Reliability and SRE in the 2022 State of DevOps Report

Dave Stanke
Developer Relations Engineer
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialWhen a software change is deployed — after being designed, coded, tested, packaged, and tested some more — a journey comes to an end. At the same time, a new journey begins: your customer’s relationship with your service. It’s here, in the domain of operations, that abstract risks like launch schedule slippage give way to tangible risks like lost revenue, degraded trust, and tarnished reputation. Only when it’s available to users can software contribute to (or threaten!) the success of your organization. And so, throughout the past several years, the DevOps Research and Assessment (DORA) project has incrementally deepened our research into the reliability of services, through and beyond deployment, into ongoing operation.
Reliability is a broadly defined term, which refers to a team’s ability to meet their users’ expectations — for software services, it may encompass aspects of availability, latency, correctness, or other characteristics that influence the consistency and quality of user experience. Google’s practice of Site Reliability Engineering (SRE), which has been embraced and extended by a global community of reliability engineering practitioners, is an approach to operations that prioritizes user-oriented measurement, shared responsibility, and collaborative, blameless learning. Starting with the 2021 Accelerate State of DevOps Report, we began asking survey respondents detailed questions about reliability engineering in their organizations. We continued and expanded our investigation in 2022, and found further evidence that modern reliability engineering is widespread: a majority of respondents report that they employ SRE-style practices. With this extensive body of data to draw from, this year we pushed further into analyses of the impact of reliability and its interaction with other dynamics present in our model of technology’s influence on organizational success.
Reliability matters
When reliability is poor, improvements to software delivery have no effect — or even a negative effect — on organizational outcomes
Reliability is more than beneficial: it’s essential. As in prior studies, we find that software delivery performance (as measured by the “four key metrics” of change lead time, deploy frequency, change failure rate, and failure recovery time) is predictive of organizational performance. However, this year’s analysis revealed a previously unseen nuance: the influence of software delivery on organizational performance is predicated on reliability. When reliability is high, high-performance software delivery predicts better outcomes for the organization. But when reliability is poor, improvements to software delivery have no effect — or even a negative effect — on organizational outcomes. This affirms a long-held belief among reliability engineers: “reliability is the most important feature of any system.” If a service or product doesn’t meet its users’ reliability expectations, it’s counter-productive to rapidly ship flashy new features, because users can’t properly experience them. Software delivery relies on a foundation of reliability to create value.
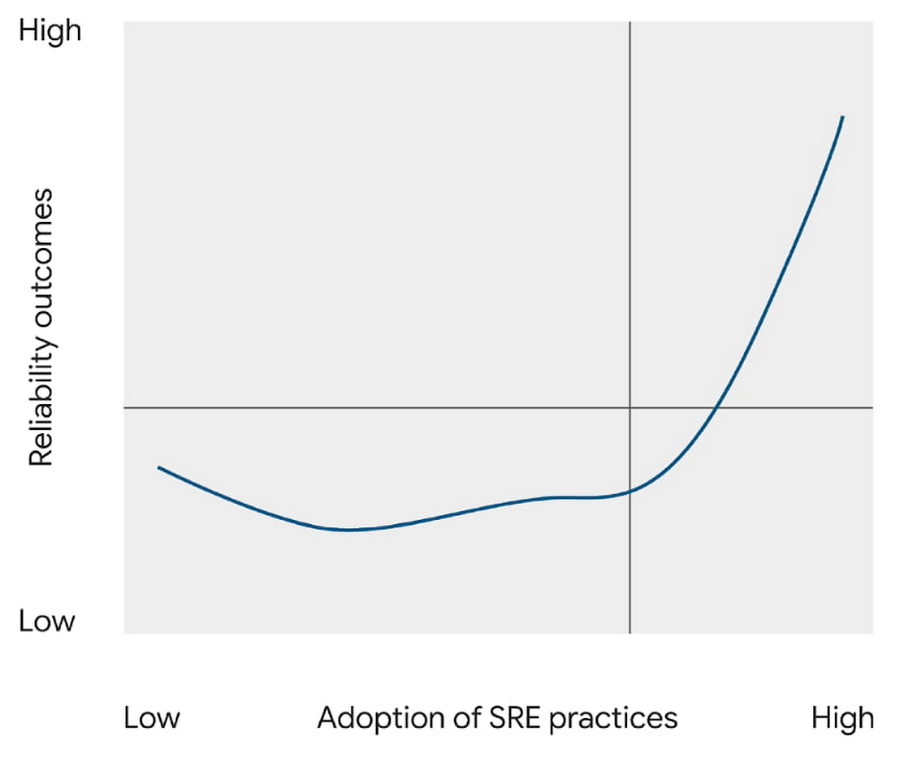
Reliability is a journey
Any experienced leader will tell you that progress is rarely linear: even with a discipline like SRE, widely practiced and with demonstrable benefits, the path to success is unlikely to follow a straight line. DORA describes the “J-Curve” of organizational transformation, a phenomenon in which durable success comes only after setbacks and lessons learned. This year, we compared the depth of teams’ reliability engineering practices to their impact on the services they provide: will an investment in SRE produce greater reliability? The answer is yes, but with a significant caveat: not at first. Comparing reliability outcomes across a range of levels of SRE adoption, the J-Curve is plainly visible. A team which practices SRE only lightly — at the beginning of their SRE journey, perhaps — is likely not only to not benefit, but to regress in terms of the reliability experienced by their users. However, after these practices have more deeply permeated, an inflection point is reached and we see strong reliability benefits from continuing to grow the reliability engineering capability.Knowing that it will likely take time to realize the benefits of adopting SRE, it may be tempting to start the process as soon, and as broadly, as possible. But we offer a note of caution here: organization-wide cultural transformation initiatives typically fail from overreach. We studied this and reported findings in a previous report. And even if you manage to beat the odds and fully adopt SRE across multiple teams simultaneously, the cost may be unacceptable: the setbacks in reliability that you are likely to experience early on, amplified across an entire organization all at once, could have catastrophic consequences. Therefore the SRE principle of gradual change should also be applied to the adoption of SRE itself.
Reliability is about people
Reflecting back on over a decade of SRE practice and theory, the Enterprise Roadmap to SRE underlines the importance of culture, suggesting that Site Reliability Engineering is in fact emergent from culture. Tools and frameworks are important; language is essential. But only a trustful, psychologically safe culture can support the environment of continuous learning which enables SRE to manage today’s complex, dynamic technology environments. DORA’s research in 2022 demonstrates the interplay between culture and reliability: we found that “generative” culture, as defined by the Westrum model, is predictive of higher reliability outcomes. And reliability has benefits not only for a system’s users, but for its makers as well: teams whose services are highly reliable are 1.6 times less likely to suffer from burnout.
Got a story to share about your DevOps journey? Submit it to Google Cloud’s 2022 DevOps Awards by January 31, 2023!


