How we used Cloud Spanner to build our email personalization system—from “Soup” to nuts
Haruka Matsuzaki
Engineer, Data/AI Strategy Management, Recruit Technologies
Yuta Hono
Customer Engineer, Google Cloud
Editor’s note: Today we hear from Tokyo-based Recruit Technologies Co., Ltd., whose email marketing platform is built on top of GCP. The company recently migrated its database to Cloud Spanner for lower cost and operational requirements, and higher availability compared to their previous HBase-based database system. Cloud Spanner also allows Recruit to calculate metrics (KPIs) in real time without having to transfer the data first. Read on to learn more about their workload and how Cloud Spanner fits into the picture.
There are just under 8 billion people on Earth, depending on the source. Here at Recruit, our work is to develop and maintain an email marketing system that sends personalized emails to tens of millions of customers of hundreds of web services, all with the goal of providing the best, most relevant customer experience.
When Recruit was founded in 1960, the company was focused on helping match graduates to jobs. Over the years, we’ve expanded to help providers that deal with almost every personal moment and event a person encounters in their life. From travel plans to real estate, restaurant choices to haircuts, we offer software and services to help providers deliver on virtually everything and connect to their end-customers.
Recruit depends on email as a key marketing vehicle to end-customers and to provide a communications channel to clients and advertisers across its services. To maximize the impact of these emails, we customize each email we send. To help power this business objective, we developed a proprietary system named “Soup” that we host on Google Cloud Platform (GCP). Making use of Google Cloud Spanner, Soup is the connective tissue that manages the complex customization data needed for this system.
Of course, getting from idea to functioning product is easier said than done. We have massive datasets so requirements like high availability and serving data in real-time are particularly tricky. Add in a complex existing on-premises environment, some of which we had to maintain in our journey to the cloud creating a hybrid environment, and the project became even more challenging.
A Soup primer
First, why the name “Soup”? The name of the app is actually “dashi-wake” in Japanese, from “dashi,” a type of soup. In theory, Soup is a fairly simple application: its API returns recommendation results based on the data we compute about a user via the user's user ID. Soup ingests pre-computed recommendations and then serves those recommendations to the email generation engine and tracks metrics. While Soup doesn’t actually send the customer emails, it manages the entire volume of personalization and customization data for tens of millions of users. It also manages the computed metrics associated with these email sends such as opens, clicks, and other metadata.Soup leverages other GCP services such as App Engine Flex (Node.js), BigQuery, Data Studio, and Stackdriver in addition to Cloud Spanner.
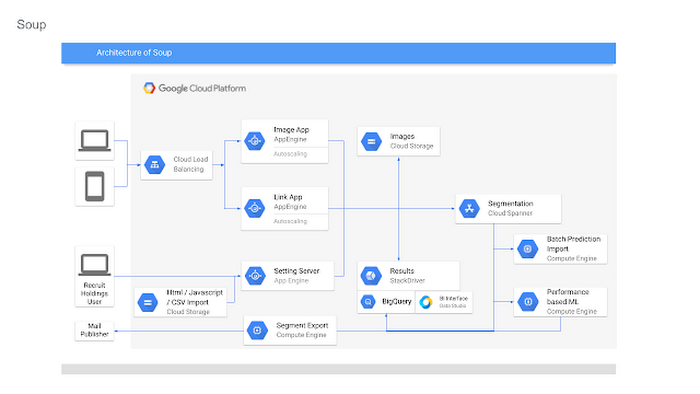
Soup requirements
High availabilityIf the system is unavailable when a user decides to open an email they see a white screen with no content at all. Not only is that lost revenue for that particular email, it makes customers less likely to open future emails from us.
Low latency
Given a user ID, the system needs to search all its prediction data and generate the appropriate content—an HTML file, an image, multiple images, or other content—and deliver it, all very quickly.
Real-time log ingestion and fast JOINs
In today’s marketing environment, tracking user activity and being able to make dynamic recommendations based on it is a must-have. We live in an increasingly real-time world. In the past, it might have been OK to take a week or longer to adapt content based on customer behavior. Now? A delay of even a day can make the difference between a conversion and a lost opportunity.
The problem
Pushing out billions of personalized emails to tens of millions of customers comes with some unique challenges. Our previous on-premises system was based on Apache HBase, the open-source NoSQL database, and Hive data warehouse software. This setup presented three major obstacles:Cluster sizing
Email marketing is a bursty workload. You typically send a large batch of emails, which requires a lot of compute, and then there’s a quiet period. For our email workloads, we pre-compute a large set of recommendations and then serve those recommendations dynamically upon email open. On-premises, there wasn’t much flexibility and we had to resize clusters manually. We were plagued by errors whenever loads of email opens and the resulting requests to the system outpaced the traffic we could handle, because the cluster size of our HBase/Hive system couldn’t keep up.
