Improving data quality for machine learning and analytics with Cloud Dataprep
Bertrand Cariou
Sr. Director Solutions & Partner Marketing, Trifacta
Editor’s note: Today’s post comes to us from Bertrand Cariou at Trifacta, and presents some steps you might take in Cloud Dataprep to clean your data for later use for your analytics or in training a machine learning model.
Data quality is a critical component of any analytics and machine learning initiative, and unless you’re working with pristine, highly-controlled data, you’ll likely face data quality issues. To illustrate the process of turning unknown, inconsistent data into trustworthy assets, we will leverage the example of a forecast analyst in the retail (consumer packaged goods) industry. Forecast analysts must be extremely accurate in planning the right quantities to order. Supplying too much product results in wasted resources, whereas supplying too little means that they risk losing profit. On top of that, an empty shelf also risks consumers choosing a competitor’s product, which can have a harmful, long-term impact on the brand.
To strike the right balance between appropriate product stocking levels and razor-thin margins, forecast analysts must continually refine their analysis and predictions, leveraging their own internal data as well as third-party data, over which they have no control.
Every business partner, including suppliers, distributors, warehouses and other retail stores, may provide data (e.g. inventory, forecast, promotions, or past transactions) in various shapes and level of quality. One company may use palettes instead of boxes as a unit of storage, pounds versus kilograms, may have different categories nomenclature and namings, may use a different date format, or will most likely have product SKUs that are a combination of internal and other supplier IDs. Furthermore, some data may be missing or may have been incorrectly entered.
