Cloud Spanner Data Boost: Analyze operational data isolated from transactional workloads
Joe Yong
Product Manager
Ashish Chopra
Cloud-native Databases Product Marketing Lead
As organizations continue to digitally transform, one of the major barriers they face is how to safely run analytical and reporting queries or large batch jobs against live operational databases without risking disruptions. Database owners implement strict controls and limits on data sharing scenarios because these queries can consume a lot of resources — and if unchecked, can disrupt business-critical transactions. We are committed to breaking down the barriers between transactional and analytical systems to deliver the freshest data to your apps and decision making. At Google Cloud Next ’23, we announced the general availability of Cloud Spanner Data Boost — a break-through technology delivering high-performance, workload-isolated, on-demand processing of operational data to support analytics, reporting, ML and more.
Data Boost takes advantage of Google’s disaggregated compute and storage architecture and provides on-demand, isolated compute resources to process analytical queries directly on the storage layer, with virtually no impact to the existing transactional workload. And you retain all the things you love about Cloud Spanner including the virtually infinite scale, global external consistency, and unmatched availability.
Why traditional approaches are ineffective and costly
Traditionally, teams work around data sharing limitations and controls by creating additional replicas or over-provisioning their databases, but this comes with significant costs and management overhead. Other teams build expansive pipelines to deliver data to analytical systems that have long-term financial and operational costs. These pipelines are now on the critical path as other teams depend on reliable delivery of data to do their jobs — and that means the pipelines need to have the same levels of availability and disaster recovery guarantees as the database.
