Preparing and curating your data for machine learning
Rostam Dinyari
AI Engineer
To design and implement a successful machine learning (ML) project, you often need to collaborate with multiple teams, including those in business, sales, research, and engineering. Understanding the essentials of gathering and preparing your data is crucial to align teams and to get the project off the ground.
This post will leave you with a list of common guidelines for assessing and preparing data for ML. If you’re involved in an ML project, and even if you have minimal technical background, then these guidelines are for you. Our goal is to bring different roles onto the same page and jump-start the process of designing and training a useful ML model.
The following content is divided into two parts. In the first part, you’ll find some common data requirements and practical considerations. Use them to evaluate whether your data is suitable for ML—and to set your expectations. If you don’t have suitable data, use this section to determine what data to collect. In the second part, you’ll find some of the common to-do items to prepare the data for ML training. So let’s dive in!
Data collection
To build an ML model that achieves your goal, you’ll need to have the kind of data that the model can learn from. If the goal is to predict a target output based on some input, you’ll need some data consisting of past input-output examples. For example, to detect (that is, to predict) a fraudulent credit card transaction (the target of the prediction), each example must contain information on a past credit card transaction and whether that transaction was fraudulent or not.
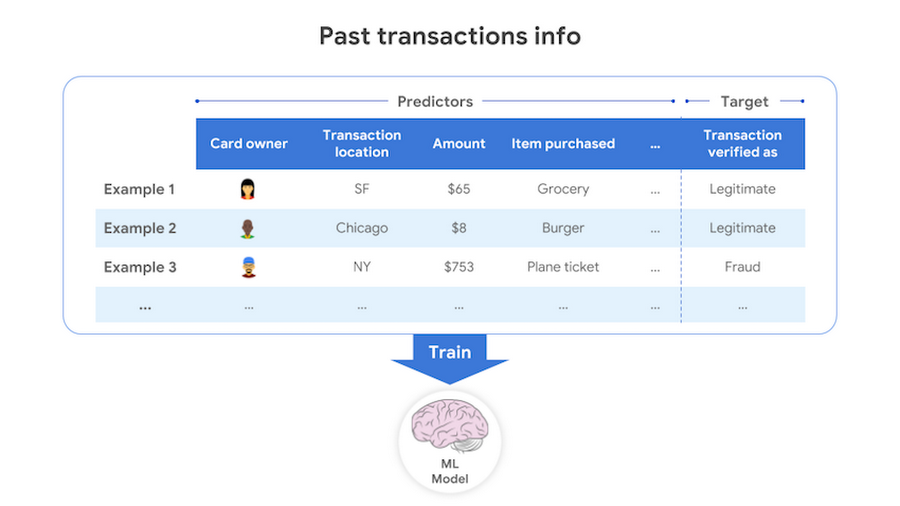
To build a useful model, you’ll need to include input data that are useful for predicting the target. For example, to detect credit card fraud, you’ll need to have information on the transaction amount, the transaction location, the card holder primary location, and so on. However, data such as the name of the cardholder is less useful for this task. Additionally the data should be accurate. You cannot expect a great model trained on incorrect or inaccurate data.
For the model to distinguish between different target outcomes, you’ll need to have some examples for each of the outcomes. For credit card fraud, your data must have some examples both of correctly identified fraud transactions and of correctly identified legitimate transactions.
For the model to be confident in its predictions, you’ll need to have a sufficient amount of examples—also called labeled data. As a rule of thumb, if you are predicting a category (for example, whether a transaction is fraudulent or legitimate), the number of examples you need for each category is 10 × the number of input attributes used for prediction—also called features1. If you are predicting a number (for example, the position of a star), you need 50 × the number of features. With more data, you can try more complex models to get better performance scores (for example, higher accuracy). If you don’t have enough labeled data, in some cases (for example, image classification or natural language processing) you can get great results by customizing pretrained models on your data—with Cloud AutoML, for example. You can also label your data by using services such as Google’s human labeling service.
To have enough signal for prediction, make sure the granularity of training and prediction data are matched. For example, if you want to predict the weather temperature hourly, but you have been recording the temperature once a day or once a week, your input is not as fine-grained as your intended output.
To build an unbiased model, collect and use data that is an unbiased representation of the population or distribution you’re modeling. For example, online reviews constitute a biased dataset to build a model to predict customer satisfaction because these reviews tend to overrepresent the most extreme views. The degree to which you can correct this bias depends on both the problem and the data. If entire segments of the population are held out from a sample, then you cannot make adjustments that result in estimates that are representative of the entire population. If entire segments of a population are missing, you should acquire more data on these segments, if possible.
