Want to supercharge your DevOps practice? Research says try SRE
Dave Stanke
Developer Relations Engineer
Reliability matters. When users can’t access your application, if it’s slow to respond, or it behaves unexpectedly, they don’t get the value that you intend to provide. That’s why at Google we like to say that reliability is the most important feature of any system. Its impact can be seen all the way to the bottom line, as downtime comes with steep costs—to revenue, to reputation, and to user loyalty.
From the beginning of the DevOps Research and Assessment (DORA) project, we’ve recognized the importance of delivering a consistent experience to users. We measure this with the Four Key metrics—two metrics that track the velocity of deploying new releases, balanced against two that capture the initial stability of those releases. A team that rates well on all four metrics is not only good at shipping code, they’re shipping code that’s good.
However, these four signals, which focus on the path to a deployment and its immediate effects, are less diagnostic of subsequent success throughout the lifespan of a release. In 2018, DORA began to study the ongoing stability of software delivered as a service (as typified by web applications), which we captured in an additional metric for availability, to explore the impact of technical operations on organizational performance. This year, we expanded our inquiry into this area, starting by renaming availability to reliability. Reliability (sometimes abbreviated as r9y) is a more general term that encompasses dimensions including response latency and content validity, as well as availability.
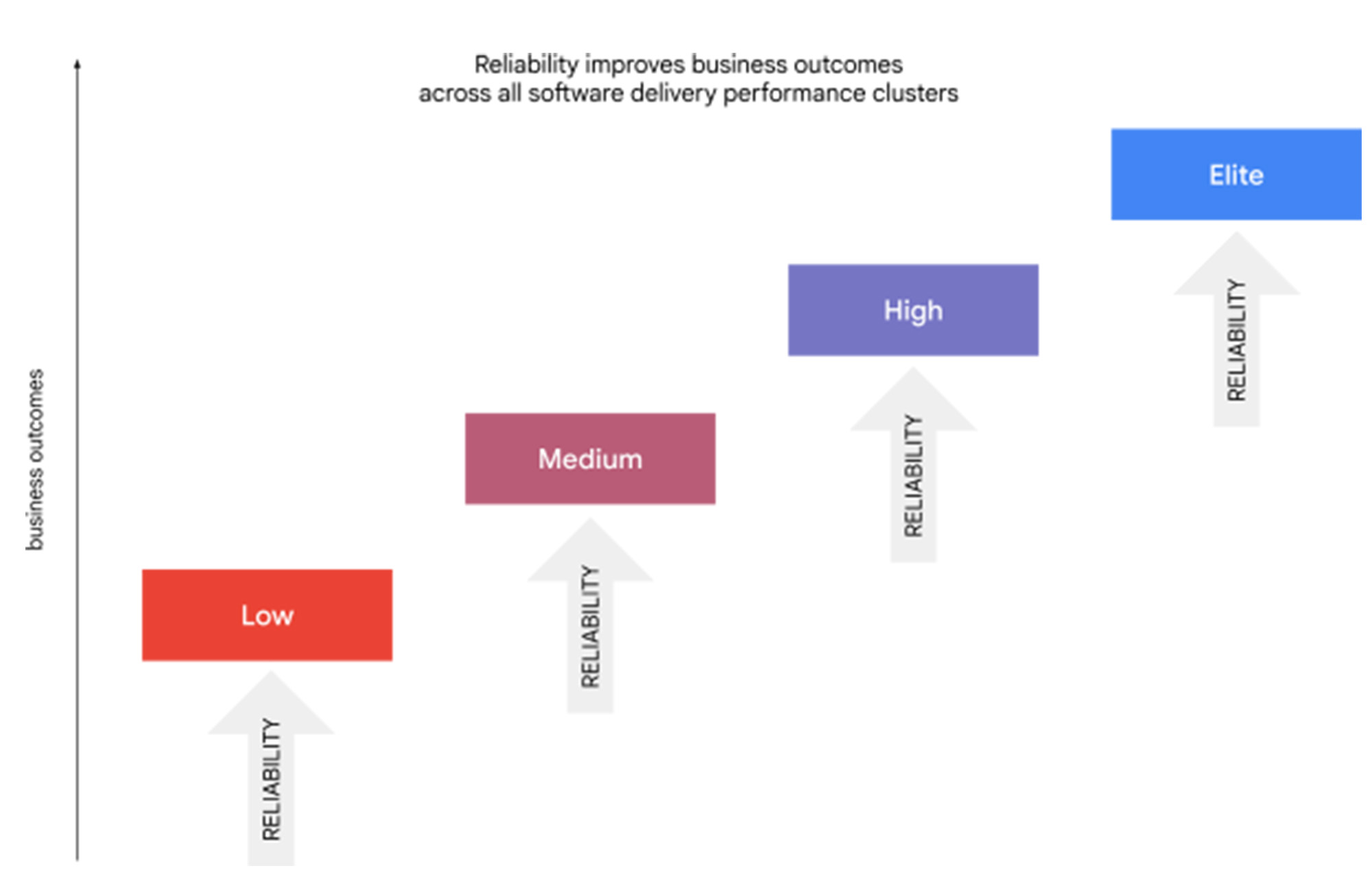
In the 2021 State of DevOps Report’s cluster analysis, teams were segmented into four groups based on the Four Key metrics of software delivery. At first glance, we found that the application of reliability practices is not directly correlated to software delivery performance — teams that score well on delivery metrics may not be the same as those who consistently practice modern operations. However, in combination, software delivery performance and reliability engineering exert a powerful influence on organizational outcomes: elite software delivery teams that also meet their reliability goals are 1.8 times more likely to report better business outcomes.
