Disaster recovery simplified with Cloud Spanner CPU optimized backups
Gideon Glass
Software Engineer
For business critical applications, a disaster recovery and data protection plan is essential. This plan should protect against both natural disasters (fires, floods, power outages, etc) as well as human caused incidents, like shipping a bug that causes bad data to be committed.
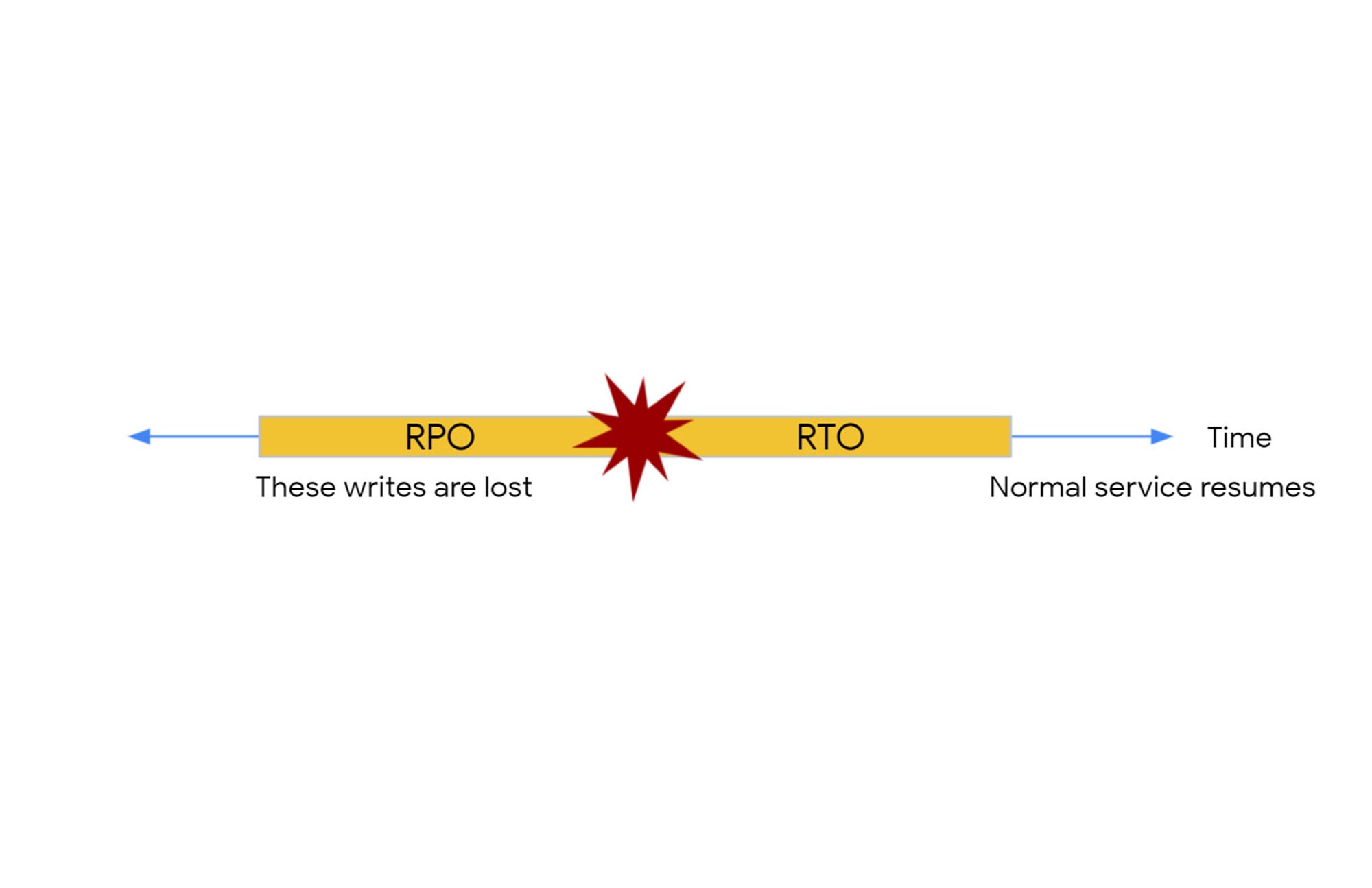
As part of the plan, application owners should consider both RPO (Recovery Point Objective), which relates to the age of the data one is prepared to recover from; and RTO (Recovery Time Objective), which relates to the amount of time one is prepared to take while bringing an application back online following an incident.
