Resolve and optimize many-to-many relationships in Spanner
Szabolcs Rozsnyai
Senior Staff Solutions Architect
Karthi Thyagarajan
Senior Staff Solutions Architect
Software designers often need to model “real-world” entities such as organizations, managers, employees, etc. As part of this modeling, many-to-many relationships pop up often. They’re used to represent relationships where entities on both sides can have multiple related instances, e.g. a manager having multiple direct reports and an individual contributor with multiple dotted line managers. The way this is reflected in a database is with a record in one database table is associated with multiple records in another table.
In the context of relational models, achieving a many-to-many relationship involves using an intermediate bridge table, storing pairs of primary key values from both sides along with the option to add additional information on the relationship. This model facilitates the principles of ensuring integrity and mitigating redundancy.
While modeling many-to-many relationships is a universally applicable concept in relational databases, there are certain Spanner specific optimizations and trade-offs that should be taken into account to efficiently resolve such relationships at scale.
These options mainly depend on the most used access pattern which we will explore in this article.
Example schema
Let's take the following example where a user can participate in various groups, and the other side of the coin, where a group can contain multiple users. The process of normalization would lead to the creation of an intermediary table named Membership to resolve this relationship. In this particular example the attribute enrolled stores additional information on the relationship.

Now let's have a look at different query patterns, their effect on performance, and common Spanner performance optimizations.how Spanner features can be used to optimize queries.
Balanced access
There are basically two paths of query patterns on n:m relationships. For the given example they would be:
- Which groups has user X joined: Get groups that a specific user or set of users is associated with.
- Which users have joined group Y: Get users for a specific group or a set of groups they belong to.
Often the dominant query patterns are not known upfront and in such cases a balanced optimization needs to be chosen to cater for both.
Query pattern 1: Which groups has user X joined?
This query path needs to resolve for a specific user the groups that it is associated with. Records in a Spanner table are organized lexicographically by the primary key (PK) and as such are automatically indexed for efficient lookups. This particular query will therefore perform reasonably fast to resolve the relationship because the primary key of the membership table is a composite key of which the prefix is the user_id.
Query pattern 2: Which users have joined group Y?
The reverse query i.e. finding all users that belong to a specific group will perform magnitudes slower (depending on data shape).
This is due to the fact that a full table scan will need to be executed on the membership table to resolve the join on the constrained group_id.
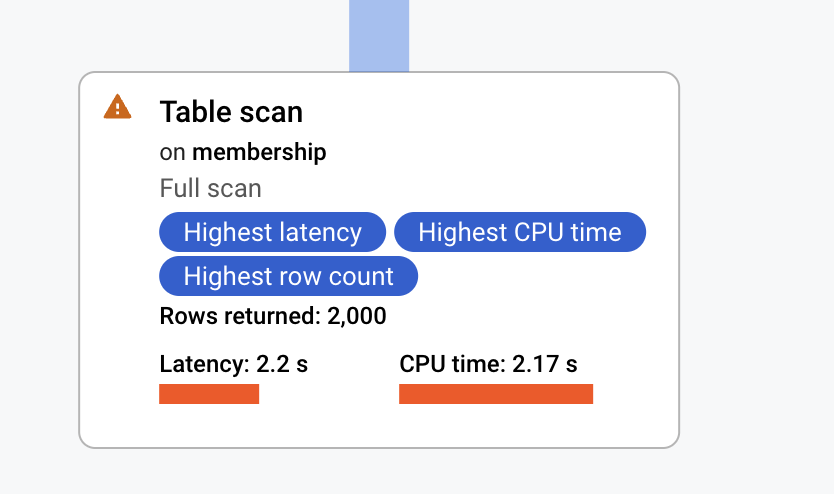
In order to bring the query up to the same latency range as Query 1 an index needs to be created.
