Workaround PSC design to access Cloud SQL
Shashank Agarwal
Database Migrations Engineer, Google PSO
Eric Malloy
Partner Engineer, Google PSO
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialApril 18, 2024: Cloud SQL - PSC support is now GA. The approach described below is now deprecated for Cloud SQL. Please refer to this blog for the latest updates.
Private Service Connect (PSC) allows private consumption of services across VPC networks that belong to different groups, teams, projects, or organizations. In some cases it can be a much better alternative than VPC Peering, Shared VPC or other approaches of private connectivity. In this blog post we are sharing a workaround to use PSC to access Cloud SQL. In addition, this solution is applicable to other managed services too which do not natively support PSC such as Memorystore, AlloyDB and several other services dependent on Private Service Access (PSA) for connectivity.
Background
Many customers have requirements that cause them to adopt architectures where the resources that consume a Cloud SQL instance are in a different VPC Network or GCP Project. Peering VPCs do not work out of the box as Cloud SQL does not support Transitive Peering, nor is it desirable since it requires a lot of planning of IP Ranges.
PSC Solution Design
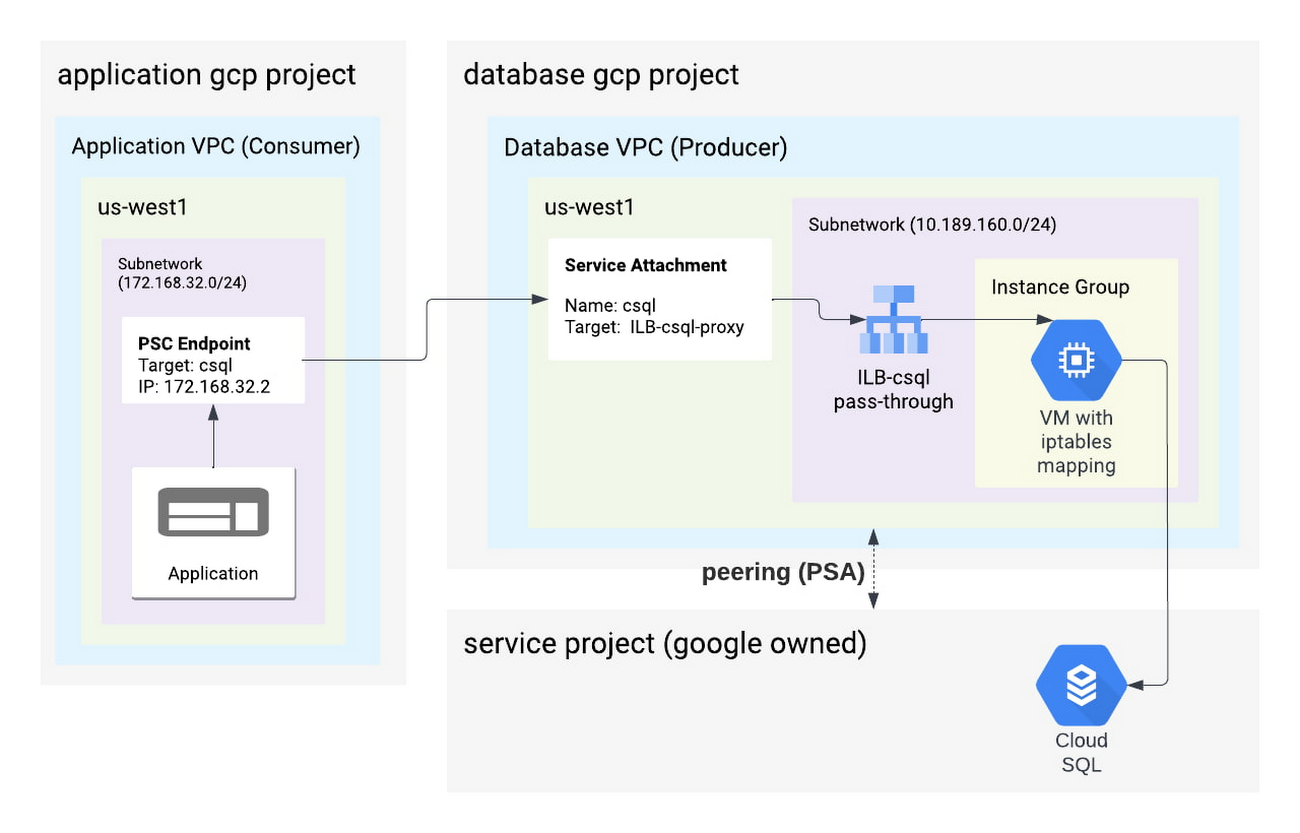
Figure 1
In an enterprise environment it is common to isolate the responsibilities among different teams with a decoupled architecture. Assuming the different application team(s) takes care of ownership of their respective application gcp project (left side of diagram). The database team(s) takes care of all the database resources for multiple applications in the database gcp project (right side of diagram). Each of these teams deploy resources in their own VPC network, giving them a high degree of autonomy and flexibility. In such architecture, the database team needs to expose the database as service to the various application(s).
