How release canaries can save your bacon—CRE life lessons
Adrian Hilton
Customer Reliability Engineer, SRE
The first part of any reliable software release is being able to roll back if something goes wrong; we discussed how we do this at Google in last week’s post, Reliable releases and rollbacks. Once you have that under your belt, you’ll want to understand how to detect that things are starting to go wrong in the first place, with canarying.

The concept of canarying first emerged in 1913 when physiologist John Scott Haldane took the caged bird down into a coal mine, to detect for carbon monoxide. This fragile bird is more susceptible to the odorless gas than humans, and quickly falls off its perch in its presence — signaling to the miners that it’s time to get out!
In software, a canary process is usually the first instance that receives live production traffic about a new configuration update, either a binary or configuration rollout. The new release only goes to the canary at first. The fact that the canary handles real user traffic is key: if it breaks, real users get affected, so canarying should be the first step in your deployment process, as opposed to the last step in testing.
The first step in implementing canarying is a manual process where release engineers trigger the new binary release to the canary instance(s). They then monitor the canary for any signs of increased errors, latency and load. If everything looks good, they then trigger a release to the rest of the production instances.
We here on Google’s SRE teams have found over time that manual inspection of monitoring graphs isn’t sufficiently reliable to detect performance problems or rises in error rates of a new release. When most releases work well, the release engineer gets used to seeing no problems and so, when a low-level problem appears, tends to implicitly rationalize the monitoring anomalies as “noise.” We have several internal postmortems on bad releases whose root cause boils down to “the canary graph wasn’t wiggly enough to make the release engineer concerned.”
We've moved towards automated analysis, where our canary rollout service measures the canary tasks to detect elevated errors, latency and load automatically — and roll back automatically. (Of course, this only works if rollbacks are safe!)
Likewise, if you implement canaries as part of your releases, take care to make it easy to see problems with a release. Consider very carefully how you implement fault tolerance in your canary tasks; it’s fine for the canary to do the best it can with a query, but if it starts to see errors either internally or from its dependency services then it should “squawk loudly” by manifesting those problems in your monitoring. (There’s a good reason why the Welsh miners didn’t breed canaries to be resistant to toxic gases, or put little gas masks on them.)
Client canarying
If you’re doing releases of client software, you should have a mechanism for canarying new versions of the client, and you'll need to answer the following questions:- How will you deploy the new version to only a small percentage of users?
- How will you detect if the new version is crash-looping, dropping traffic or showing users errors? (“What's the monitoring sound of no queries happening?”)
ideally, by including information in each request about the client’s operating system and application version ID — and for the server to log this information. If you can make the clients identify themselves specifically as canaries, so much the better; this lets you export their stats to a different set of monitoring metrics. To detect that clients are failing to send queries, you'll generally need to know what the lowest plausible amount of incoming traffic is at any given time of the day or week, and trigger an alert if inbound traffic drops below that amount.
Typically, alerting rules for canaries for high-availability systems use a longer evaluation duration (how long you listen to the monitoring signals before deciding you have a problem) than for the main system because the much smaller traffic amount makes the standard signal much noisier; a relatively innocuous problem such as a few service instances being restarted can briefly push the canary error rate above the regular alarm threshold.
Your release should normally aim to cover a wide range of user types but a small fraction of active users. For Android clients, the Google Play Store allows you to deploy a new version of your application package file (APK) to an (essentially random) fraction of users; you can do this on a country-by-country basis. However, see the discussion on Android APK releases below for the limitations and risks in this approach.
Web clients
If your end users access your service via desktop or mobile web rather than an application, you tend to have better control of what’s being executed.Regular web clients whose UI is managed by JavaScript are fairly easy to control in that you have the potential to deliver updated JavaScript resources to them every time a page loads. However, if you cache JavaScript and similar resources client-side — which is useful in reducing service load and user latency+bandwidth consumption — it’s hard to roll back a bad change. As we discussed in our last post, anything that gets in the way of easy and quick rollbacks is going to be a problem.
One solution is to version your JavaScript files (first release in a /v1/ directory, second in a /v2/ etc.). Then the rollout simply consists of changing the resource links in your root pages to reference the new (or old) versions.
