Optimizing terabyte-scale PostgreSQL migrations to Cloud SQL with Searce

Chinmay Joshi
Technical Program Manager, Searce
Karan Kaushik
Cloud Architect, Searce
Google Cloud allows you to move your PostgreSQL databases to Cloud SQL with Database Migration Service (DMS). DMS gives you the ability to replicate data continuously to the destination database, while the source is live in production, enabling you to migrate with minimum downtime.
However, terabyte-scale migrations can be complex. For instance, if your PostgreSQL database has Large Objects, then you will require some downtime to migrate them manually as that is a limitation of DMS. There are few more such limitations - check out known limitations of DMS. If not handled carefully, these steps can extend the downtime during cutover, lead to performance impact on the source instance, or even delay the project delivery date. All this may mean significant business impact.
Searce is a technology consulting company, specializing in modernizing application and database infrastructure by leveraging cloud, data and AI. We empower our clients to accelerate towards the future of their business. In our journey, we have helped dozens of clients migrate to Cloud SQL, and have found terabyte-scale migrations to be the toughest for the reasons mentioned earlier.
This blog centers around our work in supporting an enterprise client whose objective was to migrate dozens of terabyte scale, mission-critical PostgreSQL databases to Cloud SQL with minimum downtime. Their largest database was 20TB in size and all the databases had tables with large objects and some tables did not have primary keys. Note that DMS had a limitation of not supporting migration of tables without a primary key during the time of this project. In June 2022, DMS released an enhancement to support the migration of tables without a primary key.
In this blog, we share with you our learnings about how we simplified and optimized this migration, so that you can incorporate our best practices into your own migrations. We explore mechanisms to reduce the downtime required for operations not handled by DMS by ~98% with the use of automation scripts. We also explore database flags in PostgreSQL to optimize DMS performance and minimize the overall migration time by ~15%.
Optimize DMS performance with database flags
Once the customer made the decision to migrate PostgreSQL databases to Google Cloud SQL, we considered two key factors that would decide business impact - migration effort and migration time. To minimize effort for the migration of PostgreSQL databases, we leveraged Google Cloud’s DMS (Database Migration Service) as it is very easy to use and it does the heavy lifting by continuously replicating data from the source database to the destination Cloud SQL instance, while the source database is live in production.
How about migration time? For a terabyte-scale database, depending on the database structure, migration time can be considerably longer. Historically, we observed that DMS took around 3 hours to migrate a 1 TB database. In other cases, where the customer database structure was more complex, migration took longer. Thankfully, DMS takes care of this replication while the source database is live in production, so no downtime is required during this time. Nevertheless, our client would have to bear the cost of both the source and destination databases which for large databases, might be substantial. Meanwhile, if the database size increased, then replication could take even longer, increasing the risk of missing the customer's maintenance window for the downtime incurred during cutover operations. Since the customer’s maintenance window was monthly, we would have to wait for 30 more days for the next maintenance window, requiring the customer to bear the cost of both the databases for another 30 days. Furthermore, from a risk management standpoint, the longer the migration timeframe, the greater the risk that something could go wrong. Hence, we started exploring options to reduce the migration time. Even the slightest reduction in migration time could significantly reduce the cost and risk.
We explored options around tuning PostgreSQL’s database flags on the source database. While DMS has its own set of prerequisite flags for the source instance and database, we also found that flags like shared_buffers, wal_buffers and maintenance_work_mem helped accelerate the replication process through DMS. These flags needed to be set to a specific value to get the maximum benefit out of each of them. Once set, their cumulative impact was a reduction in time for DMS to replicate a 1 TB database by 4 hours, that is, reduction of 3.5 days for a 20 TB database. Let’s dive into each of them.
Shared Buffers
PostgreSQL uses two buffers – its own internal buffer and the kernel buffered IO. In other words, that data is stored in memory twice. The internal buffer is called shared_buffers, and it determines the amount of memory used by the database for the operating system cache. By default this value is set conservatively low. However, increasing this value on the source database to fit our use case helped increase the performance of read heavy operations, which is exactly what DMS does once a job has been initialized.