The above diagram only shows 1:1 combination for simplicity, in-practice the relationship can be many-consumers : many-producers. This means each service attachment can have multiple psc endpoints in the same or different gcp projects.
Let us imagine a scenario where the client application is running on GCE/GKE and the persistence store is a Cloud SQL for MySQL database instance. Looking at Figure 1, the client application’s database requests connect to 172.168.32.2:3306 (the PSC endpoint). This IP is from the client VPC’s address space. Request originating from inside the GKE cluster, traverses subnetwork routes and lands at the PSC endpoint. The PSC endpoint is essentially a forwarding rule to the PSC service attachment that lives in the producer project.
The service attachment connects to the Internal Load Balancer (ILB). ILB connects to a Virtual Machine (via Instance Group) which has Private Service Access (PSA) connectivity to Cloud SQL. To forward the communication from VM to Cloud SQL, VM needs to be further configured with an IP Table rule such as below.
Note: Application could also be any other client platform which allows private connectivity to Cloud SQL. Also, the database engine could be Cloud SQL running PostgreSQL / Microsoft SQL Server or MySQL.
Overlaying DNS
It is common for enterprises to give a friendly domain name to the database ip addresses. In-order to keep both the producer and consumer networks decoupled it is best to create a separate private Cloud DNS instance on each VPC Network. Then assign the similar DNS name for the same logical resource (target database) in both networks, as a convention. Using the similar names can help both the teams to communicate more efficiently.
For example, Application VPC (consumer) has a DNS entry db-inst1.app1.acemy.com resolving to ip address 172.168.32.2. Therefore the application will connect using uri db-inst1.app1.acemy.com:3306. Similarly the Database VPC (producer) will have the entry db-inst1.dbs.acemy.com resolving to the ip address of Cloud SQL instance. Note the subtle difference in subdomains of dns (app1 vs dbs). The db-inst1.dbs.acemy.com dns name can be used in the IP Tables configuration (instead of Cloud SQL ip).
Although it is possible to have the exact same DNS name in both networks, doing so can lead to debugging and human communication issues.
Managing connectivity to multiple database instances
The database team could be providing its services to multiple different applications, hosting several different database engines. Providing connectivity to each database instance will require a PSC, ILB and VM resources. It can be handled by using either of the following architectures or a combination of both.