Each of these data issues represents an important risk to reliable forecasting. Forecast analysts must absolutely clean, standardize, and gain trust in the data before they can report and model on it accurately. This post reviews key techniques for cleaning data with Cloud Dataprep and covers new features that may help improve your data quality with minimal effort.
Basic concepts
Cleaning data with Cloud Dataprep corresponds to a three-step iterative process:
Assessing your data quality
Resolving or remediating any issues uncovered
Validating cleaned data, at scale
Cloud Dataprep constantly profiles the data you’re working on, from the moment you open the grid interface and start preparing data. With Dataprep’s real-time Active Profiling, you can see the impact of each data cleaning step on your data.
The profile result is summarized at the column header with basic data points to point out key characteristics in your data, in the form of an interactive visual profile. By clicking one of these profile column header bars, Cloud Dataprep suggests some transformations to remediate mismatched or missing values. You can always try a transformation, preview its impact, select it or tweak it. At any point, you can always revert to a specific previous step if you don’t like the result.
With these basic concepts in mind, let’s cover Cloud Dataprep data quality capabilities.
1. Assessing your data quality
As soon as you open a dataset in the grid interface, you can access to data quality signals that help you assess data issues and guide your work in cleaning the data.

Rapid profiling
You’ll likely scan over your column headers and identify the potential quality issues to understand which columns may need your attention. Mismatched values (red bar) based on the inferred data types, missing values (black) and uneven value distribution (bars) can help you quickly identify which columns need your attention.
In this particular case, our forecast analyst knows she’ll have to drill down on the `material` field that includes some mismatched and missing values. How should these data defaults impact her forecast and replenishment models?
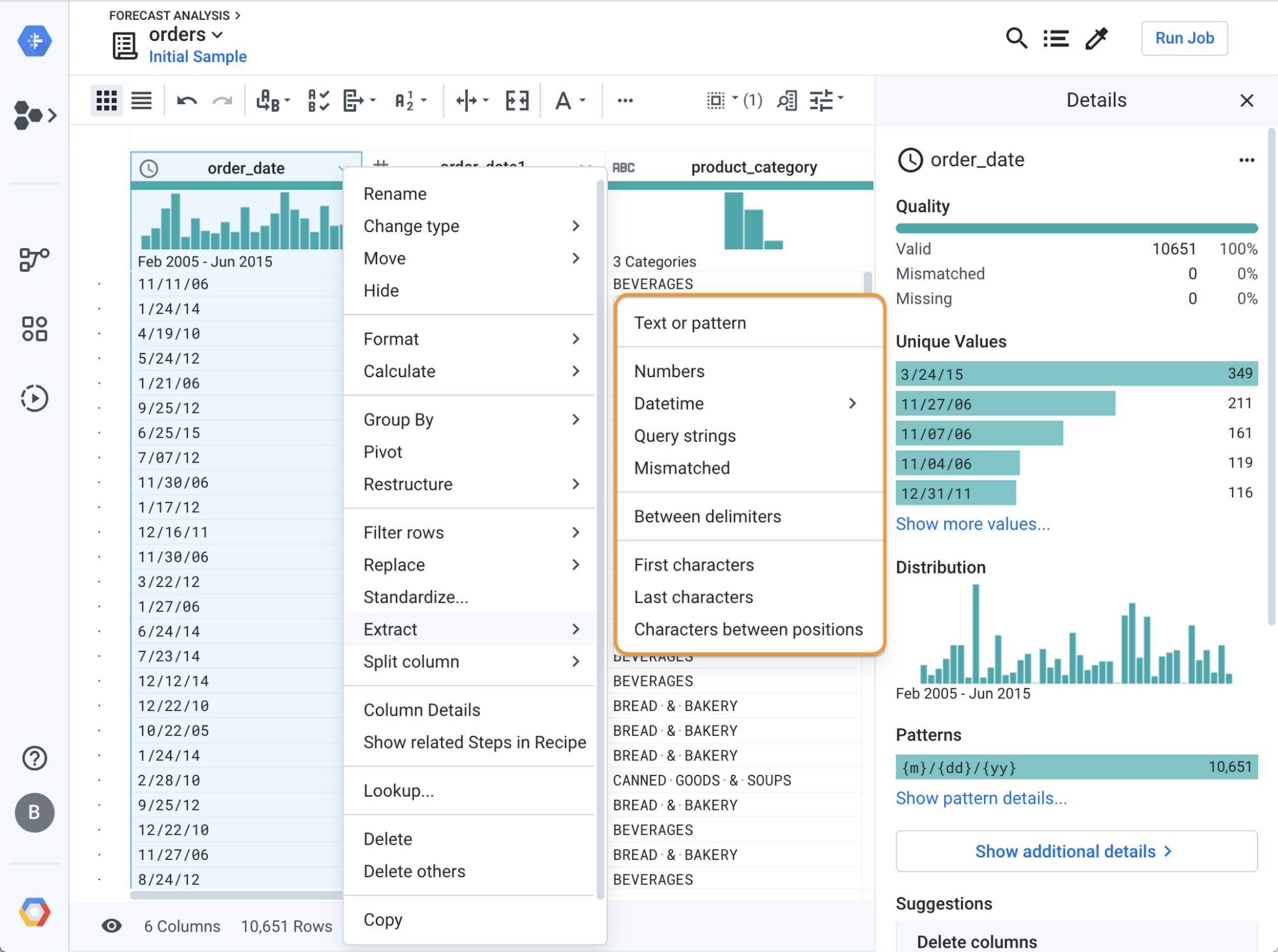
Intermediary data profiling
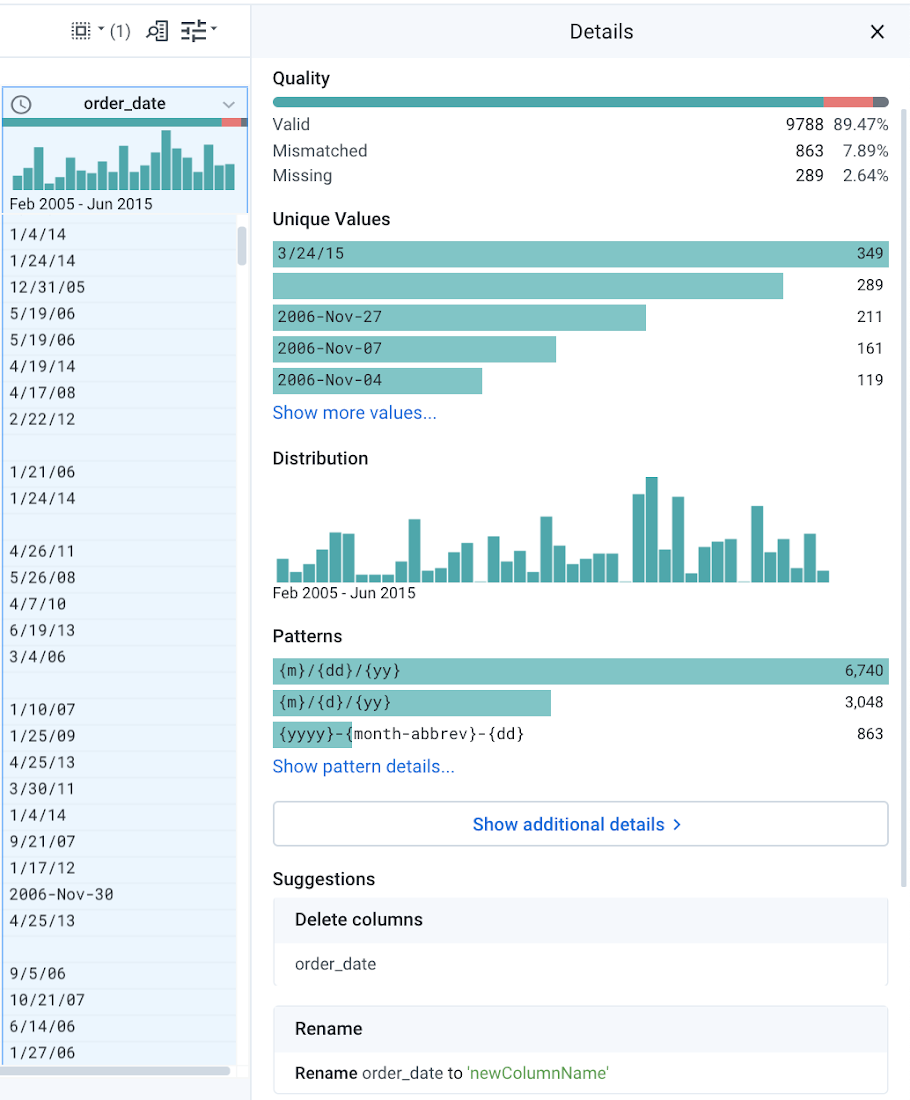
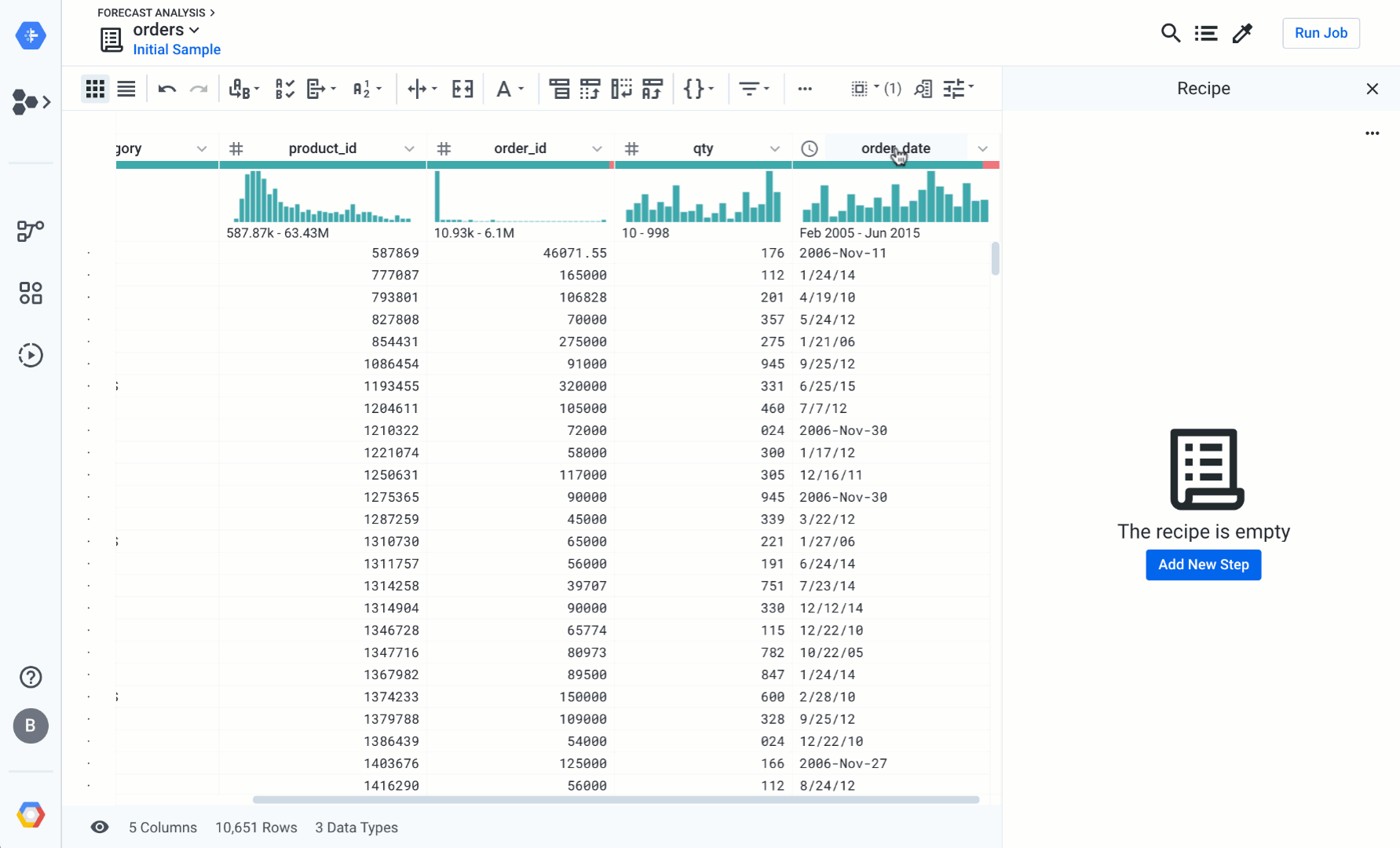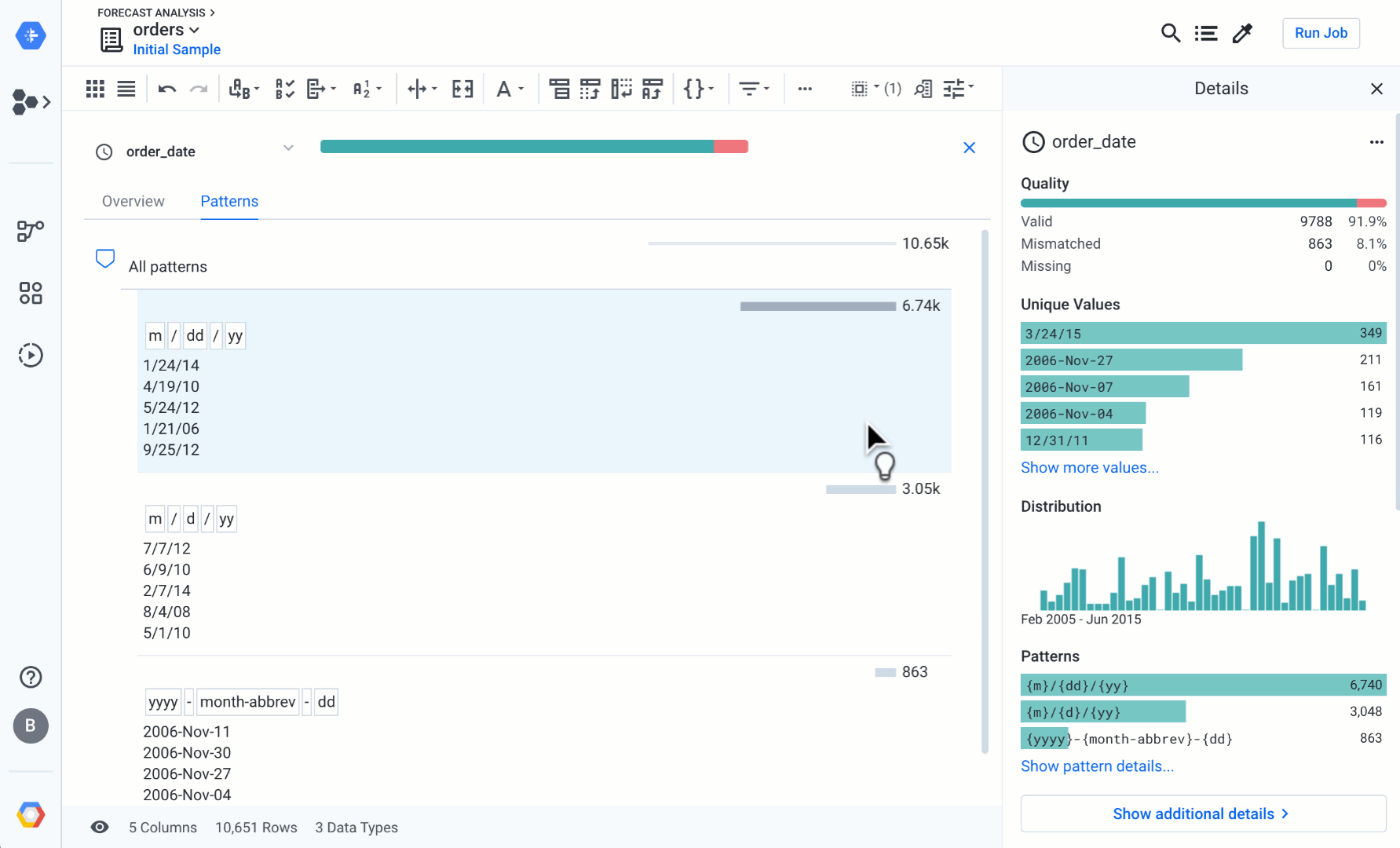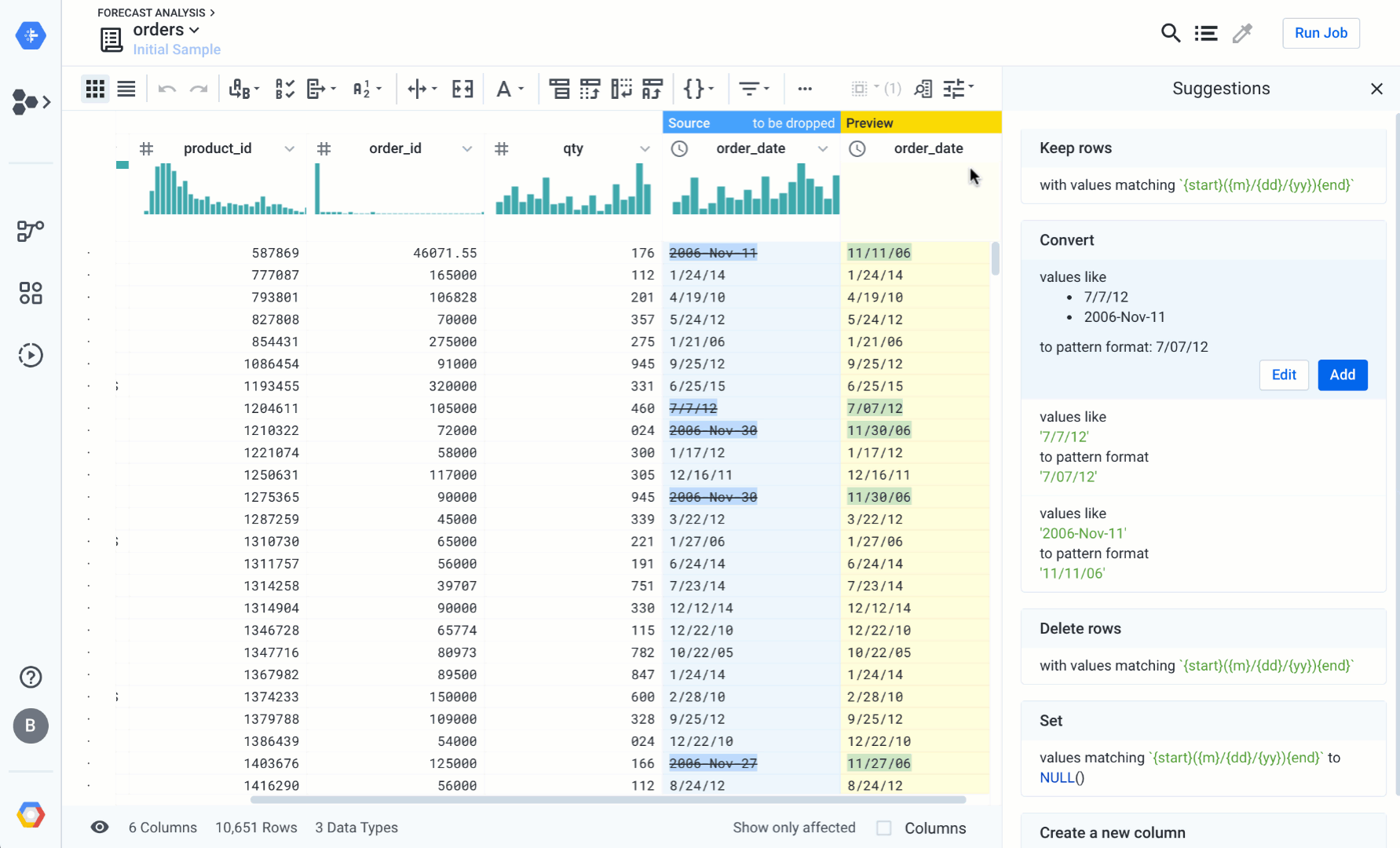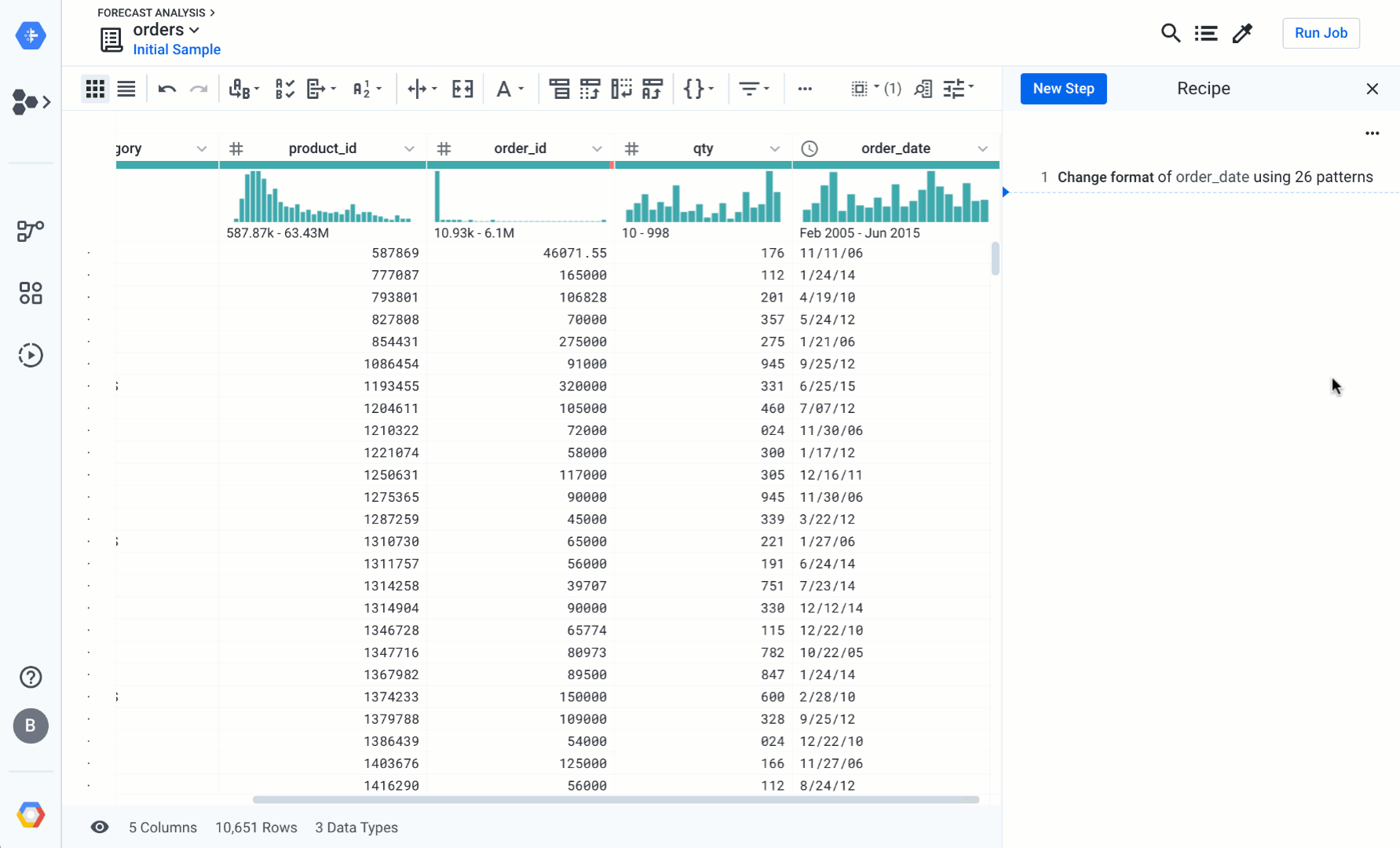
If you click on a column header, you’ll see some extra statistics in the right panel of Dataprep. This is particularly useful if you expect a specific format standard for a field and want to identify the values that don’t comply to the standard. In the example below, you can see that Cloud Dataprep discovered three different format patterns for the order_date. You might have follow-up questions: can empty order dates be leveraged in the forecast? Can mismatched dates can be corrected and how can you correct them?
Advanced profiling
If you click “Show more”, or click the column header menu and “column details” in the main grid, you’ll land on a comprehensive data profiling page with some details about mismatched values, value distribution, or outliers. You can also navigate to the pattern tab to explore the data structure within a specific column.
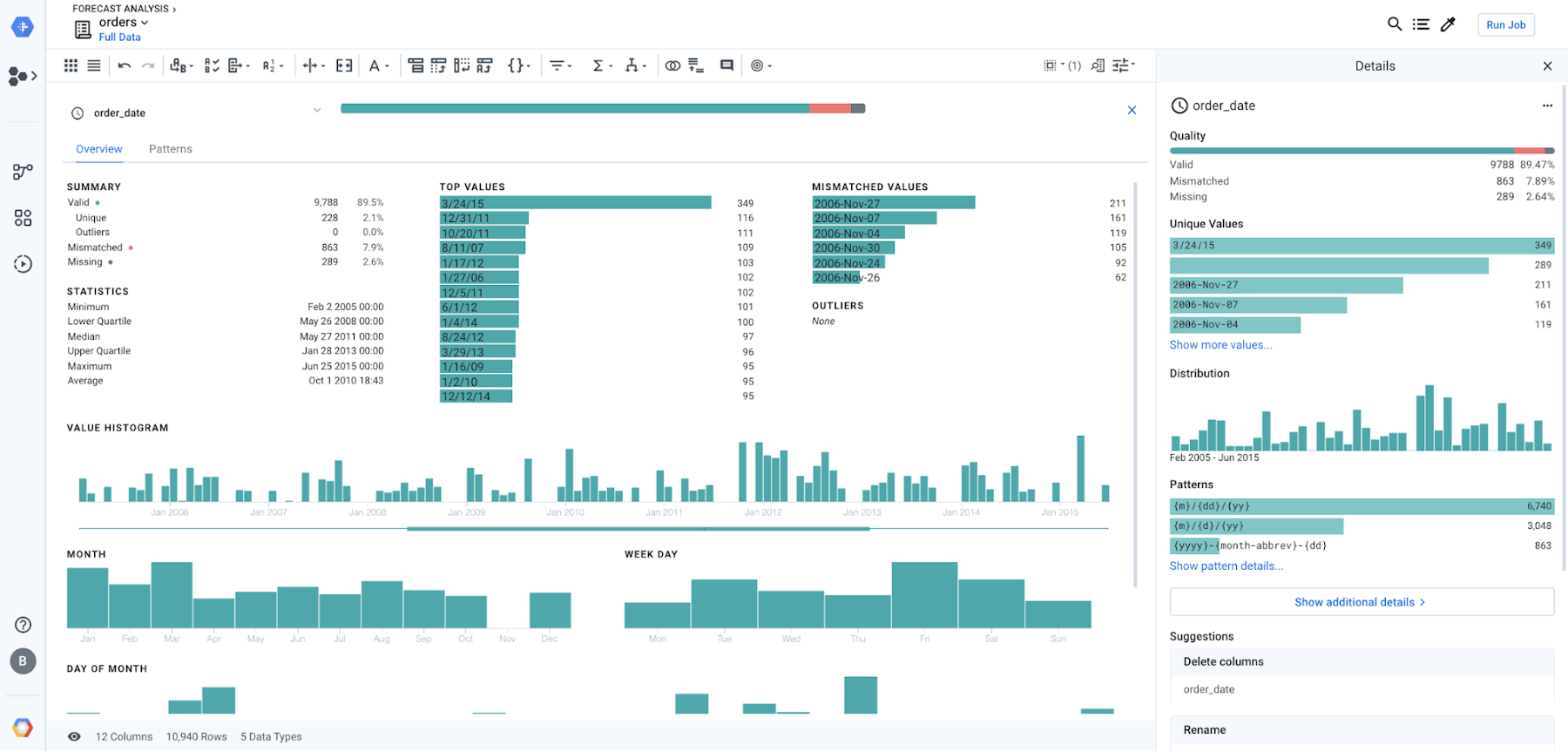
These three data profiling capabilities are dynamic by nature in the sense that Cloud Dataprep reprofiles the data in real time at each step of a transformation, to always present you with the latest information. This helps you clean your data faster and more effectively.