Cloud Spanner is a fully managed relational database with unlimited scale, strong consistency, and up to 99.999% availability. Cloud Spanner provides transparent, synchronous replication across zones with regional configurations, and across regions with multi-region configurations. This architecture inherently protects against some causes of incidents that traditional disaster recovery solutions must address – natural disasters and individual machine failures.
Regardless of the high availability that Cloud Spanner offers, application owners still need data protection -- one can never rule out the possibility of a user error or application bug which could cause incorrect values to be stored into the database. To address these needs, Cloud Spanner offers backup/restore and point-in-time recovery.
Cloud Spanner backups are transactionally consistent: when a backup is created, the backup captures the exact database contents as of a backup timestamp -- a microsecond granularity transaction commit timestamp. Cloud Spanner ensures that all data associated with transactions that are committed up to and including the backup timestamp are included in the backup, and that all partial updates associated with uncommitted transactions are excluded. Point-in-time recovery allows recovering from a user-chosen restore timestamp with the same semantics as a backup – all transactions committed up to and including the restore timestamp are present in the restored database, and nothing else.
Suppose a user has a 10TB database that is powering a business-critical application. The user regularly takes backups as part of their disaster recovery plan. In many systems, backing up a large database can take many hours and can increase the CPU load on the database. There is a concern that increased CPU load from backups could adversely impact production traffic. Cloud Spanner has solved this problem with CPU Optimized Backups. With this feature, Cloud Spanner has separated the CPU resources used for customer database instances from the CPU resources used for backup creation. It is enabled for all backups in Cloud Spanner.