1. Simple deployment
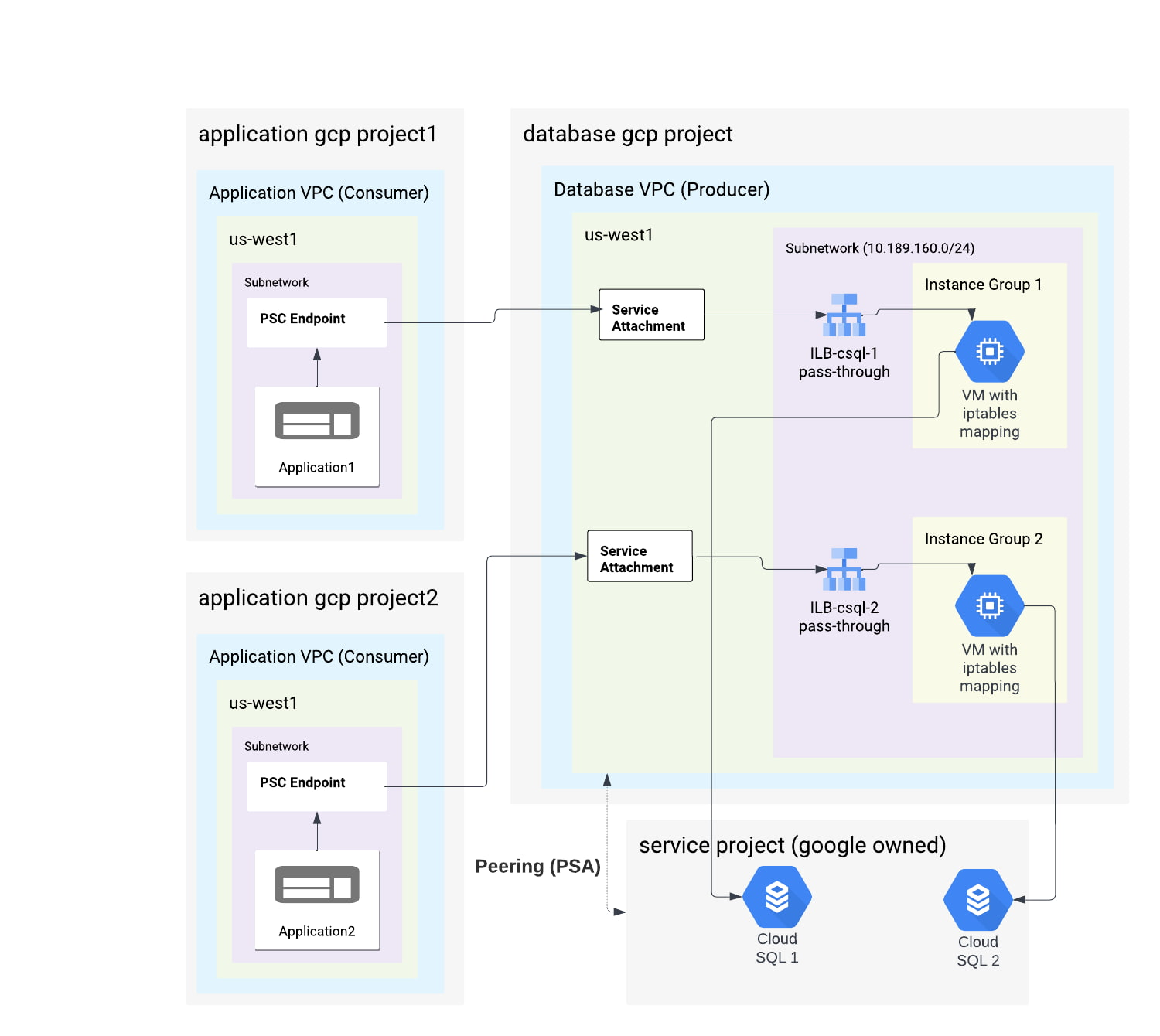
Figure 2
This architecture has separate gcp resources provisioned for connectivity per Cloud SQL instance. It can be more suitable for a multi-tenant application(s) or where there is risk of noisy neighbor problems. Therefore we recommend using this architecture.