The value for the forecast analyst is that she can immediately validate as she goes through the process of cleaning and transforming the data so that it fits the format she expects for her downstream modeling and reporting.
2. Resolving data quality issues
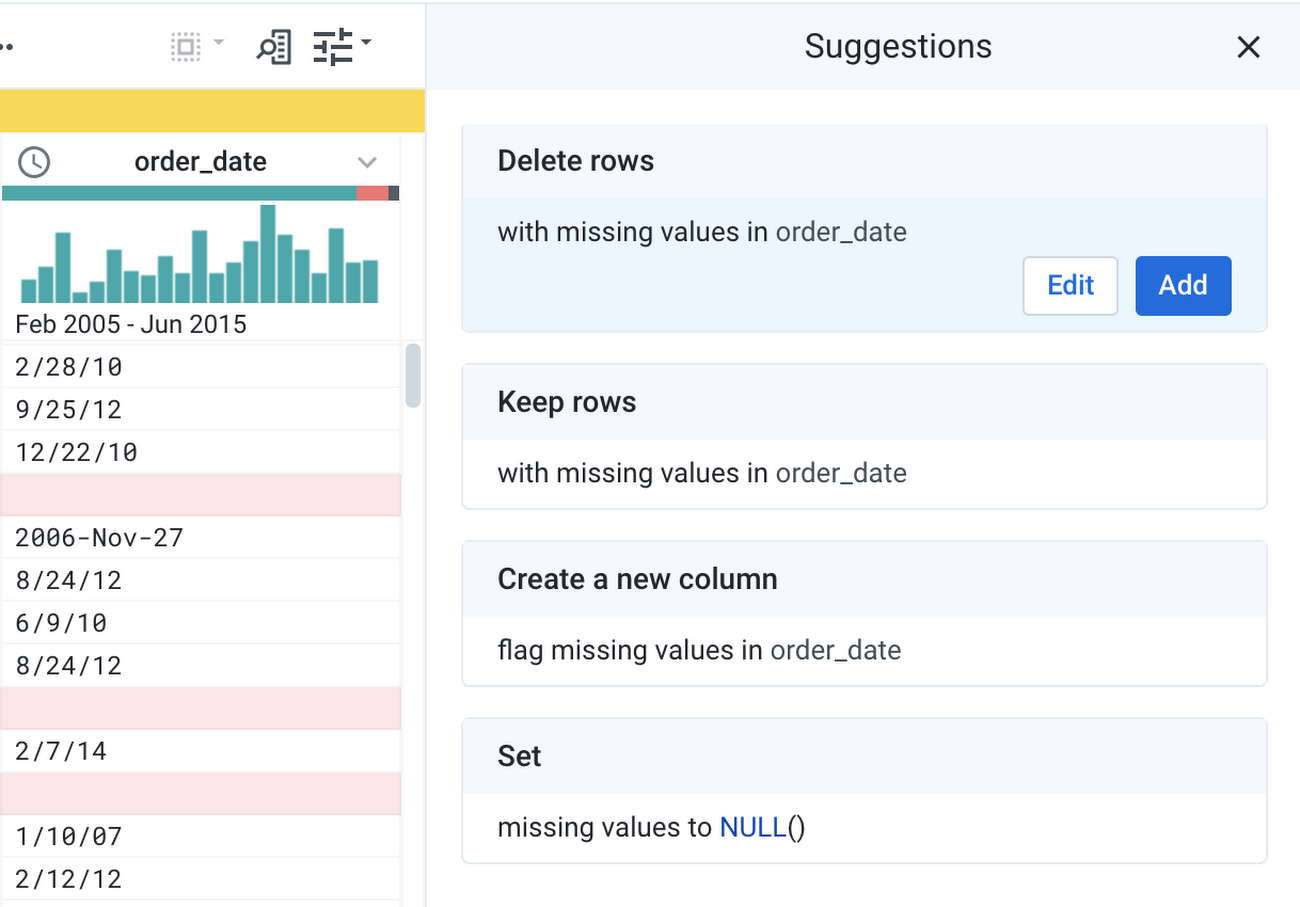
Dynamic profiling helps you assess the data quality at hand, and it is also the point of entry to start cleaning the data. Graph profiles are interactive and offer transformation suggestions as soon as you interact with them. For example, clicking the missing value space in the column header displays transformation suggestions such as deleting the values or setting the values to a default one.
Resolving incorrect patterns