After multiple iterations, we found that if the value was set to 55% of the database instance RAM, it boosted the replication performance (a read heavy operation) by a considerable amount and in turn reduced the time required to replicate the data.
WAL Buffers
PostgreSQL relies on Write-Ahead Logging (WAL) to ensure data integrity. WAL records are written to buffers and then flushed to disk. The flag wal_buffers, determines the amount of shared memory used for WAL data that has not yet been written to disk - records that are yet to be flushed. We found that increasing the value for wal_buffers from the default value of 16MB to about 3% of the database instance’s RAM significantly improved the write performance by writing fewer but larger files to the disk at each transaction commit.
Maintenance Work Mem
PostgreSQL maintenance operations, such as VACUUM, CREATE INDEX, and ALTER TABLE ADD FOREIGN KEY, consume their own specific memory. This memory is referred to as maintenance_work_mem. Unlike other operations, PostgreSQL maintenance operations can only be performed sequentially by the database. Setting a value significantly higher than the default value of 64 MB meant that no maintenance operation would block the DMS job. We found that maintenance_work_mem worked best at the value of 1 GB.
Resize source instance to avoid performance impact
Each of these three flags tune how PostgreSQL utilizes memory resources. Hence, it was imperative that before setting these flags, we needed to upsize the source database instance to accommodate them. Without upsizing the database instances, we could have caused application performance degradation, as more than half of the total database memory would be allocated to the processes managed by these flags.
We calculated the memory required by the flags mentioned above, and found that each flag needed to be set to a specific percentage of the source instance’s memory, irrespective of the existing values that might be set for the flags:
shared_buffers: 55% of source instance’s memory
wal_buffers: 3% of source instance’s memory
maintenance_work_mem: 1 GB
We added the individual memory requirements by the flags, and found that 58% of the RAM at least will be taken up by these memory flags. For example, if a source instance used 100GB of memory, 58GB would be taken up by shared_buffers and wal_buffers, and an additional 1GB by maintenance_work_mem. As the original value of these flags was very low (~200MB), we upsized the RAM of the source database instance by 60% in order to ensure that the migration did not impact source performance on the application live in production.
Avoid connection error with WAL sender timeout flag
While using Google Cloud’s DMS, if the connection is terminated between DMS and the Cloud SQL instance during the ‘Full Dump in Progress’ phase of the DMS job, the DMS job fails and needs to be reinitiated. Encountering timeouts, especially while migrating a terabyte-scale database, would mean multiple days’ worth of migration being lost and a delay in the cutover plan. For example, if the connection of the DMS job for a 20TB database migration is lost after 10 days, the DMS job will have to be restarted from the beginning, leading to 10 days’ worth of migration effort being lost.
Adjusting the WAL sender timeout flag (wal_sender_timeout) helped us avoid terminating replication connections that were inactive for a long time during the full dump phase. The default value for this flag is 60 seconds. To avoid these connections from terminating, and to avoid such high impact failures, we set the value of this flag to 0 for the duration of database migration. This would avoid connections getting terminated and allowed for smoother replication through the DMS jobs.
Generally, for all the database flags we talked about here, we advised our customer to restore the default flag values once the migration completed.
Reduce downtime required for DMS limitations by automation
While DMS does the majority of database migration through continuous replication when the source database instance is live in production, DMS has certain migration limitations that cannot be addressed when the database is live. For PostgreSQL, the known limitations of DMS include:
Any new tables created on the source PostgreSQL database after the DMS job has been initialized are not replicated to the destination PostgreSQL database.
Tables without primary keys on the source PostgreSQL database are not migrated. For those tables, DMS migrated only the schema. This is no longer a limitation after the June 2022 product update.
The large object (LOB) data type is not supported by DMS.
Only the schema for Materialized Views is migrated; the data is not migrated.
All data migrated is created under the ownership of cloudsqlexternalsync.