2. Deployment with shared resources
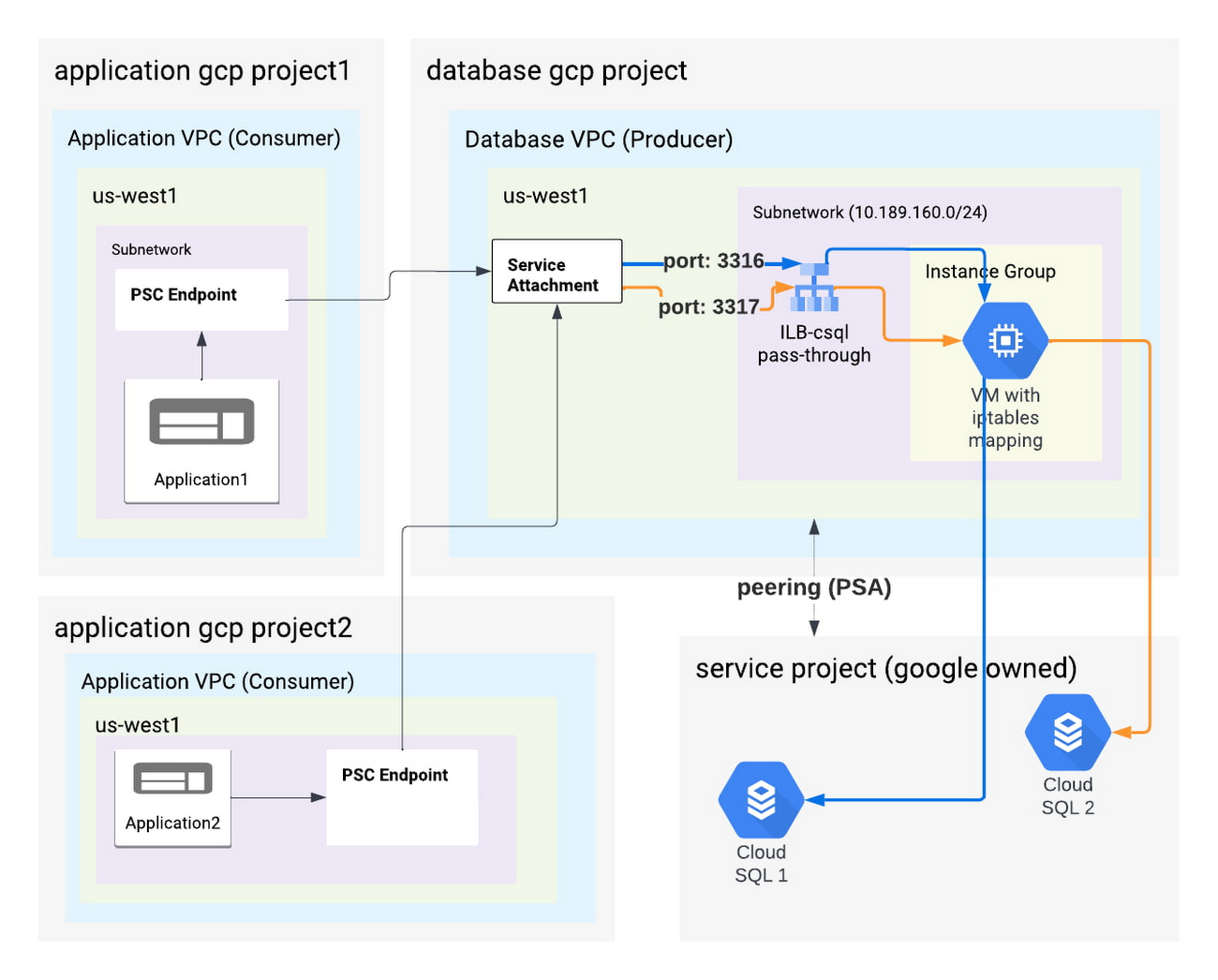
Figure 3
In this architecture, client applications will need to use different ports to connect per Cloud SQL instance, as shown in blue (port 3316) and orange (port 3317). The PSC endpoint and service attachment do not have any port binding. Therefore the same pass through ILB for the allowed ports can be used. VM should be configured with IP Tables route for each port to the respective Cloud SQL instance.
There are some cost benefits due to sharing of resources. However there are a few factors which you should consider before implementing
All application(s) will have a network path to all Cloud SQL instances, which may be a concern.
Complexity of updating ip-tables as new Cloud SQL instances come online.
Noisy neighbor problem, if one database instance has higher traffic then it may choke the common instance group.
Recommendations and best practices
PSC based solution has only one hop (in path from client application to Cloud SQL instance), which happens on the Instance Group’s VM. Hence it has minimal latency overhead. This is because PSC and ILB are part of GCP’s software defined constructs of VPC Network.
Instance group’s VMs network performance depends on the machine type, hence factor in the bandwidth requirements and choose VM size accordingly.
Prefer to use a VM operating system with the smallest footprint (like Ubuntu Minimal LTS), to reduce attack surface and therefore frequency for OS patching.
Use a managed instance group for high availability and automatically heal from zonal failure.
If database connections are long running stateful (like cached connection pool), avoid frequent restarts to the VM with IP Tables. Similarly avoid configurations which cause frequent auto scaling (and shrinking).
