Cloud Jobs API: machine learning goes to work on job search and discovery
Christian Posse
Group Data Scientist, Google Cloud
Today we introduced Google Cloud Jobs API, our latest machine learning service that provides the necessary lingua franca between the job seeker and employer job postings in order to improve the hiring process. Much like how Google Cloud Translation API translates an arbitrary string into any supported language, Cloud Jobs API understands the nuances of job titles, descriptions, skills and preferences, and matches job seeker preferences with relevant job listings based on sophisticated classifications and relational models.
The mechanics of Cloud Jobs API
At the heart of Cloud Jobs API, there are two main proprietary ontologies that encode knowledge about occupations and skills, as well as relational models between these ontologies.
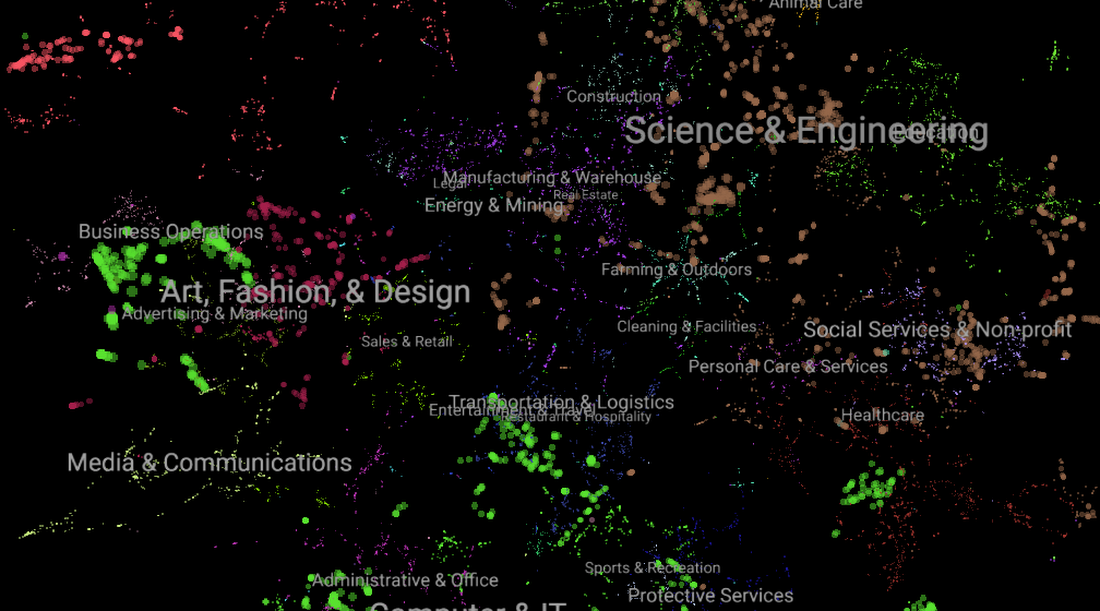
- The occupation ontology, an enhanced evolution of O*NET Standard Occupational Classification, has three layers: The top layer includes approximately 30 broad job categories (e.g., accounting and finance, human resources, restaurant and hospitality). The second layer lists 1,100 occupation families (e.g., emergency registered nurses, foresters, database administrators), and a third layer consists of 250,000 specific occupations (e.g., software engineer, senior software engineer and parking enforcement officer).