In short, applying strict resource-governance policies within the database shifts the problem to either over-provisioned resources that are infrequently used (i.e., waste money), or picking which user/workload you are willing to terminate in mid-stream to accommodate an incoming query that has higher priority.
We believe there has to be a better way. With Data Boost for Spanner, we aim to pave the way for true democratization of operational data. Data Boost lets you analyze your Spanner data via services such as BigQuery or Spark on Dataproc, export it using Dataflow, or use it in custom jobs and applications — all with virtually no impact to your transactional workloads.
"CERC, a company that is revolutionizing the Brazilian financial market, processes over 100,000 financial transactions per second at low latencies. With Cloud Spanner Data Boost, we can run analytical queries on this data without impacting our transactional workload and at higher performance, which is critical for us. Data Boost has been a game changer, enabling real-time analytics on transactional data at lower cost without the overhead of creating replicas or overprovisioning resources." - André Guergolet, Principal Engineer, CERC
A transformative approach with full workload isolation
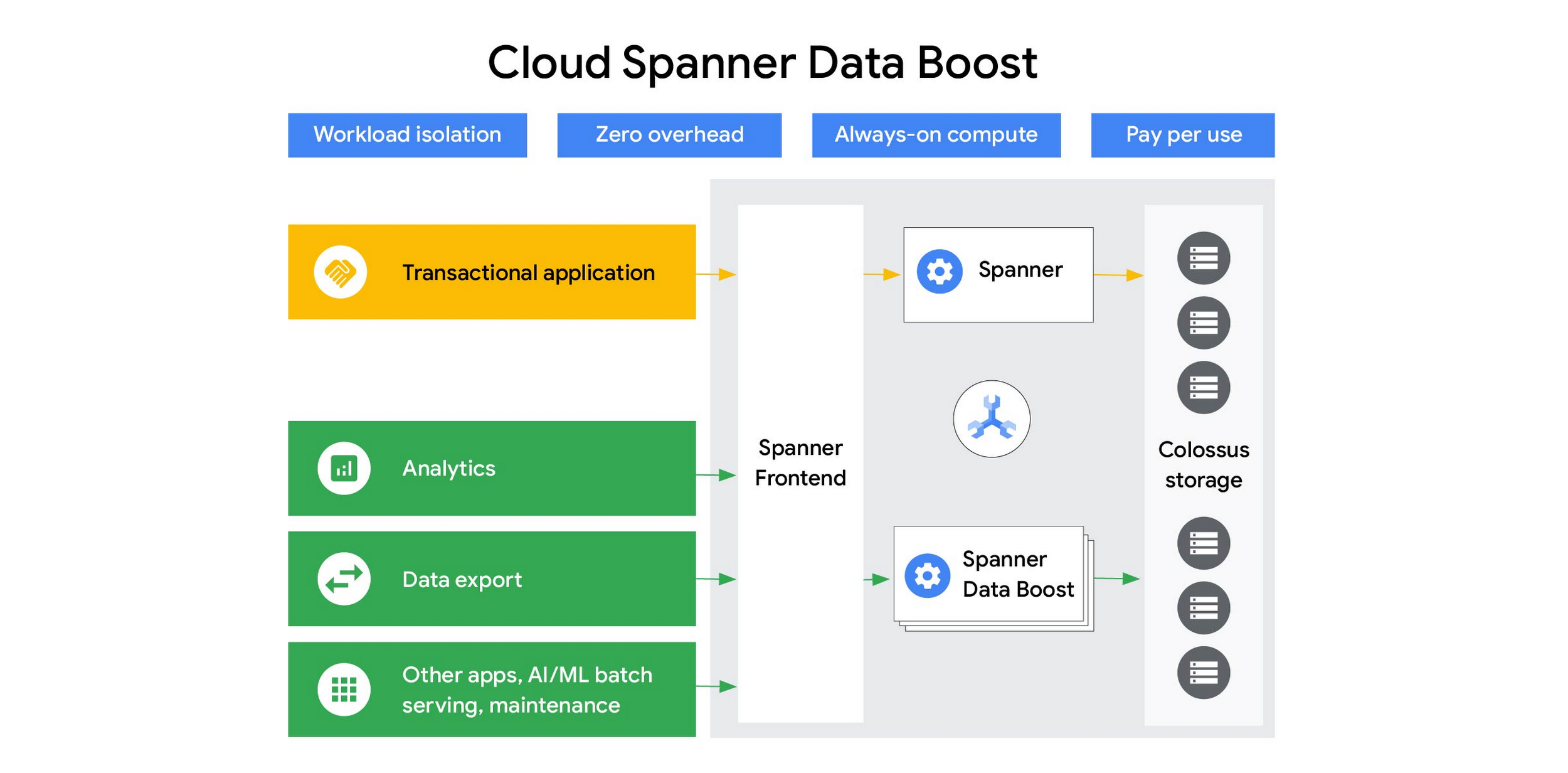
Data Boost lets you run analytical queries, batch processing jobs, or bulk data export operations fully isolated from transactional workloads with a significant performance improvement. Fully managed by Google, Data Boost does not require any capacity planning or management on your part. It’s always-on, ready to receive user queries to directly process against data stored in Spanner's distributed storage system, Colossus instead of replicas so users have access to the freshest data. This on-demand, independent compute resource provides a flexible, scalable and cost-effective architecture to easily handle mixed workloads and enable scalable, worry-free data sharing.