This will result in an efficient index scan:
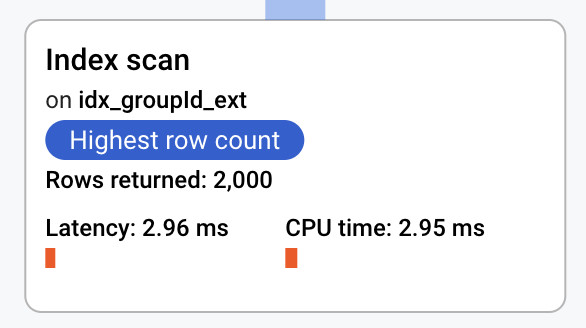
By adding an index we have improved the query performance, but this will come at the cost of additional writes (to the index) and as such additional latency.
However, the query will still have room for optimization. The membership table has additional data maintained about the relationship (enrolled timestamp) which is queried through the SELECT clause. As a result the plan further up the chain will result in a distributed cross apply which is essentially an additional roundtrip from the index table to retrieve non-PK attributes.
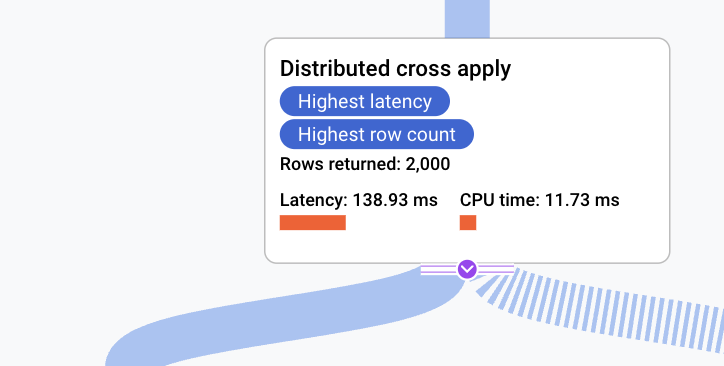
In order to optimize this further it can be a good practice to store the attribute (enrolled) into the index using Spanner’s STORING clause.
It is noteworthy that this will come at the expense of additional storage and slightly added write latency with the upside speeding up queries.
Foreign key relationships
A convenient choice is to utilize Spanner’s foreign key relationships which will automatically create backing indexes for relationships.
One index is created for the referencing columns, and a second for the referenced columns. In this case the foreign key points to a primary key of the referenced table and therefore the second index on the referenced table is not needed.
The backing indexes are not user-created indexes and as such are only visible in the database’s information schema (INFORMATION_SCHEMA.INDEXES) with a SPANNER_IS_MANAGED value of true.
Downside of relying on foreign keys for these particular query examples is that you can not specify a STORING clause to co-store the enrolled attribute to the backing index and speed up query processing.
Boosting latency with interleaving for high scale
Access patterns of n:m relationships are often uni-directional. For instance, it could be that most of the time the groups that a user belongs to are queried. For this scenario it would make sense to interleave the Membership table into the User table:
This optimization pattern compared to the above methods will excel at scale with relations that cover a large amount of records.
When the requirements is to serve bi-directional low latency queries in high scale scenarios, the solution is to denormalize the schema and create two membership tables serving both query directions in an interleaved fashion:
Downside is that the application needs to duplicate data to two intermediate tables (membership_user, membership_group) to resolve the relationships. The resulting tables are not normalized in terms of a sound relational model (i.e. 3NF) with all its downsides and as a consequence will also add to the write latency budgets.
Conclusion
In this article we have discussed Spanner specific optimizations and trade-offs that should be taken into making schema design decisions when modeling many-to-many relationships. The choice of optimization strategy for this type of relationships in Spanner should be based on the specific access patterns and performance requirements of your application, taking into account the trade-offs associated with each approach. By carefully designing the database schema and leveraging Spanner's features, you can strike a balance between efficiency and query performance in your many-to-many relationships.
To put the guidance in this post into practice, we recommend checking out this Quickstart, where you’ll find information on how to create Spanner instances, databases and tables.