We had to address these aspects of the database migration manually. Since our client’s database had data with the large object data type, tables without primary keys, and frequently changing table structures that cannot be migrated by DMS, we had to manually export and import that data after DMS did most of the rest of the data migration. This part of database migration required downtime to avoid data loss. For a terabyte-scale database, this data can be in the hundreds of GBs, which means higher migration time and hence higher downtime. Furthermore, when you have dozens of databases to migrate, it can be stressful and error-prone for a human to perform these operations while on the clock during the cutover window!
This is where automation helped save the day! Automating the migration operations during the downtime period not only reduced the manual effort and error risk, but also provided a scalable solution that could be leveraged for the migration of 100s of PostgreSQL database instances to Cloud SQL. Furthermore, by leveraging multiprocessing and multithreading, we were able to reduce the total migration downtime for 100s of GBs of data by 98%, thereby reducing the business impact for our client.
How do we get there?
We laid out all the steps that need to be executed during the downtime – that is, after the DMS job has completed its replication from source to destination and before cutting over the application to the migrated database. You can see a chart mapping out the sequence of operations that are performed during the downtime period in Fig 1.
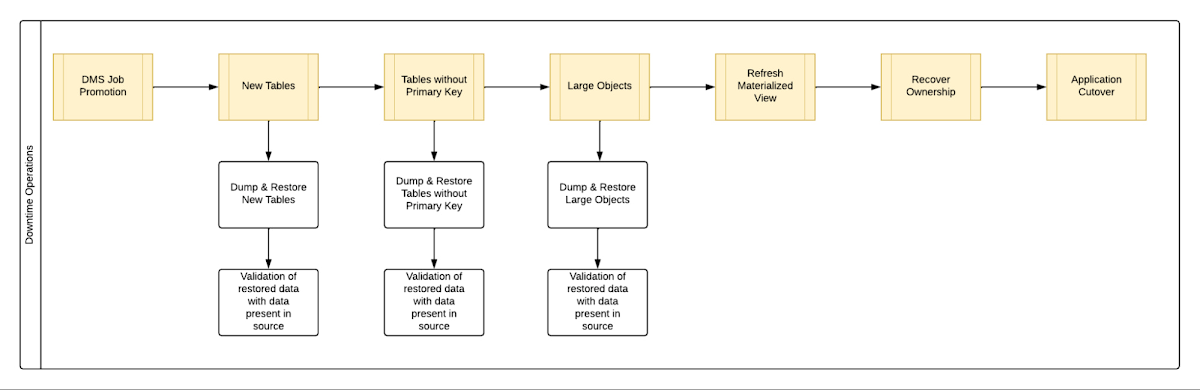
By automating all the downtime operations in this sequential approach, we observed that it took 13 hours for the entire downtime flow to execute for a 1 TB database. This included the migration of 250 MB in new tables, 60 GB in tables without primary keys and 150 GB in large objects.
One key observation we made was that, out of all the steps, only three steps took most of the time: migrating new tables, migrating tables without primary keys, and migrating large objects. These took the longest time because they all required dump and restore operations for their respective tables. However, these three steps did not have a hard dependency on each other as they individually targeted different tables. So we tried to run them in parallel as you can see in Fig 2. But the steps following them - ‘Refresh Materialized View’ and ‘Recover Ownership’ - had to be performed sequentially as they targeted the entire database.
However, running these three steps in parallel required upsizing the Cloud SQL instances, as we wanted to have sufficient resources available for each step. This led us to increase the Cloud SQL instances’ vCPU by 50% and memory by 40%, since the export and import operations depended heavily on vCPU consumption as opposed to memory consumption.