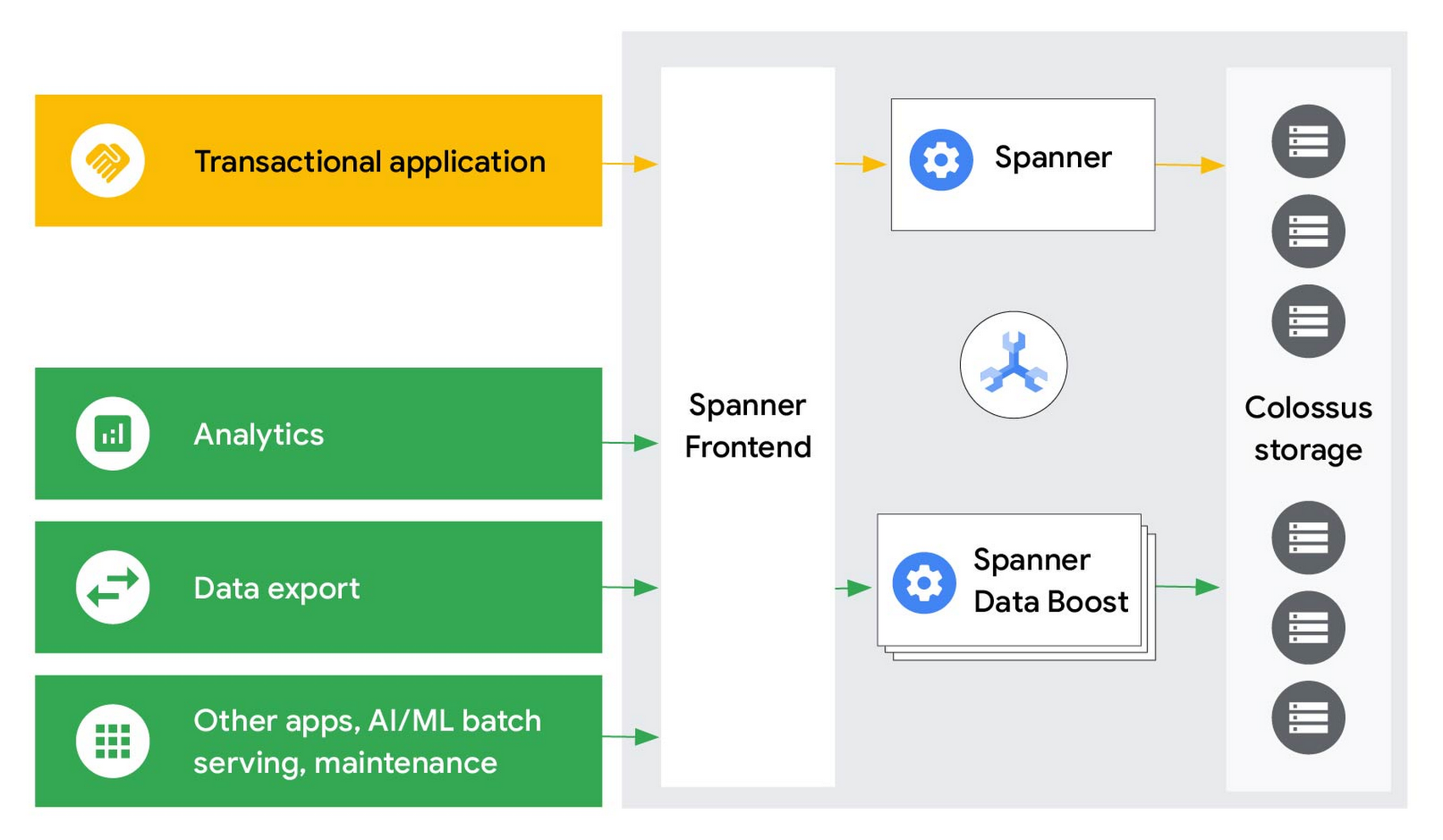
To get started, Spanner users only need to grant permission to use Data Boost to a Spanner IAM user or role, and indicate in the application connection to use Data Boost. No code or schema changes required. Database owners still retain full control of the data and can allow or deny access to specific users via Data Boost. With this model, any user with the appropriate access permissions can process data in Spanner via Data Boost, without being constrained by capacity provisioning, resource isolation, and scale limits. Owners of valuable transactional data can now enable data sharing broadly for workloads like analytics, machine learning model training or even large data exports for audits, without worrying about negative impact to their transactional workload.
"We’re excited to see capabilities like Data Boost launch that aim to remove operational overhead when deriving insights from production data. When performing analytical queries with traditional data stores, the safe route has been to push production data to a separate data store and only then perform analytical queries. This was to avoid disrupting mission-critical reads and writes, but that approach has meant more infrastructure to manage and therefore more overhead. Data Boost looks to be a step in the direction of changing that. Connecting BigQuery or other third-party tools to query live production Cloud Spanner databases without impacting the reads and writes of other services sounds powerful. It has the potential to accelerate teams and organizations.” - Yatin Chopra, senior manager, AI & Data, Deloitte Consulting LLP
Do more for less with automated optimization
In addition to being able to mix workloads without impacting your latency-sensitive transactional workloads, this independent, scale-out data processing capability can deliver significant performance improvements. Data Boost can make automatic, independent optimization decisions when deciding how to run a query. For example, it can decide to run at a much higher degree of parallelism without risk of resource contention with existing workloads.