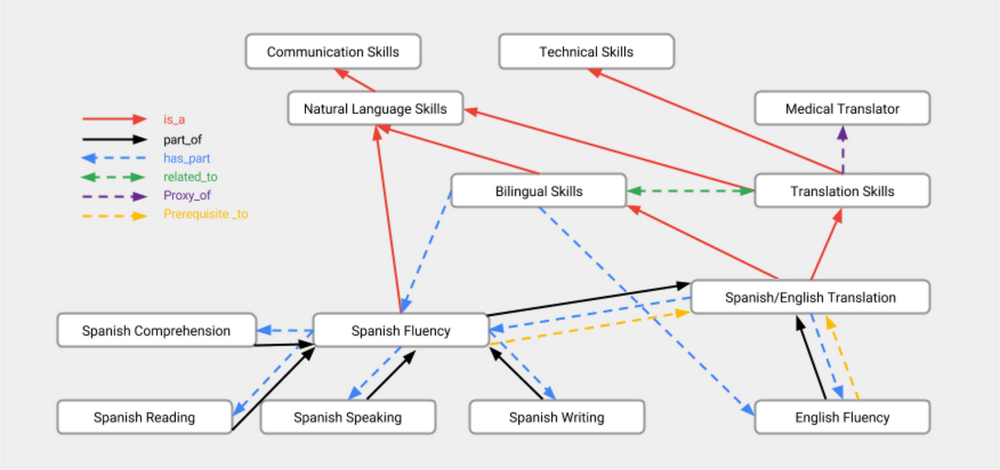
- The skill ontology defines and organizes around 50,000 hard and soft skills with different types of relationships such as is_a, related_to, etc.
- Relational models encode the popularity and specificity of each skill for any occupation family and any specific occupation. For example, the relational models that encode JavaScript, HTML, CSS are skills related to occupations Front-end engineer, UI engineer etc. This allows Cloud Jobs API to identify similar occupation families and specific occupations based on the similarity of their skills distributions.
Galaxy view of occupation ontology
Example of skill ontology branch
Machine learning’s role in Cloud Jobs API
The sheer size of the Cloud Jobs API ontologies makes it impractical to discover relationships using explicit programming models. Enter machine learning, which plays a central role in the uses of these knowledge representations, including:
- Detecting occupation in job seeker queries and mapping them to nodes in the occupation ontology with a confidence score
- Mapping job posting titles to nodes in the occupation ontology with a confidence score
- Detecting skills in job seeker queries and mapping them to nodes in the skills ontology
- Extracting skills in job postings and mapping them to nodes in the skills ontology
- Computing the relational models between occupations and skills
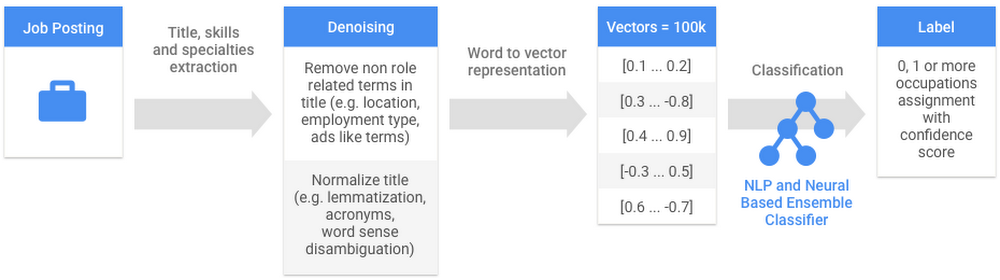
Before this can happen though, Cloud Jobs API must standardize job posting titles.
First, titles are cleaned of any language not directly related to the occupation definition. This includes location, employment type, salary information, company name, advertising jargon (e.g., "needed," "wanted" and "new opening") and administrative jargon (e.g., "reference ID").
Second, Cloud Jobs API computes a high dimensional vectorization (approximately 100,000 dimensions) of the cleaned job titles. The dimensions of the vector representations correspond to terms and expressions gathered from titles and skills extracted from a set of 17M job postings found on hundreds of thousands of company websites.
Third, Cloud Jobs API attempts to precisely encode the vagueness of a given job title: an ensemble classifier comprising natural language based classifiers and several neural nets classifiers attempts to map the title to zero, one or more nodes in any layer of the ontology. For example, the title "retail sales’" maps to the broad category "Sales and Retail," while a "flooring installer" job title encompasses "carpet installer," "floor layer," and "tile and marble setter" occupation families. The ensemble classifier recognizes titles that are not occupations (i.e., it does not map them to the ontology) and provides a confidence score for any mapping.
Job posting title standardization
Cloud Jobs API is now in alpha with a select group of customers, including providers of job boards, career sites and applicant tracking systems. Initial testers include CareerBuilder, Dice and Jibe. Let us know if you would like to learn more about Cloud Jobs API or if you think you might like to try it out. We look forward to hearing from you!