To forecast future outcomes based on past data (constituting an important group of business problems), you’ll need to have been collecting data long enough. For example, if you want to predict the probability of default for five-year loans, having only three years of data introduces bias. Many common forecasting problems involve predicting a target that is periodic, for example, ice cream sales. To forecast something periodic, a good rule of thumb is to have at least three cycles of data to train a model and properly evaluate its quality prior to using it to make business decisions. You’ll likely need at least one period to capture the periodic behavior, one more period for the model to learn the general inter-period trend (that is, increasing, decreasing, or unchanging), and one more period to evaluate the model.
To build (that is, to train) a forecasting model, you must re-create snapshots of the data in the past (as examples) and show them to the model to learn from. For this reason, it is usually essential to know the timestamp at which each data value was obtained, including updates—for example, when an item price was changed or when a user changed a setting. In some problems, it may be sufficient to know the chronological order the data values were obtained if you can reconstruct the past accurately with this information alone.
For any task, it is common to have missing values in your data. Missing values can be represented in different forms even for the same data field: ‘’, None, NULL, NaN, 0, -1, 9999, and so on. The more missing values, the less useful the data. Check if you have enough useful data left if you consider only data with no missing values. It is also very important to understand the reasons why the data are missing. If the values are missing systematically (that is, missing not at random), your data is biased and can introduce bias into the model if not handled properly.
Keep documentation for each field of data and record information such as what it represents, how its value is measured, when the data is collected, whether the original values can get updated, and why it’s applicable to the use case.
Data preparation
Once you have confirmed that your data is suitable for ML, you should get the data ready for modeling. It may come as a surprise, but oftentimes you’ll spend more time on this step than in optimizing your ML algorithms. Most of the following steps do not require ML expertise, and the owners or the most frequent users of the data can participate in completing them to accelerate ML model development.
Clean the data by identifying and handling (that is, correcting, imputing, or deleting) errors, noise, and missing values and by making the data consistent—with Cloud Dataprep, for example. If the values in a data field have different units (for example, USD, Euro, Yuan, and so on), identify the unit for each value or convert them to the same unit. For categorical variables, identify all the different representations of the same value and convert them to a single representation. For example, convert “Dir of Marketing,” “Director of Marketing,” “Dir Marketing,” and other variations, as appropriate.
The meaning of the values in each data field should be consistent. For example, the data is inconsistent in a field containing item prices if some values record the wholesale price and some values instead record the retail price. Another example is data containing inconsistent sensor calibrations.
Identify and remove all sources of data leakage. Data leakage happens if you use predictive information in building your model that won’t be available at serving time—that is, prediction time. For example, in an ML competition for identifying which acoustic recordings contained calls from an endangered species of whale, the audio files with whale calls turned out to have a very specific set of file sizes. Learning that information (and some other leakage), the model did great on the competition dataset. Obviously such a model would fail in the real test.
For a forecasting problem, build a pipeline to easily re-create a snapshot of the data at an arbitrary time in the past. Doing this correctly is critical for building a useful model, and in practice it is often easier said than done. For each training example, you must use the data that was available at the time you wanted to predict the target, if you had had the ML model. For example, suppose you want to build a model to predict the probability of default for a loan application. For each training example (that is, defaulted or fully repaid application), use the applicant’s FICO score as it appears on the loan application, not a more recent FICO score. A great way to make sure that the data seen at training time and the data seen at serving time are not skewed (that is, are not inconsistent) is to save the set of features used at serving time, and then to use those features at training time. Ideally, you'd do this for every example. But if you can't, then do it for enough examples to verify consistency between training and serving.
To improve the performance of your model, complement your data with new sources of information such as external datasets. Then use your domain expertise to create informative features (called feature engineering) that can better predict the target. Build your model input data by integrating all data from diverse input sources and their transformations.
Build data pipelines to seamlessly do the data transformations, making it easy to correct mistakes or to improve the transformations and then iterate. Implement automatic tests to ensure data quality. Some common tests include checking to see that there are no missing values, no erroneous or unrealistic values, no duplicates, or no incorrect table joins. Additionally, test for training and serving consistency, especially for forecasting problems.
Depending on the ML model that you’ll be using, you may need to do additional transformations such as normalization and replacing the outliers. You can leave these tasks for the data scientists!
To dive even deeper
Assessing data requirements is an essential task in designing an ML project. Preparing data is a time-consuming effort in ML development, but one that can determine the success of the project. For a more detailed checklist, see this document. And feel free to post your own useful data prep tips on our Twitter handle with the hashtag #mldataprep. We hope you can learn from our checklist, and we’re certain we can also learn from all of you!
1 Remember to count a categorical input data field (for example, transaction city) with k categories (for example, “NY,” “SF,” and so on) as k - 1 features (because to encode k categories, you’ll need k − 1 dummy variables). That means the more categories your input field has, the more data you’ll need.