Only pay for actual usage
What makes this technology even more attractive is that it offers a pay-per-use model. Usage is measured by Serverless Processing Units (SPUs), which include the CPU, memory and data access needed to process the query. Users only pay for actual SPUs used by their queries — no ramp-up or cool-down costs. This can reduce overall costs, not to mention freeing users from the burden of capacity planning and management. Administrators can also audit and limit usage by user or specific queries to avoid cost overruns.
Owners of valuable transactional data can now enable broad data sharing for the entire organization so users can access what they need, when they need it, without risk of disruption to the transactional workload. Since users access the data directly in the source Spanner database, all existing security and audit controls are in effect including fine grained access controls, ensuring that users can only access data to which they have been granted permissions. This helps reduce data sprawl, which in turn reduces the load on data governance since there are fewer copies to govern.
Zero to hero in just one minute
One of our key design considerations for Data Boost was it should require the least amount of time and effort for customers to get started and exercise its power. We wanted customers to reap the benefits purely by configuration, not code — and we think we succeeded. Users do not need to modify their database schema or application code; they only need to grant the required IAM permission and add a configuration parameter in their existing connection string or object. For instance, to enable Data Boost for a federated query from BigQuery, or a data export job from Cloud Spanner console, users literally only need to check a box.
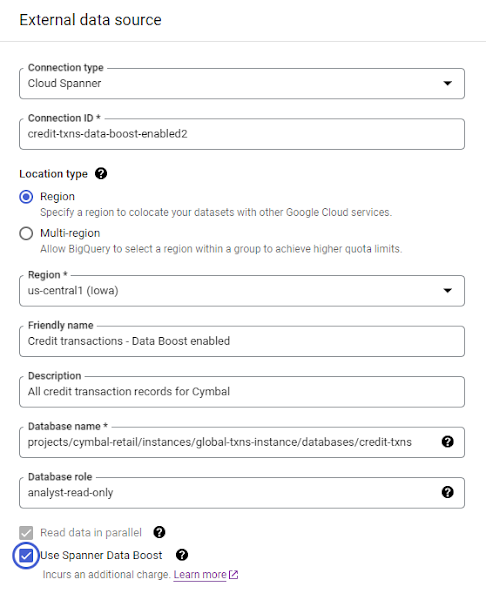
Users can also enable Data Boost in a Spark job or their custom, in-house developed application just by adding a connection parameter to use Data Boost.

Empower everybody
While the examples above are primarily with other Google Cloud services, Data Boost is open and accessible to all. It is supported on all Spanner clients so anybody can provide workload isolation for their applications just by adding the “enableDataBoost” parameter and setting its value to “true”. In fact, several ISVs have already enabled Data Boost in their applications, including (but not limited to) cdata, Deepnote, Denodo, Integrate.io, and Nexla (these fast movers deserve special mention given they got the engineering work done faster than we could write this blog!):

“Our Integrate.io customers need solutions that insure exceptional interoperability within their data ecosystem. Google Cloud Spanner Data Boost enables teams to execute analytics queries and data exports without any friction or impact to their existing workloads on their Spanner instances.” - Mark Smallcombe, Chief Technology Officer, Integrate.io
Get started with Data Boost
Running batch or analytic workloads against your transactional database or enabling data sharing broadly are now, truly, worry-free. Analysts and other users can get access to the freshest data they need via self-service without impacting your latency-sensitive transactional workloads, and while enforcing all existing security controls. Best part is, you can probably set everything up over coffee and potentially lower overall operational costs before your second cup!
Learn more about how to enable Data Boost in your environment by following the guidance in the documentation. Or better yet, just hop onto the Google Cloud console and try it for yourself. We think you’ll be pleasantly surprised with how quickly you’ll be up and running.
