy were still the user’s responsibility. To ensure your cluster was in a healthy, current state, you needed to track Kubernetes releases, set up your own tooling and alerting to watch nodes that drifted into an unhealthy node, and then develop a process for repairing that node. While we take care of keeping the master healthy, with the nodes that make up a cluster (particularly large ones), this could be a significant amount of work. Our goal is to provide an end-to-end automated management experience that minimizes how much you need to worry about common management tasks. To that end, we're proud to introduce two new features that help ease these management burdens.Node Auto-Upgrades
Rather than having to manually execute node upgrades, you can choose to have the nodes automatically upgrade when the latest release has been tested and confirmed to be stable by Google engineers.You can enable it in the UI during new Cluster and Node Pool creation by enabling the “Auto upgrades”.
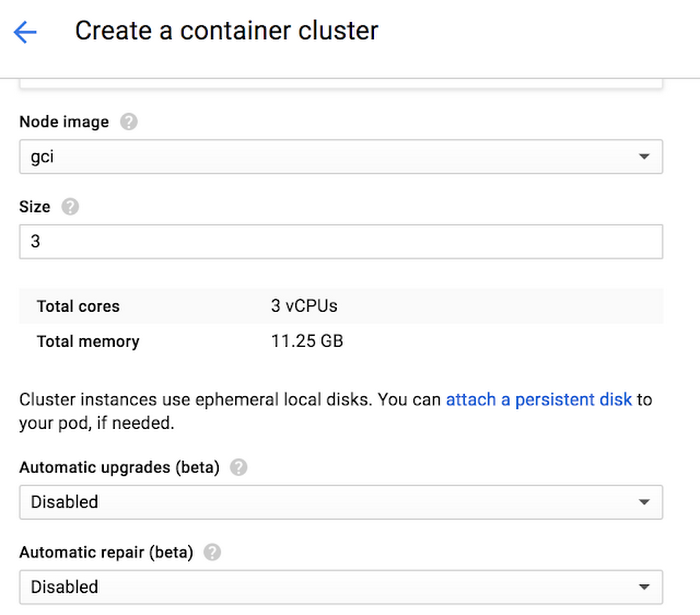
To enable it in the CLI add the “--enable-autoupgrade” flag.
Once enabled, each node in the selected node pool will have its workloads gradually drained, shut down and a new node will be created and joined to the cluster. The node will be confirmed to be healthy before moving onto the next node.
To learn more see Node Auto-Upgrades on Container Engine.
Node Auto-Repairs
Like any production system, cluster resources must be monitored to detect issues (crashing Kubernetes binaries, workloads triggering kernel bugs and out-of-disk issues, etc.) and repair them if they're out of specification. A node that goes unhealthy will decrease the scheduling capacity of your cluster and as the capacity reduces your workloads will stop getting scheduled.Google already monitors and repairs your Kubernetes master in case of these issues. With our new Node-Auto Repair feature, we'll also monitor to each node in the node pool.
You can enable Auto Repairs during new Cluster and Node Pool Creation.
To enable it in the UI:
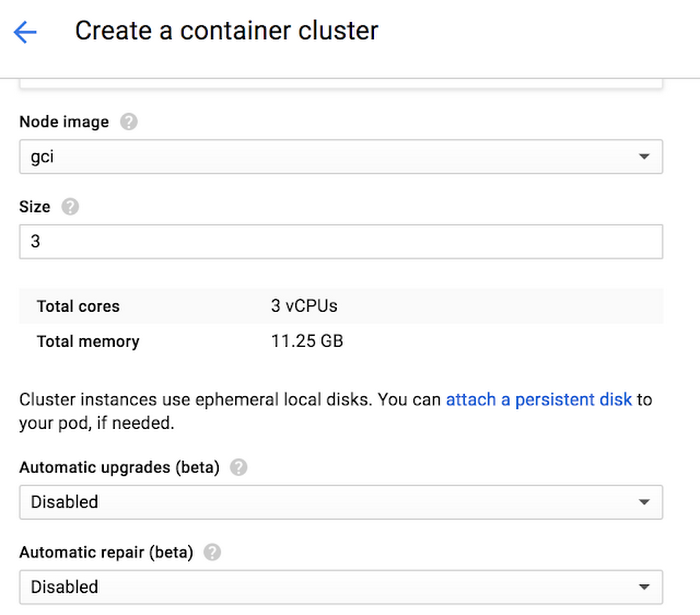
To enable it in the CLI:
Once enabled, Container Engine will monitor several signals, including the node health status as seen by the cluster master and the VM state from the managed instance group backing the node. Too many consecutive health check failures (around 10 minutes) will trigger a re-creation of the node VM.
To learn more see Node Auto-Repair on Container Engine.
Improving Node Upgrades
In order to achieve both these features, we had to do some significant work under the hood. Previously, Container Engine node upgrades did not consider a node’s health status and did not ensure that it was ready to be upgraded. Ideally a node should be drained prior to taking it offline, and health-checked once the VM has successfully booted up. Without observing these signals, Container Engine could begin upgrading the next node in the cluster before the previous node was ready, potentially impacting workloads in smaller clusters.
In the process of building Auto Node Upgrades and Auto Node Repair, we’ve made several architectural improvements. We redesigned our entire upgrade logic with an emphasis on making upgrades as non-disruptive as possible. We also added proper support for cordoning and draining of nodes prior to taking them offline, controlled via podTerminationGracePeriod. If these pods are backed by a controller (e.g. ReplicaSet or Deployment) they're automatically rescheduled onto other nodes (capacity permitting). Finally, we added additional steps after each node upgrade to verify that the node is healthy and can be scheduled, and we retry upgrades if a node is unhealthy. These improvements have significantly reduced the disruptive nature of upgrades.
Cancelling, Continuing and Rolling Back Upgrades
Additionally, we wanted to make upgrades more than a binary operation. Frequently, particularly with large clusters, upgrades need to be halted, paused or cancelled altogether (and rolled back). We're pleased to announce that Container Engine now supports cancelling, rolling back and continuing upgrades.If you cancel an upgrade, it impacts the process in the following way:
- Nodes that have not been upgraded remain at their current version
- Nodes that are in-flight proceed to completion
- Nodes that have already been upgraded remain at the new version
An identical upgrade (roll-forward) issued after a cancellation or a failure will pick up the upgrade from where it left off. For example, if the initial upgrade completes three out of five nodes, the roll-forward will only upgrade the remaining two nodes; nodes that have been upgraded are not upgraded again.
Cancelled and failed node upgrades can also be rolled back to the previous state. Just like in a roll-forward, nodes that hadn’t been upgraded are not rolled-back. For example, if the initial upgrade completed three out of five nodes, a rollback is performed on the three nodes, and the remaining two nodes are not affected. This makes the upgrade significantly cleaner.
Note: A node upgrade still requires the VM to be recreated which destroys any locally stored data. Rolling back and rolling forward does not restore that local data.
| Node Condition\Action | Cancellation | Rolling forward | Rolling back |
| In Progress | Proceed to completion | N/A | N/A |
| Upgraded | Untouched | Untouched | Rolled back |
| Not Upgraded | Untouched | Upgraded | Untouched |
Try it
These improvements extend our commitment in making Container Engine the easiest way to use Kubernetes. With Container Engine you get pure open source Kubernetes experience along with the powerful benefits of Google Cloud Platform (GCP): friendly per-minute billing, a global load balancer, IAM integration, and all fully managed by Google reliability engineers ensuring your cluster is available and up-to-date.With our new generous 12-month free trial that offers a $300 credit, it’s never been simpler to get started. Try Container Engine today.



