Boost the power of your transactional data with Cloud Spanner change streams
Mark Donsky
Cloud Spanner product manager
Eike Falkenberg
Engineering Manager, Google
Data is one of the most valuable assets in today’s digital economy. One way to unlock the value of your data is to give it life after it’s first collected. A transactional database, like Cloud Spanner, captures incremental changes to your data in real time, at scale, so you can leverage it in more powerful ways. Cloud Spanner is our fully managed relational database that offers near unlimited scale, strong consistency, and industry-leading high availability of up to 99.999%.
The traditional way for downstream systems to use incremental data that’s been captured in a transactional database is through change data capture (CDC), which allows you to trigger behavior based on changes to your database, such as a deleted account or an updated inventory count.
Today, we are announcing Spanner change streams, coming soon, that lets you capture change data from Spanner databases and easily integrate it with other systems to unlock new value.
Change streams for Spanner goes above and beyond the traditional CDC capabilities of tracking inserts, updates, and deletes. Change streams are highly flexible and configurable, letting you track changes on exact tables and columns or across an entire database. You can replicate changes from Spanner to BigQuery for real-time analytics, trigger downstream application behavior using Pub/Sub, and store changes in Google Cloud Storage (GCS) for compliance. This ensures you have the freshest data to optimize business outcomes.
Change streams provides a wide range of options to integrate change data with other Google Cloud services and partner applications through turnkey connectors, including custom Dataflow processing pipelines or the change streams read API.
Spanner consistently processes over 1.2 billion requests per second. Since change streams are built right into Spanner, you not only get industry-leading availability and global scale—you also don’t have to spin up any additional resources. The same IAM permissions that already protect your Spanner databases can be used to access change streams queries.Change stream queries are protected by spanner.databases.select, and change stream DDL operations are protected by spanner.databases.updateDdl.