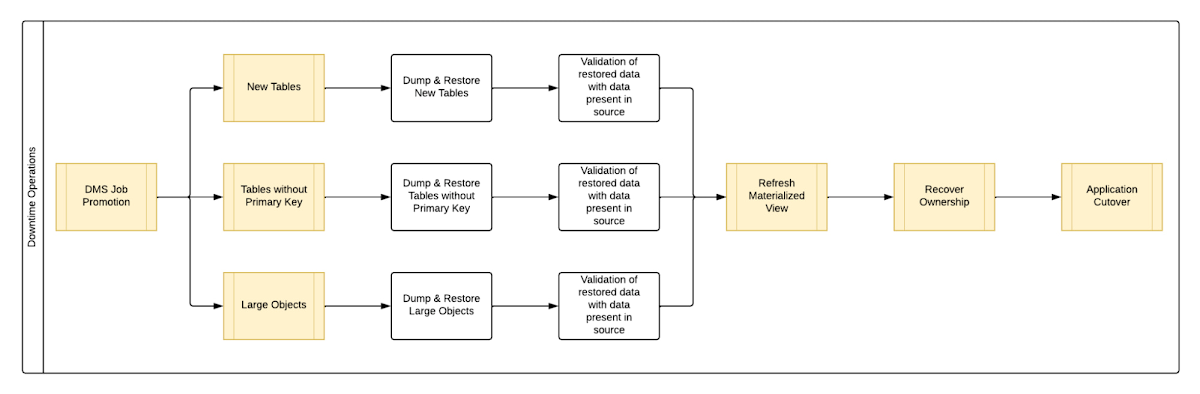
Migrating the new tables (created after the DMS job was initiated) and tables without primary keys was straightforward as we were able to leverage the native utilities offered by PostgreSQL - pg_dump and pg_restore. Both utilities process tables in parallel by using multiple threads– the higher the table count, the higher the number of threads that could be executed in parallel, allowing faster migration. With this revised approach, for the same 1 TB database, it still took 12.5 hours for the entire downtime flow to execute.
This improvement reduced the cutover downtime, but we still found that we needed a 12.5 hour window to complete all the steps. We then discovered that 99% of the time of downtime was taken up by just one step: exporting and importing 150 GB of large objects. It turned out that multiple threads could not be used to accelerate the dump and restore large objects in PostgreSQL. Hence, migrating the large objects single handedly extended the downtime for migration by hours. Fortunately, we were able to come up with a workaround for that.
Optimize migration of Large Object from PostgreSQL database
PostgreSQL contains a large objects facility that provides stream-style access to data stored in a special large-object structure. When large objects are stored, they are broken down into multiple chunks and stored in different rows of the database, but are connected under a single Object Identifier (OID). This OID can thus be used to access any stored Large Object. Although users can add large objects to any table in the database, under the hood, PostgreSQL physically stores all large objects within a database in a single table called pg_largeobjects.
While leveraging pg_dump and pg_restore for export and import of large objects, this single table - pg_largeobject, becomes a bottleneck as the PostgreSQL utilities cannot execute multiple threads for parallel processing, since it’s just one table. Typically, the order of operations for these utilities looks something like this:
1. pg_dump reads the data to be exported from the source database
2. pg_dump writes that data into the memory of the client where pg_dump is being executed
3. pg_dump writes from memory to the disk of the the client (a second write operation)
4. pg_restore reads the data from the client’s disk
5. pg_restore writes the data to the destination database
Normally, these utilities would need to be executed sequentially to avoid data loss or data corruption due to conflicting processes. This leads to further increase in migration time for large objects.
Our workaround for this single-threaded process involved two elements. First, with our solution, we eliminated the second write operation - write from memory to disk (point #3). Instead, once the data was read and written into memory, our program would begin the import process and write data to the destination database. Second, since pg_dump and pg_restore could not use multiple threads to process the large objects in just the pg_largeobjects table, we took it upon ourselves to develop a solution that could use multiple threads. The thread count was based on the number of OIDs in the table - pg_largeobjects, and break that single table into smaller chunks for parallel execution.
This approach brought down Large Object migration operation from hours to minutes, therefore bringing down the downtime needed for all operations to be completed that DMS cannot handle, for the same 1 TB database, from 13 hours to just 18 minutes. A reduction of ~98% in the required downtime.
Conclusion
After multiple optimizations and dry runs, we were able to develop a procedure for our client to migrate dozens of terabyte-scale PostgreSQL databases to Google Cloud SQL with a minimal business impact. We developed practices to optimize DMS-based migration by 15% using database flags and reduce downtime by 98% with the help of automation and innovation. These practices can be leveraged for any terabyte-scale migration of PostgreSQL databases to Google Cloud SQL to accelerate migration, minimize downtime and avoid performance impact on mission critical applications.