You can efficiently resolve incorrect patterns in a column (such as the recurrent date formatting issue in the order_data column) by accessing the pattern tab in the column details screen. Cloud Dataprep shows you the most frequent patterns. Once you select a target conversion format, Cloud Dataprep displays some transformation suggestions on the right panel, to convert all the data to fit the selected pattern. Watch the animation below, and try it for yourself:
Highlight over data content
Another interactive way to clean your data is to highlight over some portion of a value in a cell. Cloud Dataprep will suggest a set of transformations based on your selection, and you can refine the selection by highlighting over some additional content from another cell. Here is an example that extracts the month from the order date in order to calculate the volume per month:
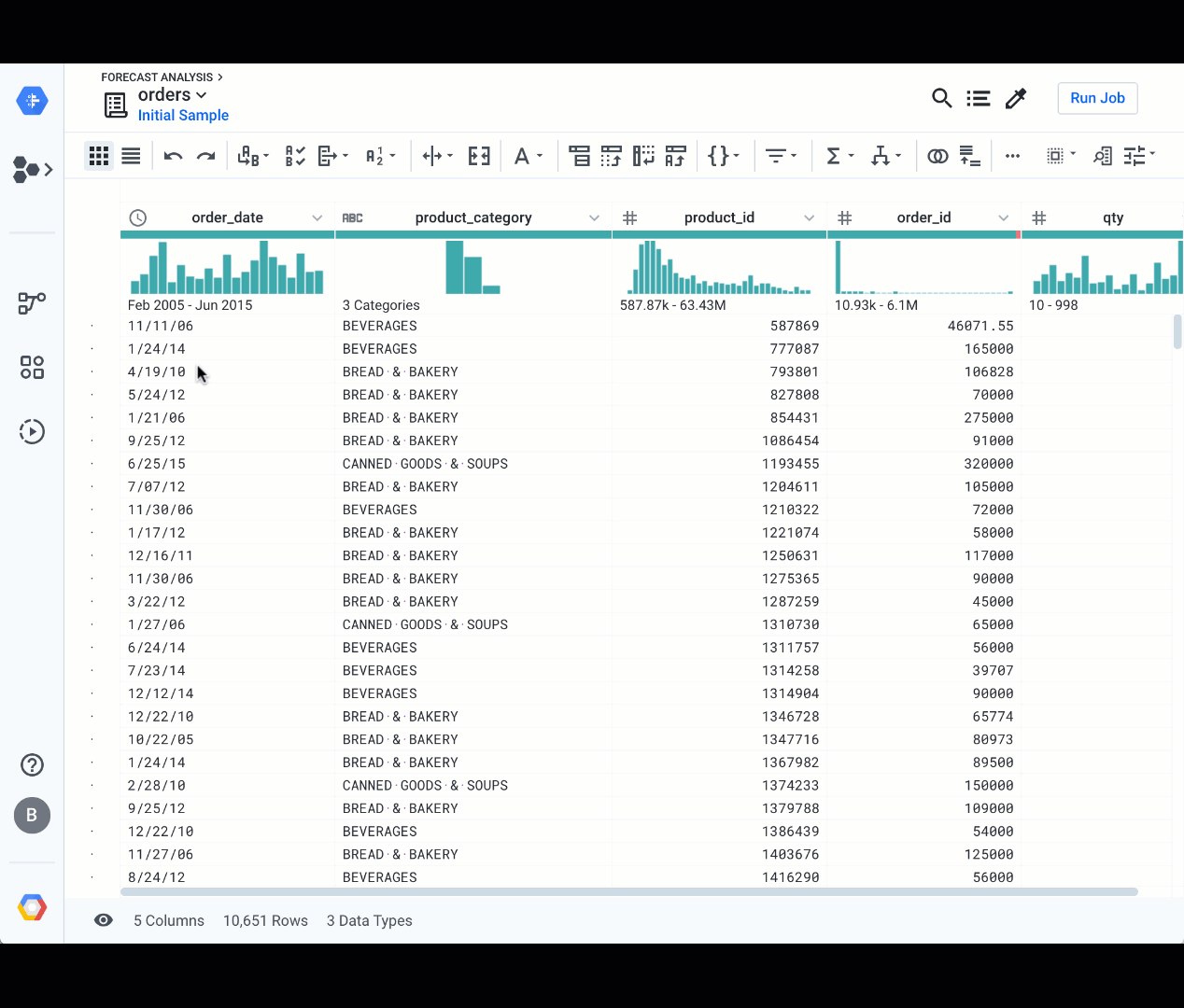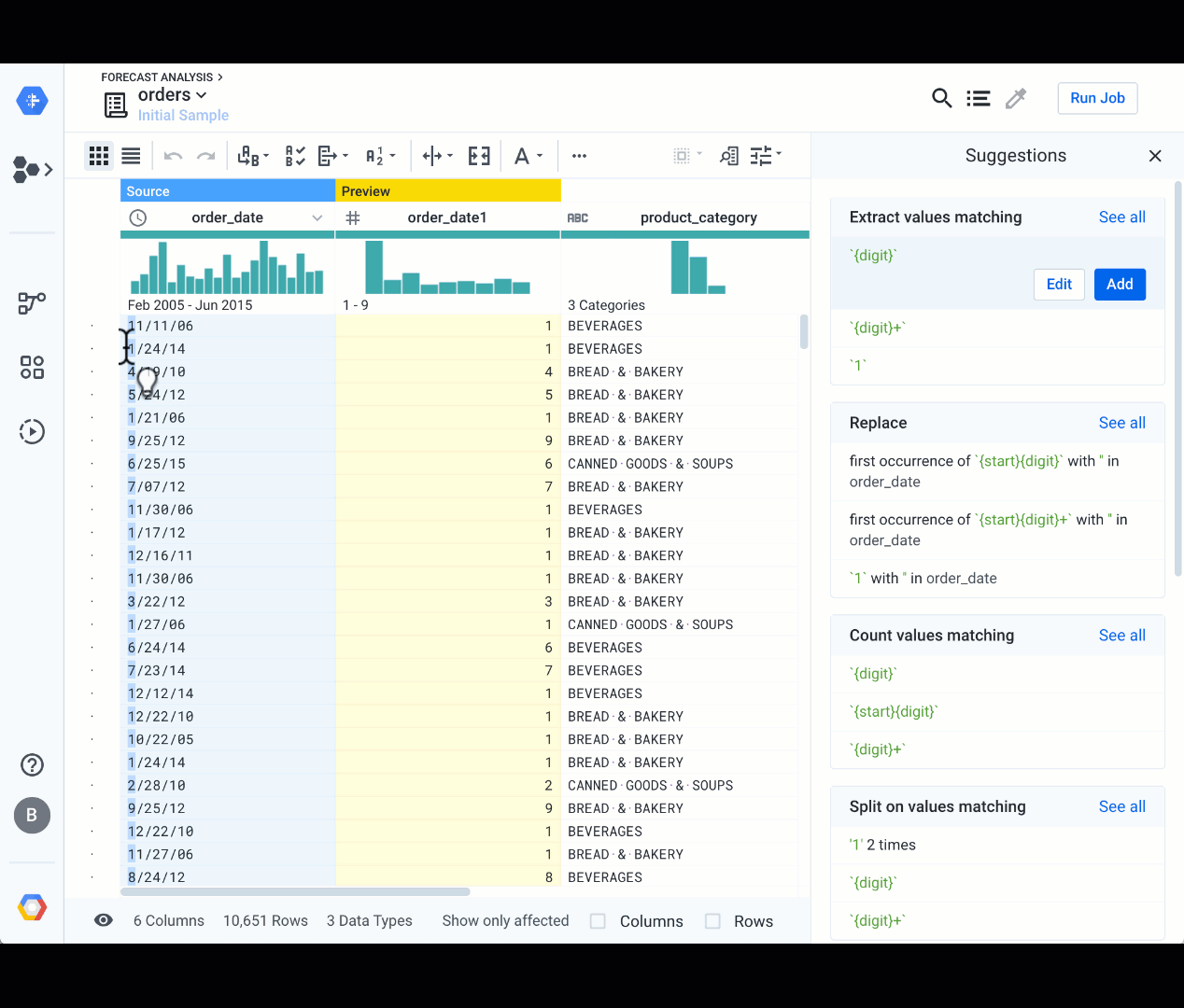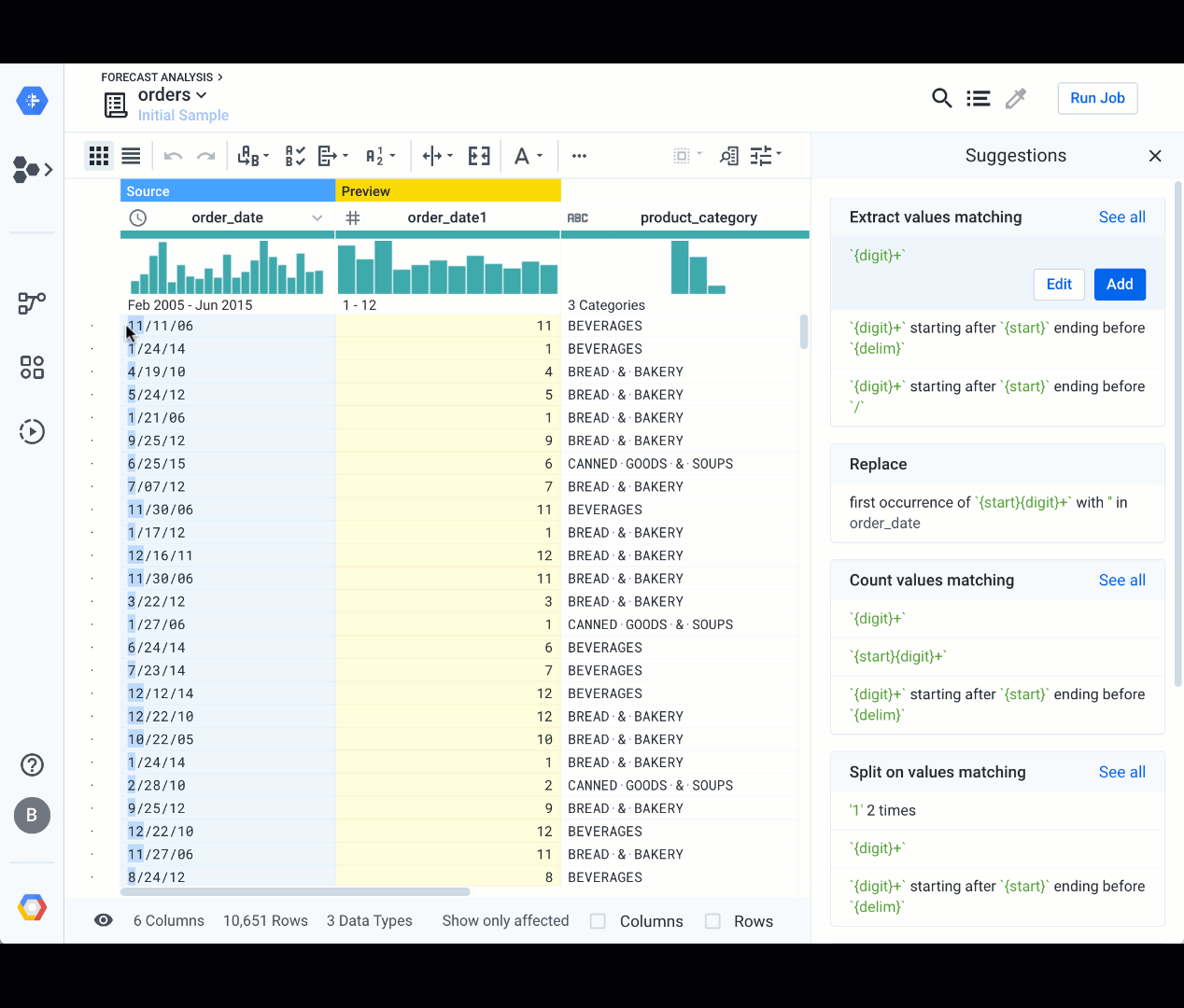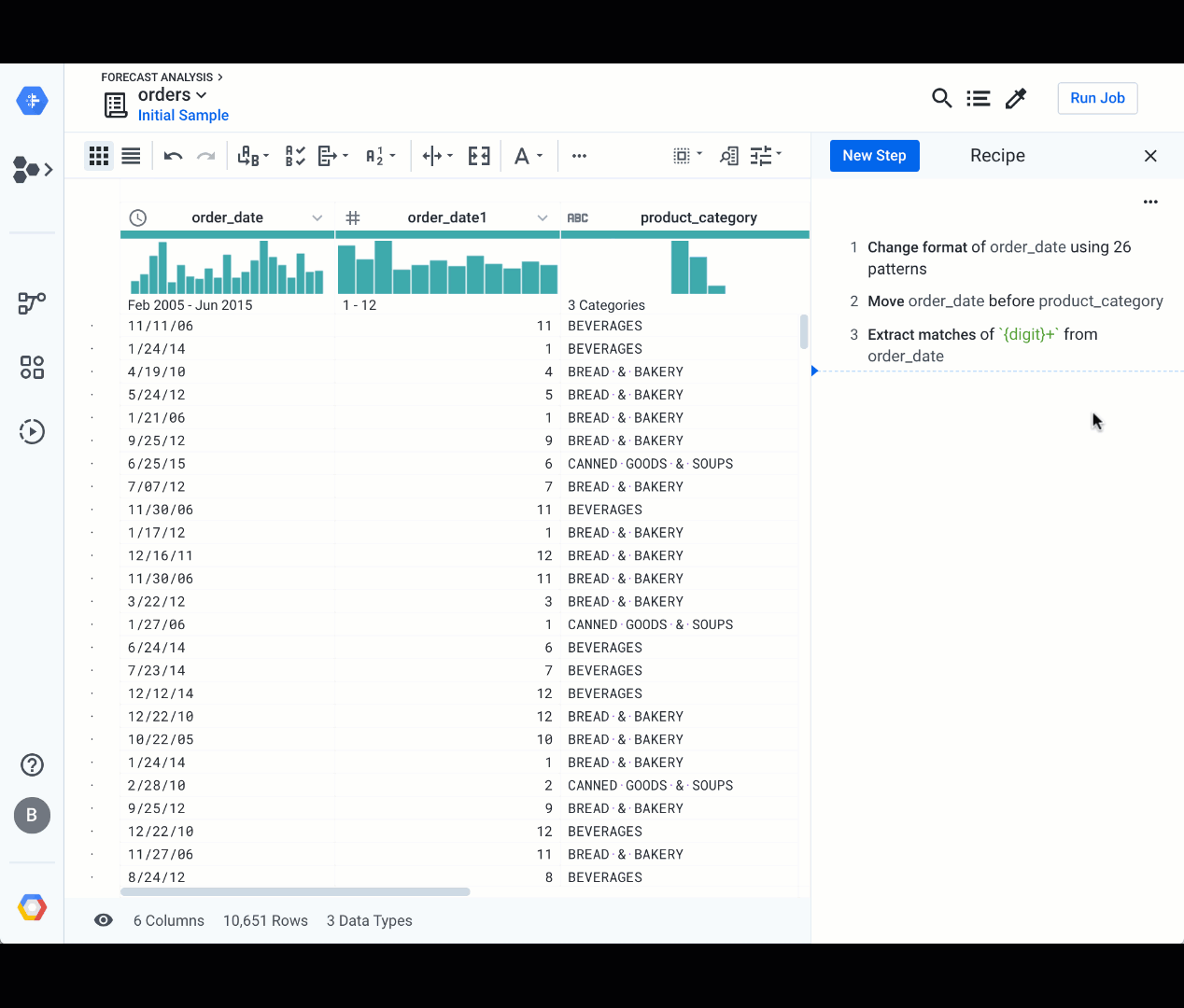
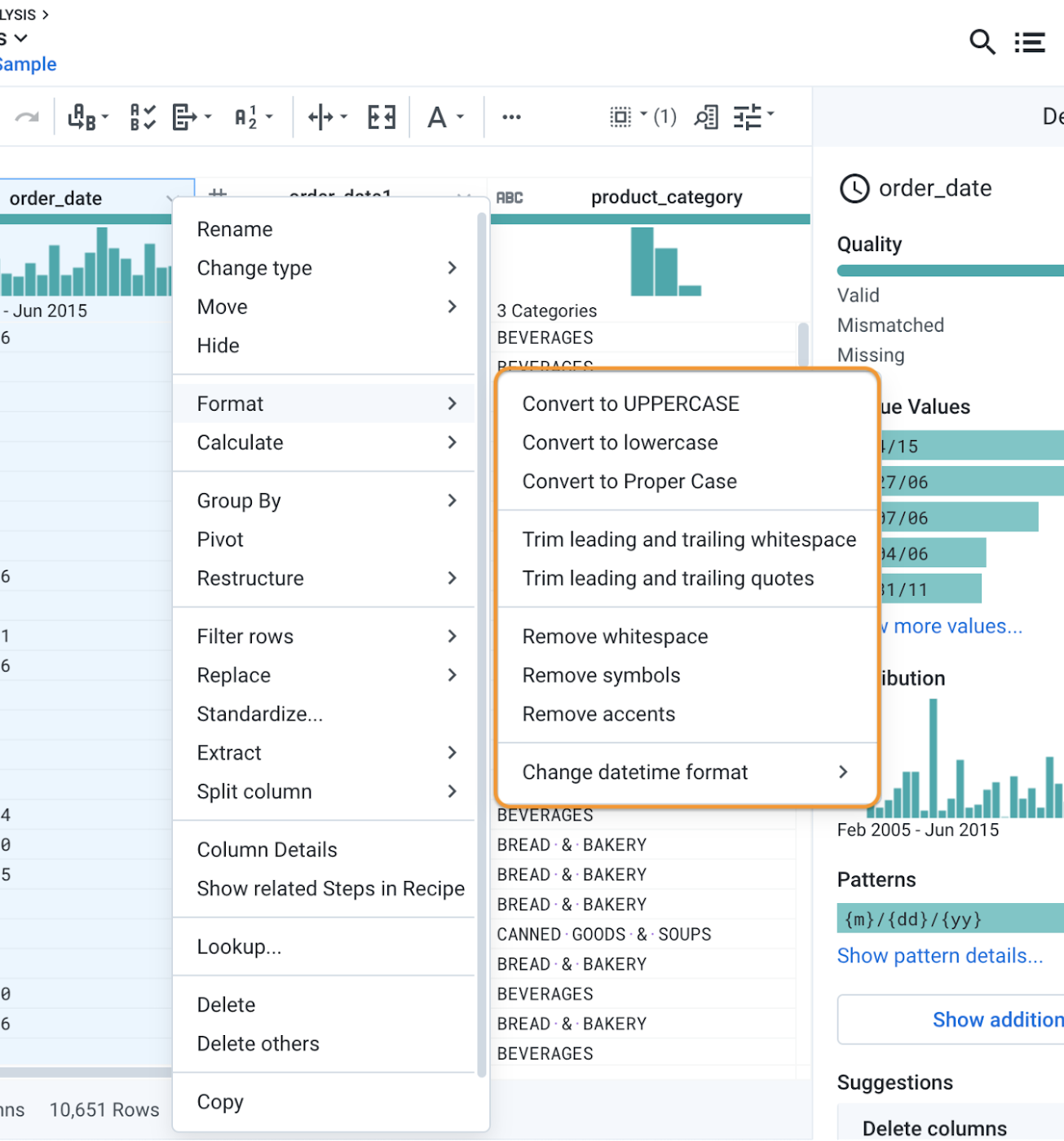
Format, replace, conditional functions, and more
You can find most of the functions you’ll use to clean up data in the Column menu from the format or replace sections, or in the conditional formulas in the icon bar as shown below. These can be useful to convert all product or category names into uppercase or trim the names that have often quotes after import from a CSV or Excel file.
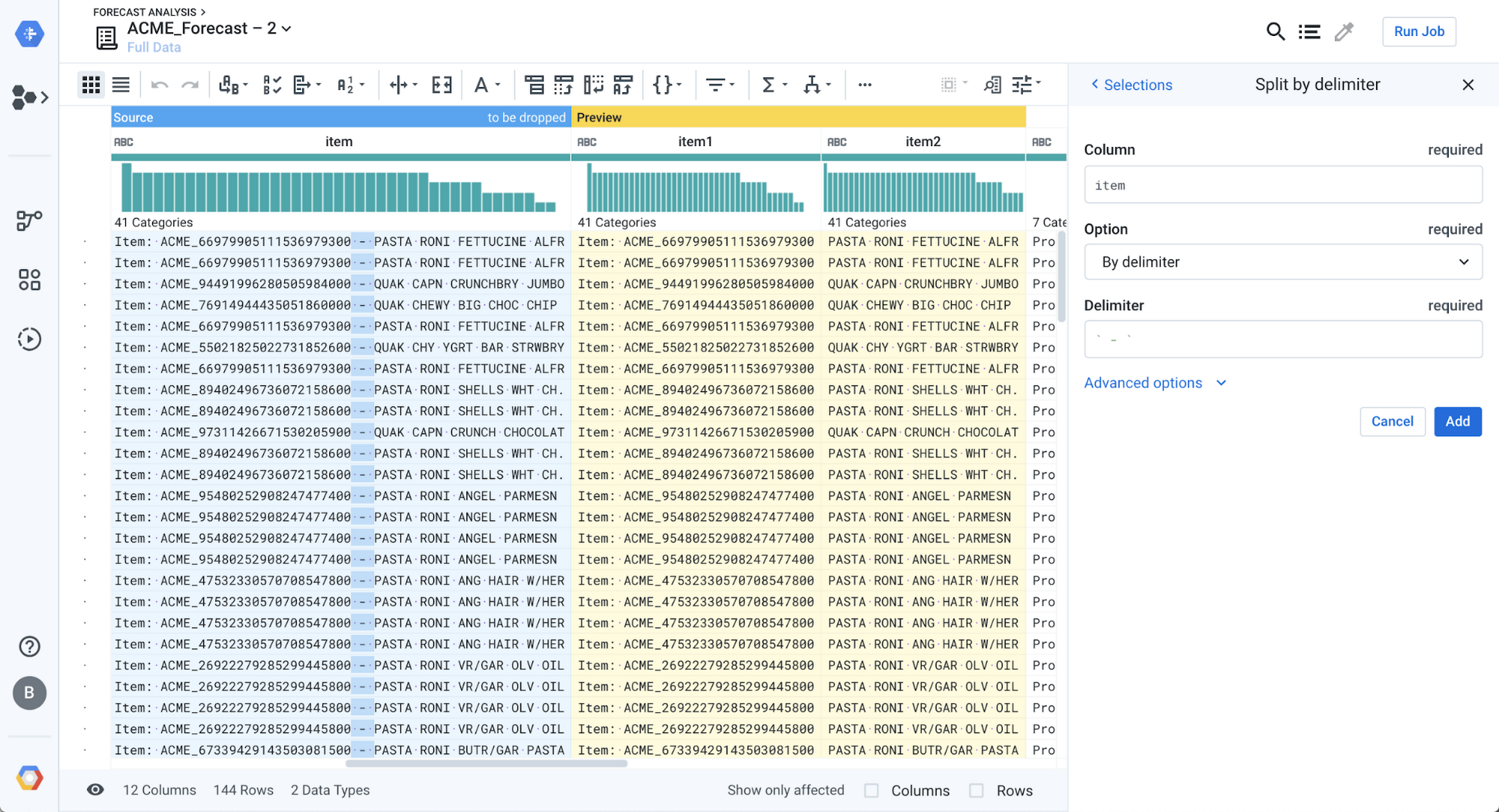
The extract functions can be particularly useful to extract a subset of a value within a column. For example, you may want to extract from the product_id “Item: ACME_66979905111536979300 - PASTA RONI FETTUCINE ALFR” each individual component by splitting it on the “ - ” value.
