Introducing tiered storage for Spanner
Matthew Mucklo
Software Engineer
Piyush Mathur
Group Product Manager
Today, we are excited to announce fully managed tiered storage for Spanner, a new capability that lets you use larger datasets with Spanner by striking the right balance between cost and performance, while minimizing operational overhead through a simple, easy-to-use, interface.
Spanner powers mission-critical operational applications at organizations in financial services, retail, gaming, and many other industries. These workloads rely on Spanner’s elastic scalability and global consistency to deliver always-on experiences at any size. For example, a global trade ledger at a bank or a multi-channel order and inventory management system at a retailer depend on Spanner to provide a consistent view of real-time data to make trades and assess risk, fulfill orders, or dynamically optimize prices.
But over time, settled trade records or fulfilled orders become less important to running the business, and instead drive historical reporting or legal compliance. These datasets don’t require the same real-time performance as “hot,” active, transactional data, prompting customers to look for ways to move this “cold” data to lower-cost storage.

However, moving to alternative types of storage typically requires complicated data pipelines and can impact the performance of the operational system. Manually separating data across storage solutions can result in inconsistent reads that require application-level reconciliation. Furthermore, the separation imposes significant limits on how applications can query across current and historical data for things like responding to regulators; it also increases governance touchpoints that need to be audited.
Tiered storage with Spanner addresses these challenges with a new storage tier based on hard disk drives (HDD) that is 80% cheaper than the existing tier based on solid-state drives (SSD), which is optimized for low-latency and high-throughput queries.
Beyond the cost savings, benefits include:
-
Ease of management: Storage tiering with Spanner is entirely policy-driven, minimizing the toil and complexity of building and managing additional pipelines, or splitting/duplicating data across solutions. Asynchronous background processes automatically move the data from SSD to HDD as part of background maintenance tasks.
-
Unified and consistent experience: In Spanner, the location of data storage is transparent to you. Queries on Spanner can access data across both SSD and HDD tiers without modification. Similarly, backup policies are applied consistently across the data, enabling consistent restores across data in both the storage tiers.
-
Flexibility and control: Tiering policies can be applied to the database, table, column, or a secondary index, allowing you to choose what data to move to HDD. For example, data in a column that is rarely queried, e.g., JSON blobs for a long tail of product attributes, can easily be moved to HDD without having to split database tables. You can also choose to have some indexes on SSD, while the data resides in HDD.
“At Mercari, we use Spanner as the database for Merpay, our mobile payments platform that supports over 18.7 million users. With our ever-growing transaction volume, we were exploring options to store accumulated historic transaction data, but did not want to take on the overhead of constantly migrating data to another solution. The launch of Spanner tiered storage will allow us to store old data more cost-effectively, without requiring the use of another solution, while giving us the flexibility of querying it as needed." - Shingo Ishimura, GAE Meister, Mercari
Let’s take a closer look
To get started, use GoogleSQL/PostgreSQL data definition language (DDL) to configure a locality group that defines storage options [‘SSD’ (default)/ HDD]. Locality groups are a mechanism to provide data locality and isolation along a dimension (e.g., table, column) to optimize performance. While configuring a locality group, you can also use 'ssd_to_hdd_spill_timespan' to specify the time for which data should be stored on SSD before it moves off to HDD as part of a subsequent compaction cycle.
Once the DDL has been configured, movement of data from SSD to HDD takes place asynchronously during weekly compaction cycles at the underlying storage layer without any user involvement.
HDD usage can be monitored from System Insights, which displays the amount of HDD storage used per locality group and the disk load at the instance level.