Performance
The next issue was optimizing the schema model for performance. Soup has a couple of main functions: services write customer tracking data to it, and downstream “customers” read that data from it to create the personalized emails. On the write side, after the data is written to Soup, the writes need to be aggregated. We initially did this on-premises, which was quite difficult and time consuming because Hbase’s doesn’t offer aggregation queries, and because it was hard to scale in response to traffic bursts.
Transfer delays
Finally, every time we needed to generate a recommendation model for a personalized email blast, we needed to transfer the necessary data from HBase to Hive to create the model, then back to HBase. These complex data transfers were taking two-to-three days. Needless to say, this didn’t allow for the type of agility that we need to provide the best service to our customers.
Cloud Spanner allows us to store all our data in one place, and simply join the data tables and do aggregates; there’s no need for a time-intensive data transfer. Using this model, we believe we can cut the recommendation generation time from days to under a minute, bringing real-time back into the equation.
Why Cloud Spanner?
Compared to the previous application running on-premises, Cloud Spanner offers lower cost, lower operations requirements and higher availability. Most critically, we wanted to calculate metrics (KPIs) in real time without data transfer. Cloud Spanner allows us to do this by pumping SQL queries into a custom dashboard that monitors KPIs in real time.
Soup now runs on GCP, although the recommendations themselves are still generated in an on-premise Hadoop cluster. The computed recommendations are stored in Cloud Spanner for the reasons mentioned above. After moving to GCP and architecting for the cloud, we see an error rate of .005% per second vs. a previous rate of 4% per second, an improvement of 1/800. This means that for an email blast sent to all users in Japan, one user won’t be able to see one image in one email. Since these emails often contain 10 images or more, this error rate is acceptable.
Cloud Spanner also solved our scaling problem. In the future, Soup will have to support one million concurrent users in different geographical areas. Likewise, Soup has to perform 5,000 queries per second (QPS) at peak times on the read side, and will expand this requirement to 20,000 to 30,000 QPS in the near future. Cloud Spanner can handle all the different, complex transactions Soup has to run, while scaling horizontally with ease.
Takeaways
In migrating our database to Cloud Spanner, we learned many things that are worth taking note of, whether you have 10 or 10 million users.Be prepared to scale
We took scaling into account from Day One, sketching out specific requirements for speed, high availability, and other metrics. Only by having these requirements specifically laid out were we able to choose—and build—a solution that could meet them. We knew we needed elastic scale.
With Cloud Spanner, we didn’t have to make any of the common trade-offs between the relational database structure we wanted, and the scalability and availability needed to keep up with the business requirements. Likewise, with a growing company, you don’t want to place any artificial limits on growth, and Cloud Spanner’s ability to scale to “arbitrarily large” database sizes eliminates this cap, as well as the need to rewrite or migrate in the future as our data needs grow.
Be realistic about downtime
For us, any downtime can result in literally thousands of lost opportunities. That meant that we had to demand virtually zero downtime from any solution, to avoid serving up errors to our users. This was an important realization. Google Cloud provides an SLA guarantee for Cloud Spanner. This solution is more available and resistant to outages than anything we would build on our own.
Don’t waste time on management overhead
When you’re worrying about millions of users and billions of emails, the last thing you have time to do is all the maintenance and administrative tasks required to keep a database system healthy and running. Of course, this is true for the smallest installations, as well. Nobody has a lot of extra time to do things that should be taken care of automatically.
Don’t be afraid of hybrid
We found that a hybrid architecture that leverages the cloud for fast data access but still using our existing on-premises investments for batch processing to be effective. In the future, we may move the entire workload to the cloud but data has gravity, and we currently have lots of data stored on-premises.
Aim for real-time
At this time, we can only move data in and out of Cloud Spanner in small volumes. This prevents us from making real-time changes to recommendations. Once Cloud Spanner supports batch and streaming connections, we'll be able to enable an implementation to provide more real-time recommendations to deliver even more relevant results and outcomes.
Overall, we’re extremely happy with Cloud Spanner and GCP. Google Cloud has been a great partner in our move to the cloud, and the unique services provided enable us to offer the best service to our customers and stay competitive.