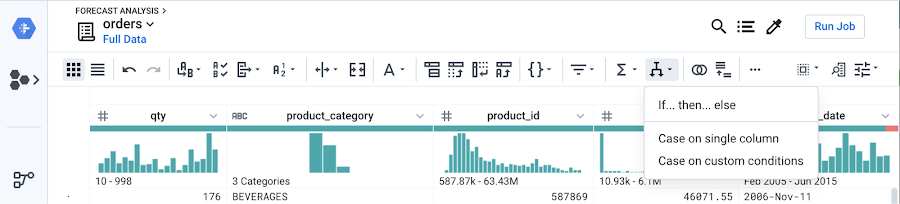
Conditional functions are useful for tagging values that are out of scope. For example you can write a formula that will tag records when a quantity is over 10,000, which wouldn’t be valid for the order sizes you typically encounter.
If none of the visual suggestions give you what you require for cleaning your data, you can always edit a suggestion or manually adding a new step in a Dataprep recipe. Type in a search box what you want to do and Cloud Dataprep will suggest some transformations you can then edit and apply to the dataset.
Standardization
Standardizing values is a way to group similar values into a single, consistent format. This problem is especially prevalent with free-form entries like product, product categories, company names. You can access the standardization feature from the Column menu. Additionally, Cloud Dataprep can group similar values together by string similarities or by pronunciation.
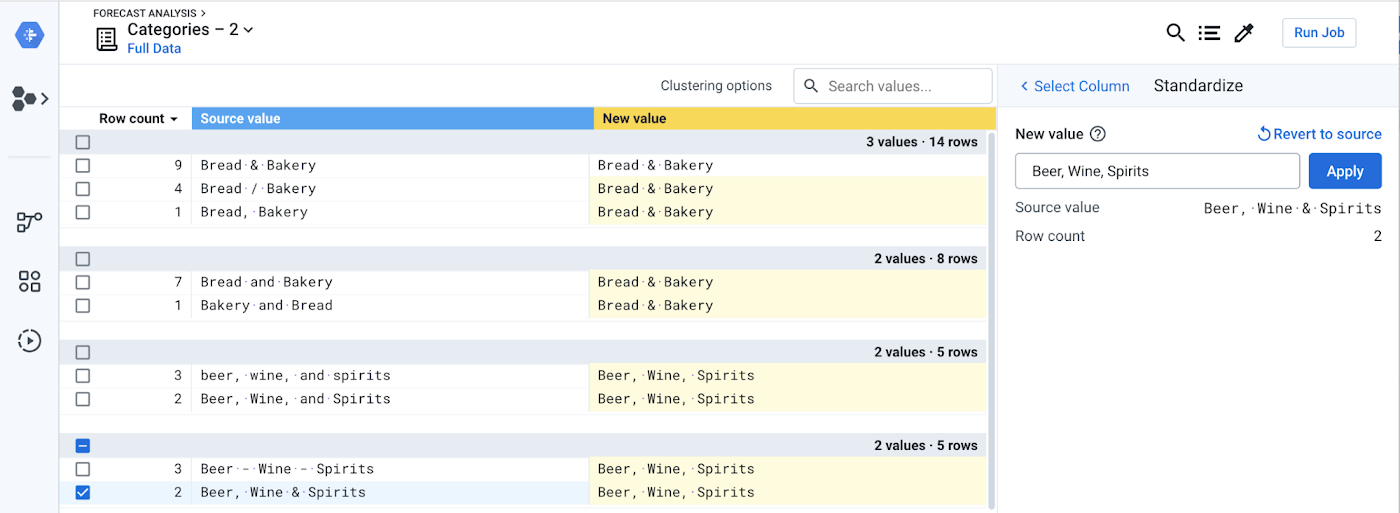
Tip: You can mix-and-match standardization algorithms. Some values may be standardized using spelling, while others are more sensibly standardized based on international pronunciation standards.
3. Validation at scale
The last, critical step of a typical data quality workflow in Cloud Dataprep is to validate that no single data quality issue remains in the dataset, at scale.
Leveraging sampling to clean data
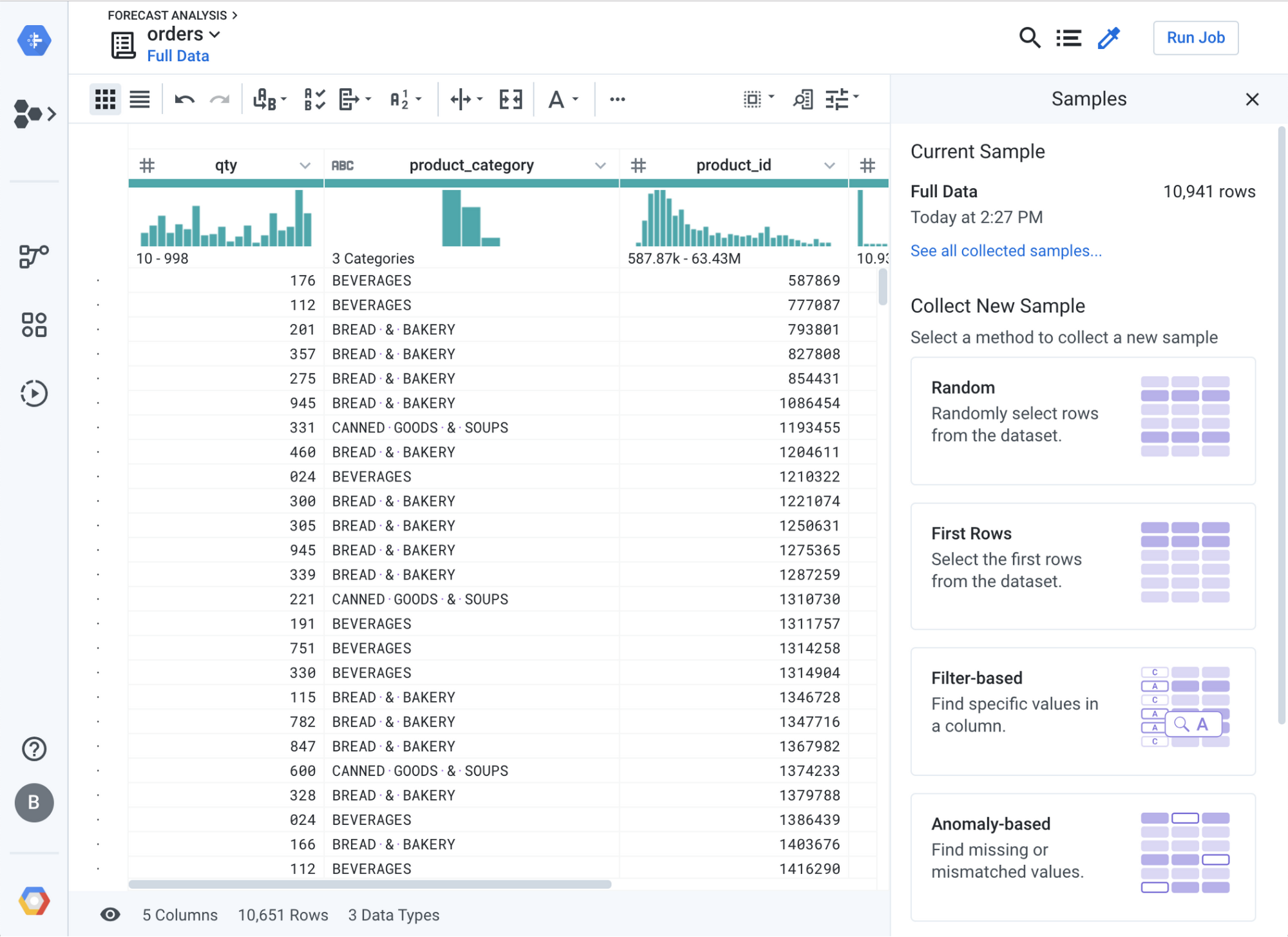
Sometimes, the full volume of a dataset won’t fit into Cloud Dataprep via your browser tab (especially when leveraging BigQuery tables with hundreds of millions of records or more). In that case, Cloud Dataprep automatically samples the data from BigQuery to fit it in your local computer’s memory. That might lead you to question: how can you ensure you’ve standardized all the data from one column (e.g. product name, category, region, etc.) or you have cleaned all the date formats from another?
You can adjust your sampling settings by clicking the sampling icon at the top right and choosing the sampling technique that fits your requirements.