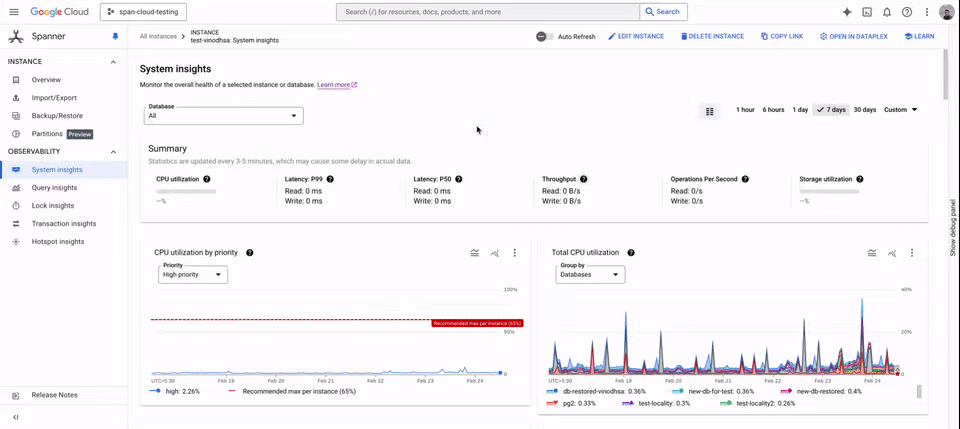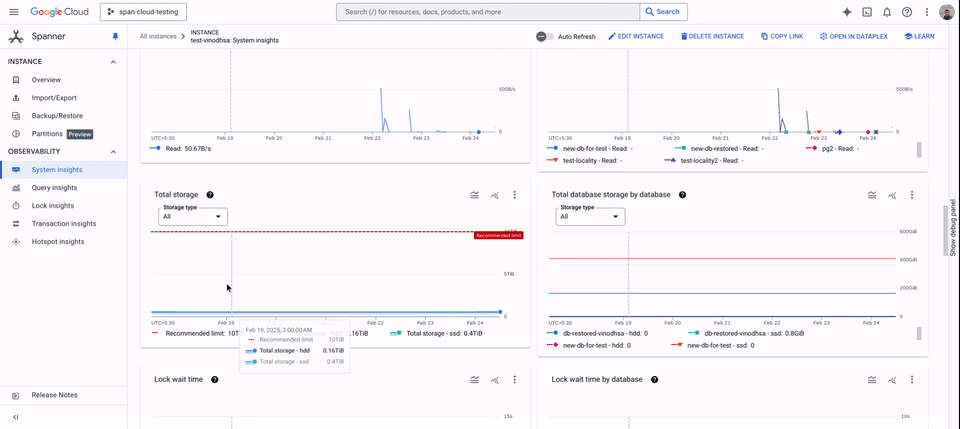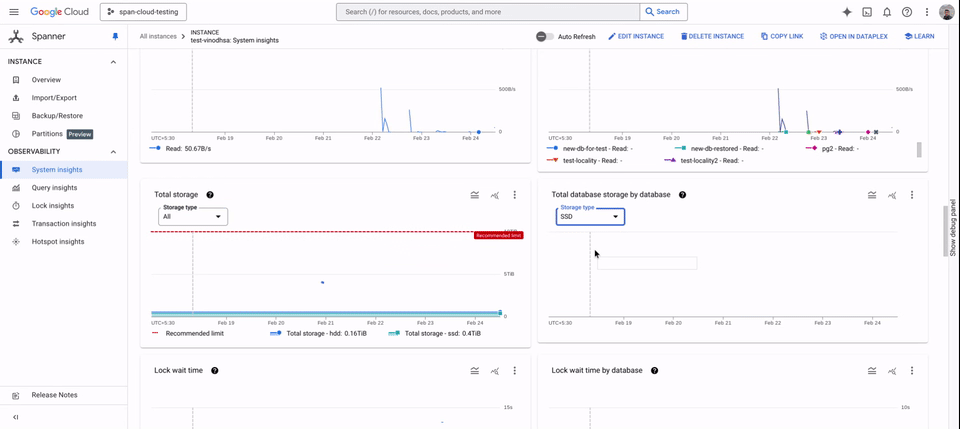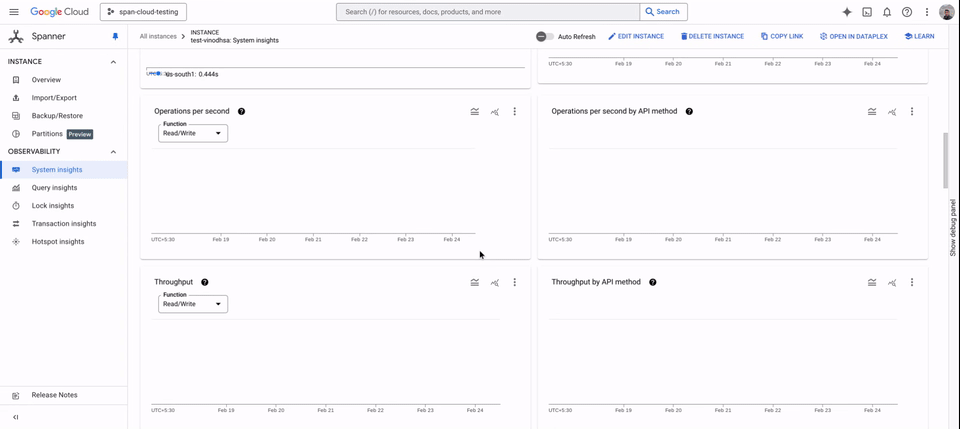
Spanner tiered storage supports both GoogleSQL and PostgreSQL-dialect databases and is available in all regions in which Spanner is available. This functionality is available with Enterprise/Enterprise Plus editions of Spanner for no additional cost beyond the cost of the HDD storage.
Get started with Spanner today
With tiered storage, customers can onboard larger datasets on Spanner by optimizing costs, while minimizing operational overhead through a unified customer experience. Visit our documentation to learn more.
Want to learn more about what makes Spanner unique and how to use tiered storage? Try it yourself for free for 90 days or for as little as $88 USD/month (Enterprise edition) for a production-ready instance that grows with your business without downtime or disruptive re-architecture.