Change streams in action
In this section, we’ll look at how to set up a change stream that sends change data from Spanner to an analytic data warehouse in BigQuery.
Creating a change stream
As discussed above, a change stream tracks changes on an entire database, a set of tables, or a set of columns in a database. Each change stream can have a retention period of anywhere from one day to seven days, and you can set up multiple change streams to track exactly what you need for your specific business objectives.
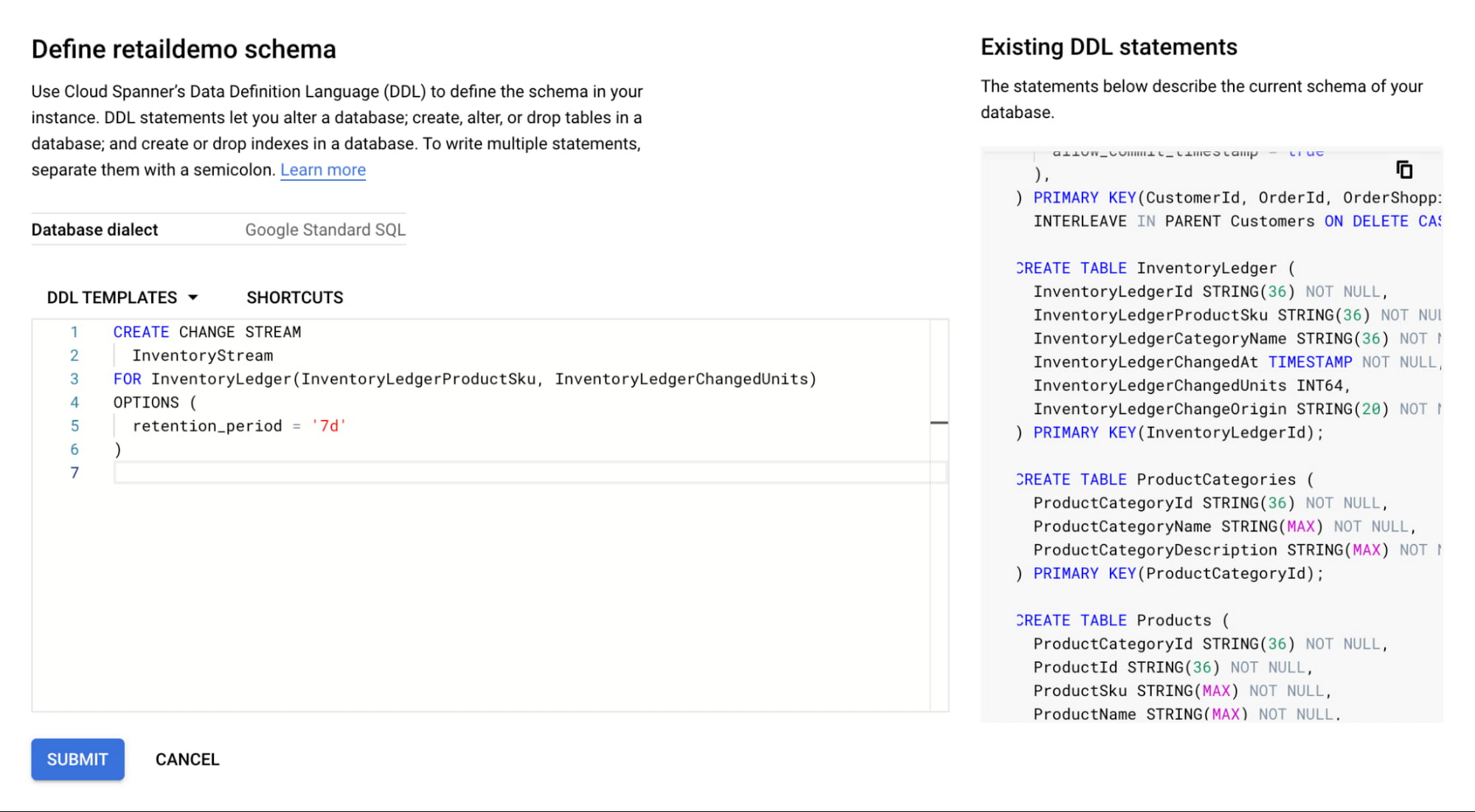
First, we’ll create a change stream on a table called InventoryLedger. This table tracks inventory changes on two columns: InventoryLedgerProductSku and InventoryLedgerChangedUnits with a 7-day retention period.
Change records
Each change record contains a wealth of information, including primary key, the commit timestamp, transaction ID, and of course, the old and new values of the changed data, wherever applicable. This makes it easy to process change records as an entire transaction, in sequence based on their commit timestamp, or individually as they arrive, depending on your business needs.
Back to the inventory example, now that we’ve created a change stream on the InventoryLedger table, all inserts, updates, and deletes on this table will be published to the InventoryStream change stream. These changes are strongly consistent with the commits on the InventoryLedger table: When a transaction commit succeeds, the relevant changes will automatically persist in the change stream. You never have to worry about missing a change record.
Processing a change stream
There are numerous ways that you can process change streams depending on the use case:
Analytics: You can send the change records to BigQuery, either as a set of change logs or by updating the tables.
Event triggering: You can send change logs to Pub/Sub for further processing by downstream systems.
Compliance: You can retain the change log to Google Cloud Storage for archiving purposes.