To create a backup for a database, Cloud Spanner starts up a batch job to read the database contents and write out a copy of the backup. This is done in each GCP zone that has a full copy of the database – all read-write and all read-only zones. Each zone's copy of the backup is independently written and stays only within that zone. This enables high availability backups and fast restores without cross-zone network traffic.
Compute and storage have always been separated in Spanner. However, before the advent of CPU Optimized Backups, each backup job obtained the data by requesting it from Cloud Spanner servers in the customer instance; the logic in the servers plays a critical role in determining the correct data to include in the backup. This diagram depicts the flow of data without CPU optimized backups:
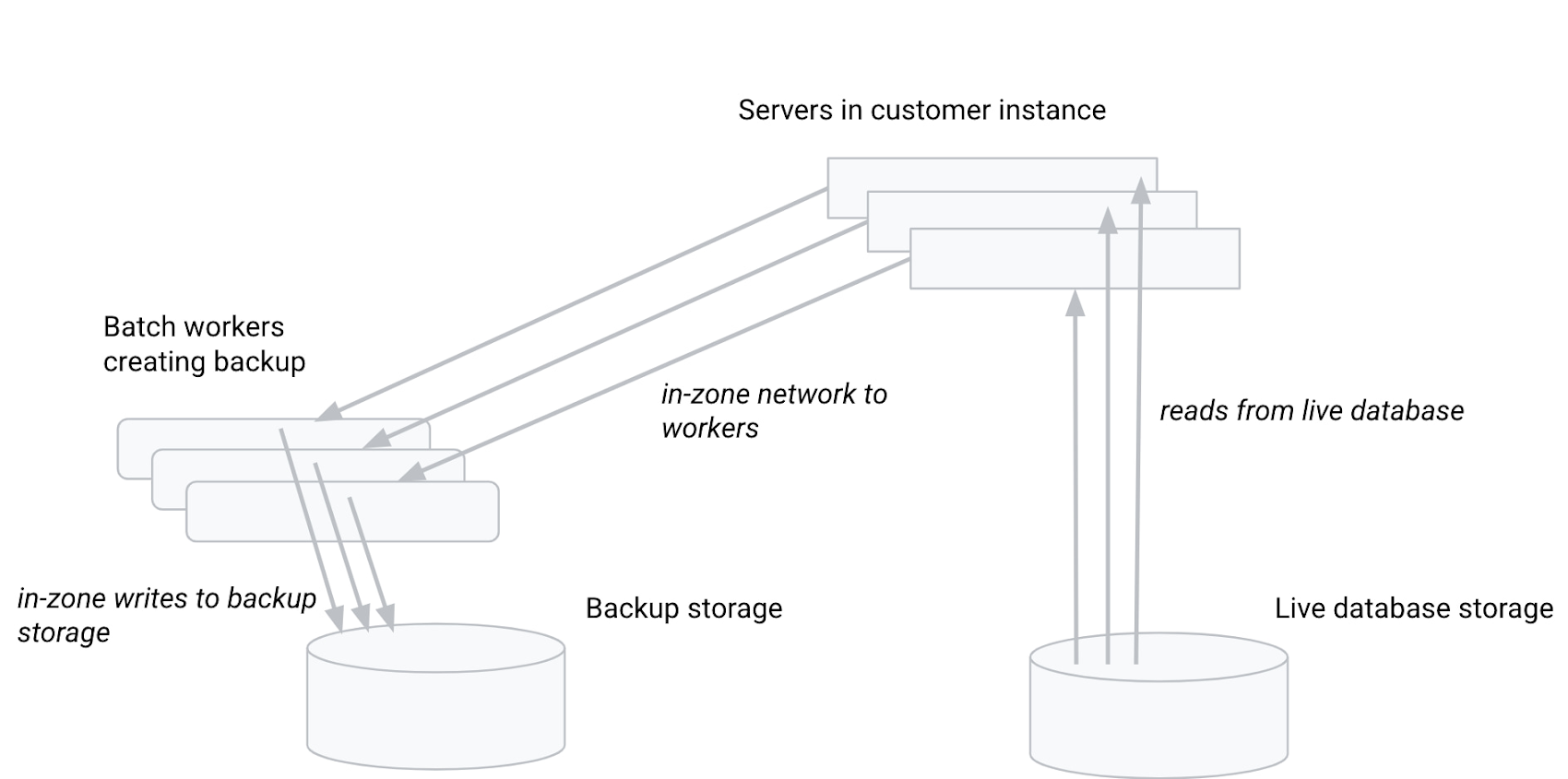
In the above scheme, the storage systems and the backup batch jobs are all highly scalable. The limiting factor is the throughput of copying the data through the customer instance servers. The logic in the Cloud Spanner servers does play an important role here: separating out older data which must be captured in the backup from newer data that must be excluded. Examples of newer data are partial updates from aborted transactions, and updates from transactions that committed only after the backup timestamp.
With CPU optimized backups, we run the formerly server-side logic as part of backup worker batch jobs. This allows us to perform the detailed processing of separating out data that must be captured in the backup vs data that must be excluded -- but without having the customer instance servers do the work. Instead, the work is done entirely inside the backup worker batch job:
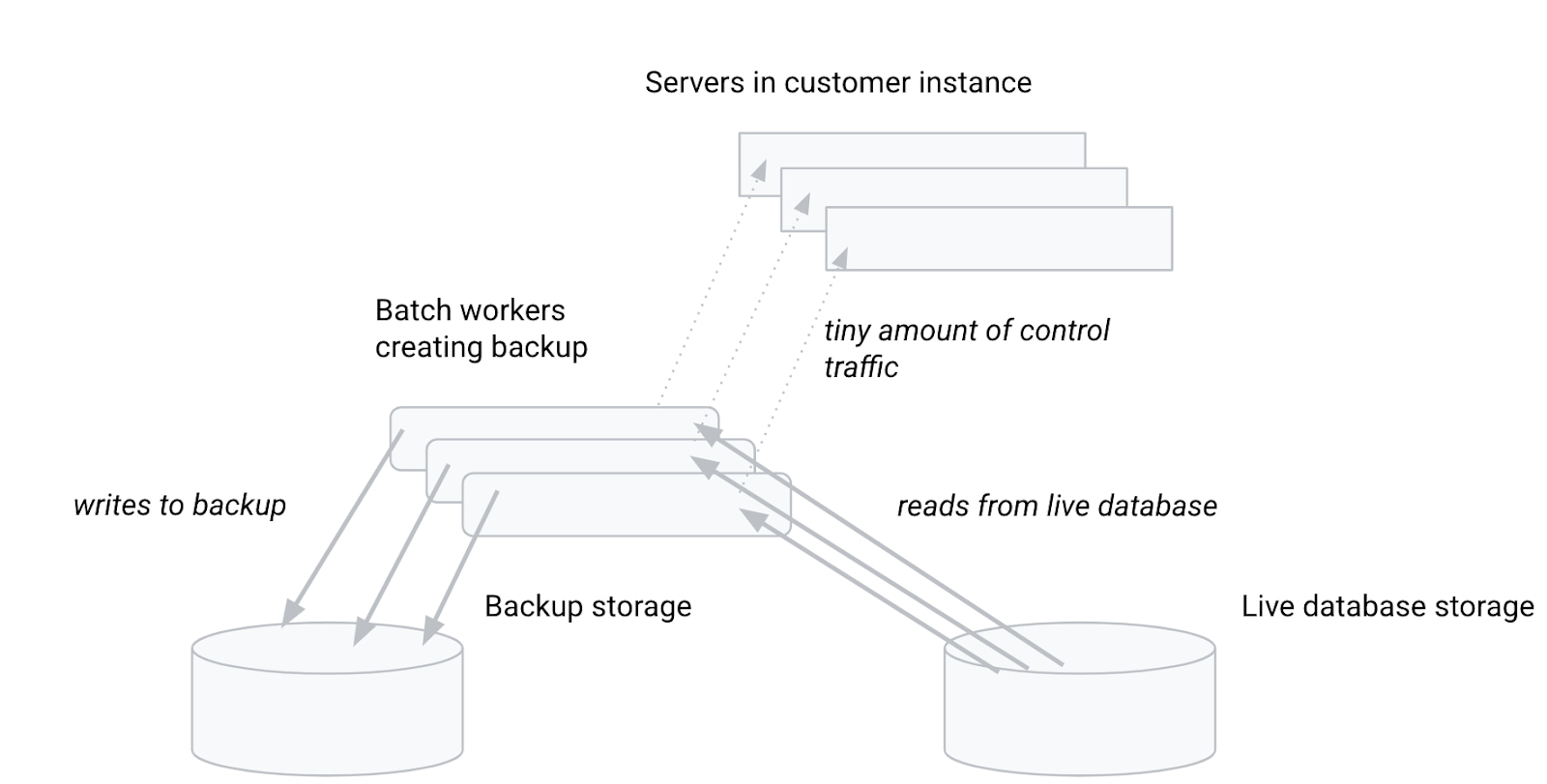
This has several important advantages for customers:
Customers no longer need to provision extra compute capacity (as measured in nodes or processing units) to leave CPU headroom available for backups.
CPU load on the customer instance due to backups is reduced nearly to zero – which means no performance impact to production workloads while backups run.
The batch job creating the backup can be scaled independently of the number of servers in the customer instance. The underlying filesystem is highly distributed and allows for essentially unlimited read bandwidth -- in practice, limited by the number of client workers in the batch job. With CPU optimized backups, we decouple the size of the backup jobs from the size of the customer instances, and allow backups for large databases to burst up to very large sizes (potentially, thousands of machines).
Backup performance depends on a variety of factors, including some database-specific factors like schema details, so we don't make very specific performance predictions. That said, we've found that most databases' backups including databases in the tens to hundreds of terabytes typically complete within one to four hours.
CPU Optimized Backups continue the tradition of technical innovation in Cloud Spanner data protection and disaster recovery. Existing restore functionality leverages per-zone backups to enable fast restores with no cross-zone data copying. Point-in-time-recovery enables flexible restores either using stale reads, backups at past timestamps, or export at past timestamps. We continue to innovate and improve Cloud Spanner capabilities to serve customers better. Cloud Spanner is incurring extra costs with the implementation of CPU Optimized Backups, but in the interest of providing customers a better experience at the same price Google is happy to shoulder the cost. There is no change in backups pricing with CPU Optimized Backups.
For more information on Cloud Spanner, watch this youtube video or visit the Cloud Spanner website.