How Google achieves reliability: SRE
In Google’s early days, we took a traditional approach to technical operations; the bulk of the work involved manual interventions in reaction to discrete problems. However, as our products began to rapidly acquire users across the globe, we realized that this approach wasn’t sustainable. It couldn’t scale to match the increasing size and complexity of our systems, and even attempting to keep up would require an untenable investment in our operations workforce. So, for the past 15+ years, we’ve been practicing and iterating on an approach called Site Reliability Engineering (SRE).
SRE provides a framework for measurement, prioritization, and information sharing to help teams balance between the velocity of feature releases and the predictable behavior of deployed services. It emphasizes the use of automation to reduce risk and to free up engineering capacity for strategic work. This may sound a lot like a description of DevOps; indeed, these disciplines have many shared values. That similarity meant that when, in 2016, Google published the first book on Site Reliability Engineering, it made waves in the DevOps community as practitioners recognized a like-minded movement. It also caused some confusion: some have framed DevOps and SRE as being in conflict or competition with each other.
Our view is that, having arisen from similar challenges and espousing similar objectives, DevOps and SRE can be mutually compatible. We posited that, metaphorically, “class SRE implements DevOps''—SRE provides a way to realize DevOps objectives. Inspired by these communities’ continued growth and ongoing exchange of ideas, we sought to investigate their relationship further. This year, we expanded the scope of data collection to assess the extent of SRE adoption across the industry, and to learn how such modern operational practices interact with DORA’s model of software delivery performance.
Starting from the published literature on SRE, we added the key elements of the framework as items in our survey of practitioners. We took care to avoid as much as possible any jargon, instead preferring plain language to describe how modern operations teams go about their work. Respondents reported on such practices as: defining reliability in terms of user-visible behavior; the use of automation to allow engineers to focus on strategic work; and having well-defined, well-practiced protocols for incident response.
Along the way, we found that using SRE to implement DevOps is much more widely practiced than we thought. SRE, and related disciplines like Facebook’s Production Engineering, have a reputation for being niche disciplines, practiced only by a handful of tech giants. To the contrary, we found that SRE is used in some capacity by a majority of the teams in the DORA survey, with 52% of respondents reporting the use of one or more SRE practices.