Select anomaly-based to keep all the data mismatched or missing for one of multiple columns
Select stratified to retrieve every distinct value for a particular column (particularly useful for standardization)
Select filter-based to retrieve all the data based on particular formula (i.e format does not match dd/mm/yyyy)
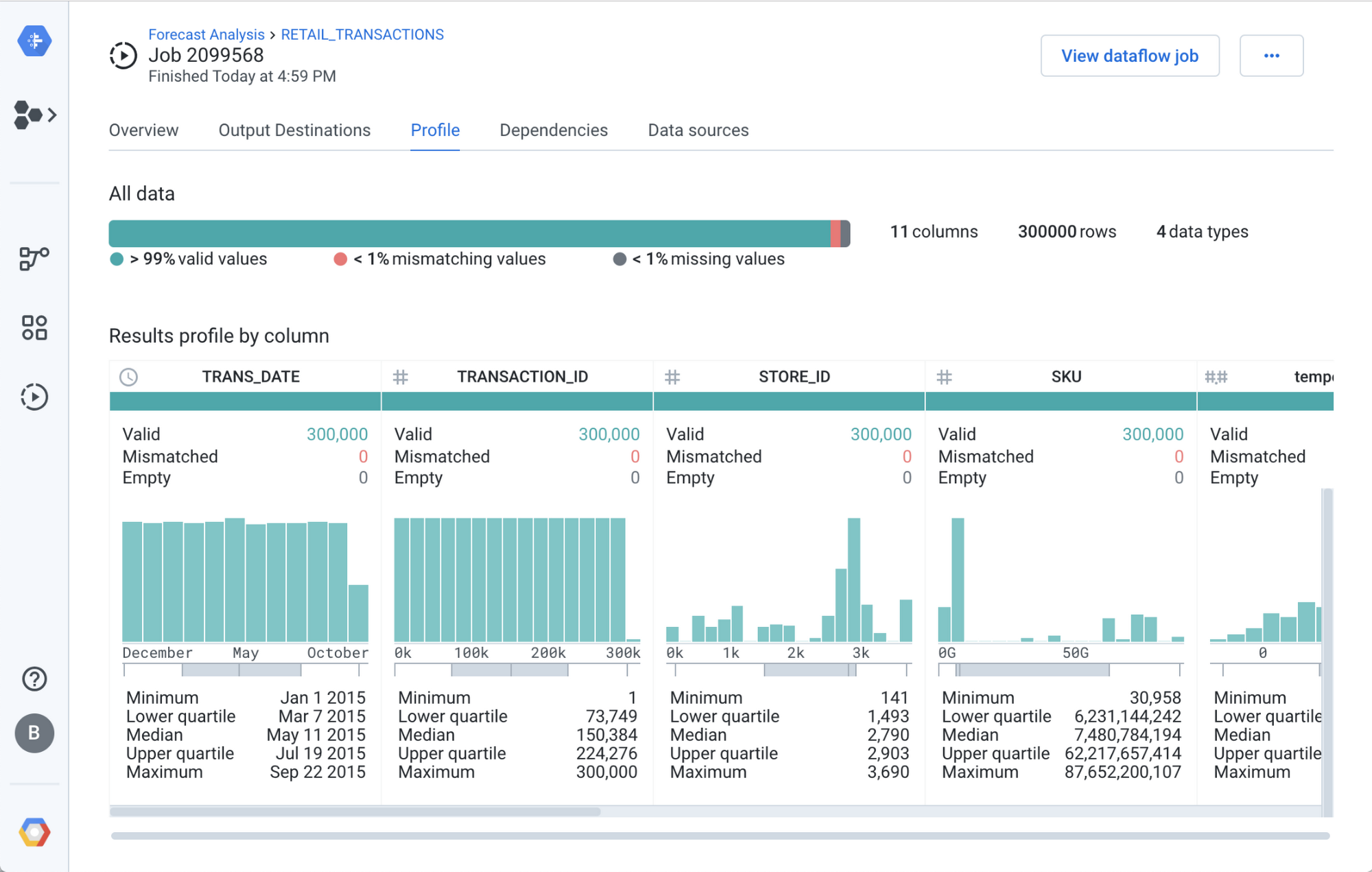
Profiling the data at scale
At this point, hopefully you’re happy and confident that your recipe will produce a clean dataset, but until you run it at scale across the whole data set, you can’t ensure all your data is valid. To do so, click the ‘Run Job’ button and check that Profile Results is enabled.
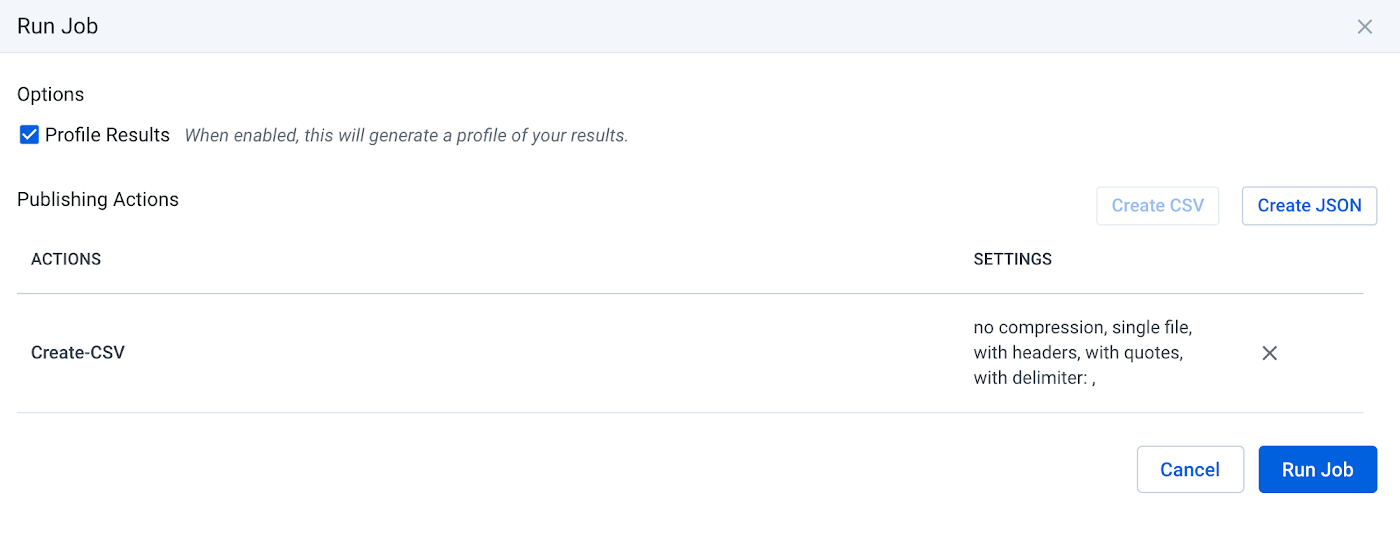
If in the job results you still see some red, this most likely means you need to adjust your data quality rules and try again.
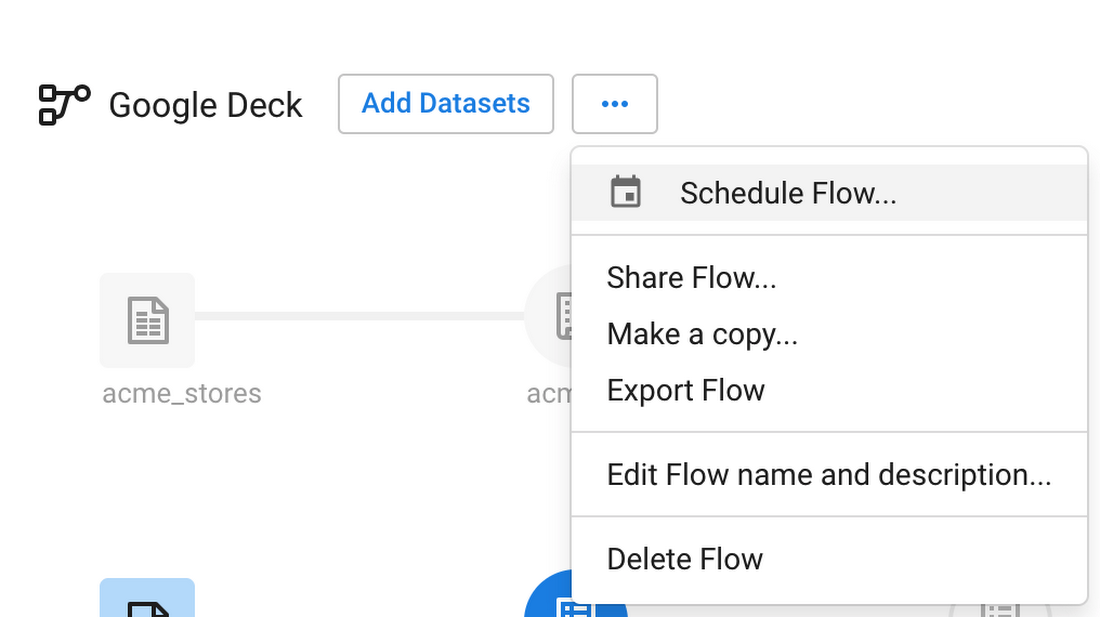
Scheduling
To ensure that the data quality rules you create are applied on a recurring basis schedule your recipes to run automatically. In the case of forecasting, data may change on a weekly basis, so users must run the job every week to validate that all the profile results stay green over time. If not, you can simply reopen and adapt the recipe to address the new data inconsistencies you discovered.
In the flow view, select Schedule Flow to define the parameters to run the job on a recurring basis.
Conclusion
Our example here is retail-specific, but regardless of your area of expertise or industry, you may encounter similar data issues. Following this process and leveraging Cloud Dataprep, you can become more effective and faster at cleaning up your data for analytics or feature engineering.
We hope you that by using Cloud Dataprep, the toil of cleaning up your data and improving your data quality is, well, not so messy. If you’re ready to start, log in to Dataprep via Google Cloud Console to start using this three-step data quality workflow on your data.