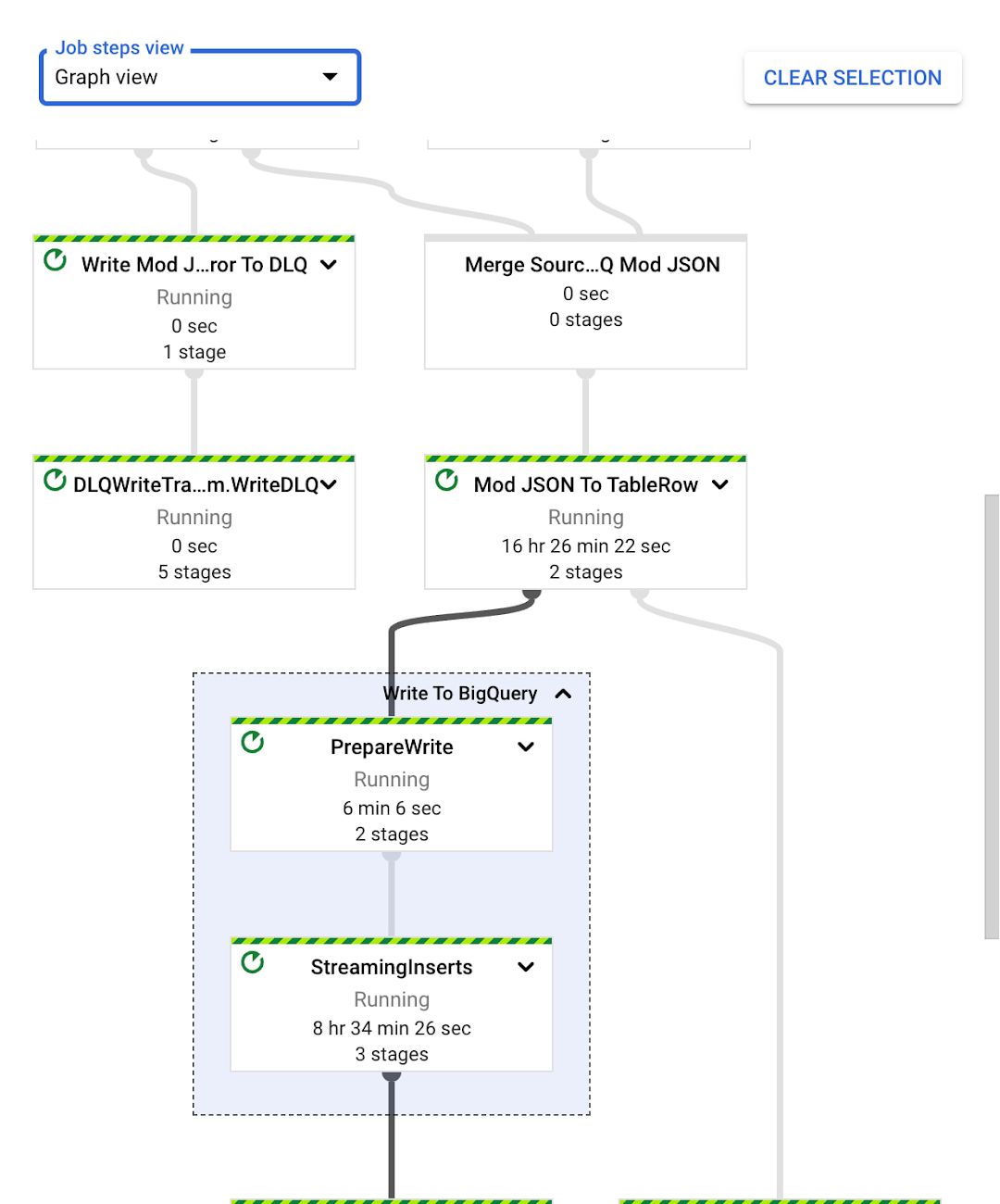
The easiest way to process change stream data is to use our Spanner connector for Dataflow, where you can take advantage of Dataflow’s built-in pipelines to BigQuery, Pub/Sub, and Google Cloud Storage. The diagram below shows a Dataflow pipeline that processes this change stream and imports change data directly into BigQuery.
Alternatively, you can build a custom Dataflow pipeline to process change data with Apache Beam. In this case, we provide a Dataflow connector that outputs change data as an Apache Beam PCollection of DataChangeRecord objects.
For even more flexibility, you can use the underlying change streams query API. The query API is a powerful interface that lets you read directly from a change stream to implement your own connector and stream changes to the pipeline of your choice. On the query API side, a change stream is divided into multiple partitions, which can be used to query a change stream in parallel for higher throughput. Spanner dynamically creates these partitions based on load and size. Partitions are associated with a Spanner database split, allowing change streams to scale as effortlessly as the rest of Spanner.
Get started with change streams
With change streams, your Spanner data follows you wherever you need it, whether that’s for analytics with BigQuery, for triggering events in downstream applications, or for compliance and archiving. Change streams are highly flexible and configurable —allowing you to capture change data for the exact data you care about, and for the exact period of time that matters for your business. And because change streams are built into Spanner, there’s no software to install, and you get external consistency, high scale, and up to 99.999% availability.
There’s no extra charge for using change streams, and you’ll pay only for extra compute and storage of the change data at the regular Spanner rates.
To get started with Spanner, create an instance, or try it out with a Spanner Qwiklab.
We’re excited to see how Spanner change streams will help you unlock more value out of your data!