Android APK releases
New versions of an Android app can be rolled out to a % of current users using staged rollouts in the Play Store. This lets you try out a new release of an app on a small subset of your current users; once you have confidence in that release, you can roll it out to more users, and so on.The % release mechanism marks a percent of users that are eligible to pick up the new release. When their mobile device next checks into the Play Store for updates, it will see an available update for the app and start the update process.
There can be problems with this approach though:
- You have no control over when eligible-for-update users will actually check in; normally it’ll be within 24 hours, assuming they have adequate connectivity, but this may not be true for users in countries where cellular and Wi-Fi data services are slow and expensive per-byte.
- You have no control over whether users will accept your update on their mobile device, which can be a particular issue if the new release requires additional permissions.
If you have a known bad release of your app at version v, the most expedient fix (given the inability to roll back) might be to build your version v-1 code branch into release v+1 and release that, stepping up quickly to 100%. That removes the time pressure to fix the problems detected in code.
Release percentage steps
When you perform a gradual release of a new binary or app, you need to decide in what percentage increments to release your application, and when to trigger the next step in a release. Consider:- The first (canary) step should generate enough traffic for any problems to be clear in your monitoring or logging; normally somewhere between 1% and 10% depending on the size of your user base.
- Each step involves significant manual work and delays the overall release. If you step by 3% per day, it will take you a month to do a complete release.
- Going up by a single large increment (say, 10% to 100%) can reveal dramatic traffic problems that weren’t apparent at much smaller traffic levels: try not to increase your upgraded user base by more than 2x per step if this is a risk.
- If a new version is good, you generally want most of your users to pick it up quickly. If you're doing a rollback, you want to ramp up to 100% much faster than for a new release.
- Traffic patterns are often diurnal — typically, highest during the daytime — so you may need at least 24 hours to see the peak traffic load after a release.
- In the case of mobile apps, you'll also need to allow time for the users to pick up and start using the new release after they’ve been enabled for it.
For internal binary releases where you update your service instances directly, you might instead choose to use steps of 1%, 10% then 100%. The 1% release lets you see if there's any gross error in the new release, e.g., if 90% of responses are errors. The 10% release lets you pick up errors or latency increases that are one order of magnitude smaller, and detect any gross performance differences. The third step is normally a complete release. For performance-sensitive systems — generally, those operating at 75%+ of capacity — consider adding a 50% step to catch more subtle performance regressions. The higher the target reliability of a system, the longer you should let each step “bake” to detect problems.
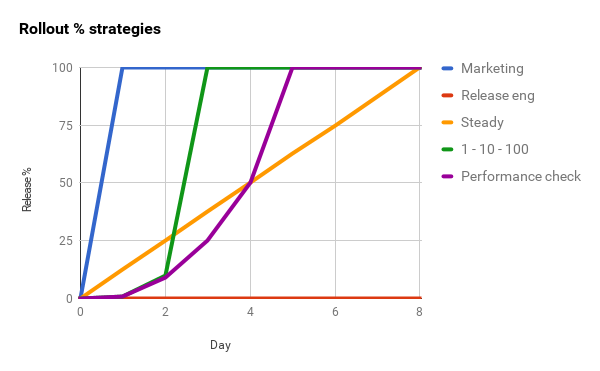
If an ideal marketing launch sequence is 0-100 (everyone gets the new features at once), and the ideal reliability engineer launch sequence is 0-0 (no change means no problems), the “right” launch sequence for an app is inevitably a matter of negotiation. Hopefully the considerations described here give you a principled way to determine a mutually acceptable rollout. The graph below shows you how these various strategies might play out over an 8-day release window.
Summary
In short, we here at Google have developed a software release philosophy that works well for us, for a variety of scenarios:- “Rollback early, rollback often.” Try to move your service towards this philosophy, and you’ll reduce the Mean Time To Recover of your service.
- “Canary your rollouts.” No matter how good your testing and QA, you'll find that your binary releases occasionally have problems with live traffic. An effective canarying strategy and good monitoring can reduce the Mean Time To Detect these problems, and dramatically reduce the number of affected users.