SRE is a force multiplier for software delivery excellence
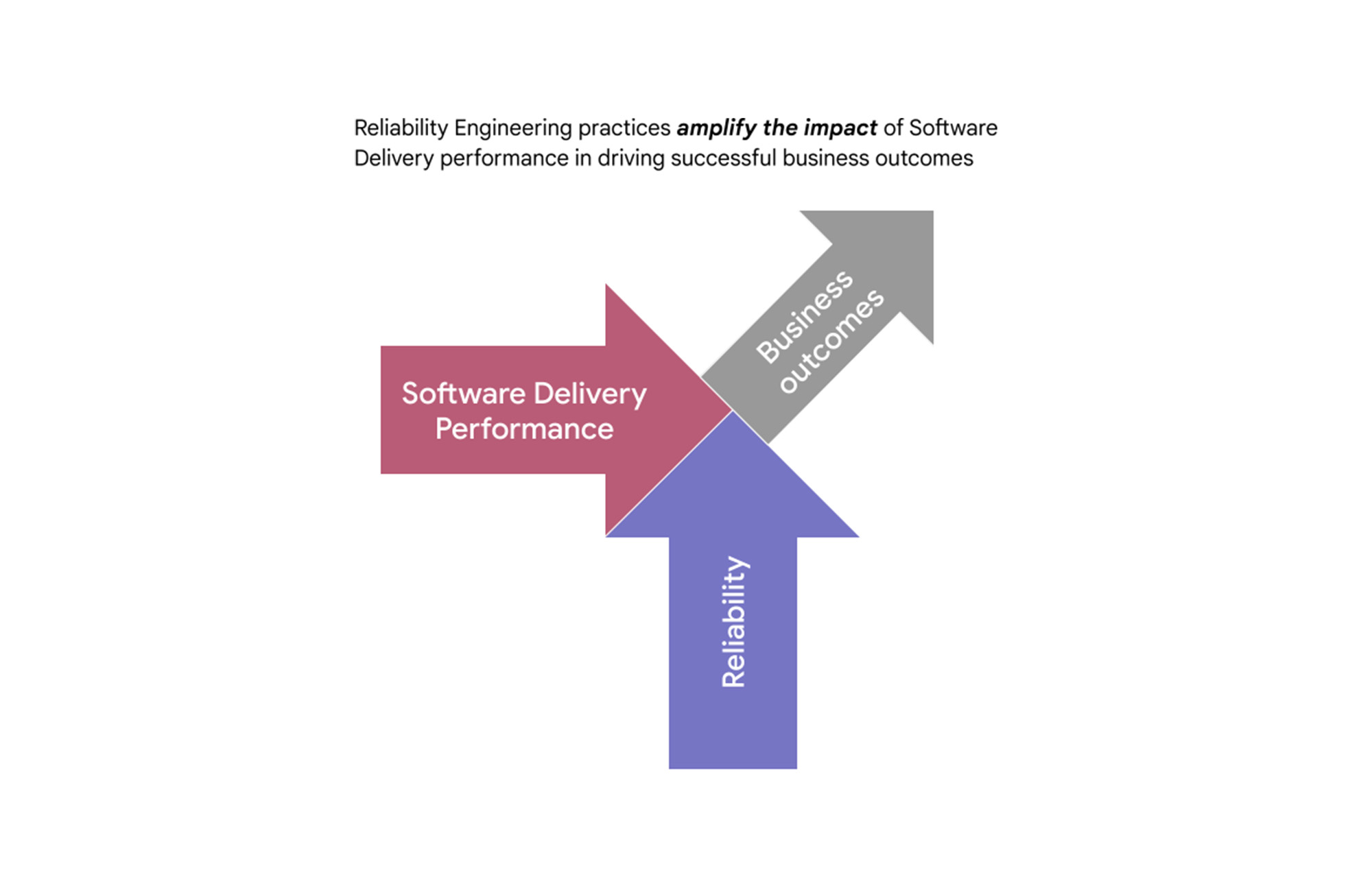
Analyzing the results, we found compelling evidence that SRE is an effective approach to modern operations across the spectrum of organizations. In addition to driving better business outcomes, SRE helps focus efforts—teams that achieve their reliability goals report that they are able to spend more time coding, as they’re less consumed by reacting to incidents. These findings are consistent with the observation that having reliable services can directly impact revenue, as well as offering engineers greater flexibility to use their time to improve their systems, rather than simply repairing them.
But while SRE is widely used and has demonstrable benefits, few respondents indicated that their teams have fully implemented every SRE technique we examined. Increased application of SRE has benefits at all levels: within every cluster of software delivery performance, teams that also meet their reliability goals outperform other members of their cluster in regard to business outcomes.
On the SRE road to DevOps excellence
SRE is more than a toolset; it’s also a cultural mindset about the role of operations staff. SRE is a learning discipline, aimed at understanding information and continuously iterating in response. Accordingly, adopting SRE takes time, and success requires starting small, and applying an iterative approach to SRE itself.
Here are some ways to get started:
Find free books and articles at sre.google
Join a conversation with fellow practitioners, at all different stages of SRE implementation, at bit.ly/reliability-discuss
Speak to your GCP account manager about our professional service offerings
Apply to the DevOps awards to show how your organization is implementing award winning SRE practices along with the DORA principles!


