Introducing sample GenAI Databases Retrieval App – augment your LLMs with Google Cloud databases
Kurtis Van Gent
Senior Staff Software Engineer
Today we are announcing the open-source GenAI Databases Retrieval App, now available on GitHub. This project is a sample application that demonstrates production-quality practices for using techniques like Retrieval Augmented Generation (RAG) and ReACT to extend your gen AI application with information from Google Cloud databases.
Large language models (LLMs) have become increasingly powerful and accessible in recent years, opening up new possibilities for generative AI applications. LLMs can now generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way.
However, LLM-based applications also have some limitations – such as being unable to answer questions about data the model wasn’t trained on (such as live or real-time data), or hallucinating fake or misleading information. These limitations often compound on each other, leading an LLM to provide incorrect answers when asked to answer a question about information it doesn’t know.
The GenAI Database Retrieval App shows how to work around these limitations by extending LLM-based applications with information from a Google Cloud database, such as AlloyDB for PostgreSQL. Cloud databases provide a managed solution for storing and accessing data in a scalable and a reliable way. By connecting an LLM to a cloud database, developers can give their applications access to a wider range of information and reduce the risk of hallucinations.
Reducing hallucinations with RAG
One of the best tools for reducing hallucinations is to use Retrieval Augmented Generation (RAG). RAG retrieves some data or information, augments your prompt to the LLM, and allows it to generate more accurate responses based on the data included in the prompt. This grounds the model’s response, making it less likely to hallucinate. This technique also gives the LLM access to data it didn’t have when it was trained. And unlike fine-tuning, the information retrieved for RAG does not alter the model or otherwise leave the context of the request, making it suitable for use cases where information privacy and security are important.
One important limitation to RAG is prompt size. LLMs have limited ability to process prompts above a certain length (the context window) and longer prompts increase cost and latency. Because of this limitation, it’s important to only retrieve the most relevant information needed by the LLM to generate the correct response. Fortunately, databases are designed for precise queries to help retrieve only the most relevant data, especially when they combine support for both structured queries (using SQL) and semantic similarity using vector embeddings.
Using ReACT to trigger RAG
Another increasingly popular technique for use with LLMs is ReACT Prompting. ReACT (a combination of “Reason” and “Act”) is a technique for asking your LLM to think through verbal reasoning. This technique establishes a framework for the model (acting as an ‘agent’) to “think aloud” using a specific template — things like “thoughts,”, “actions,” and “observations.” Thoughts encourage the agent to think out what it needs to do, while LLMs interpret actions as concrete actions to take, and observations are the results of those actions.
The prompt/response to an LLM using ReACT might start like this:

In its response, the agent has indicated that it needs to use the lookup_flights action, our app can trigger this action and re-prompt the LLM with the results of that action as the observation:
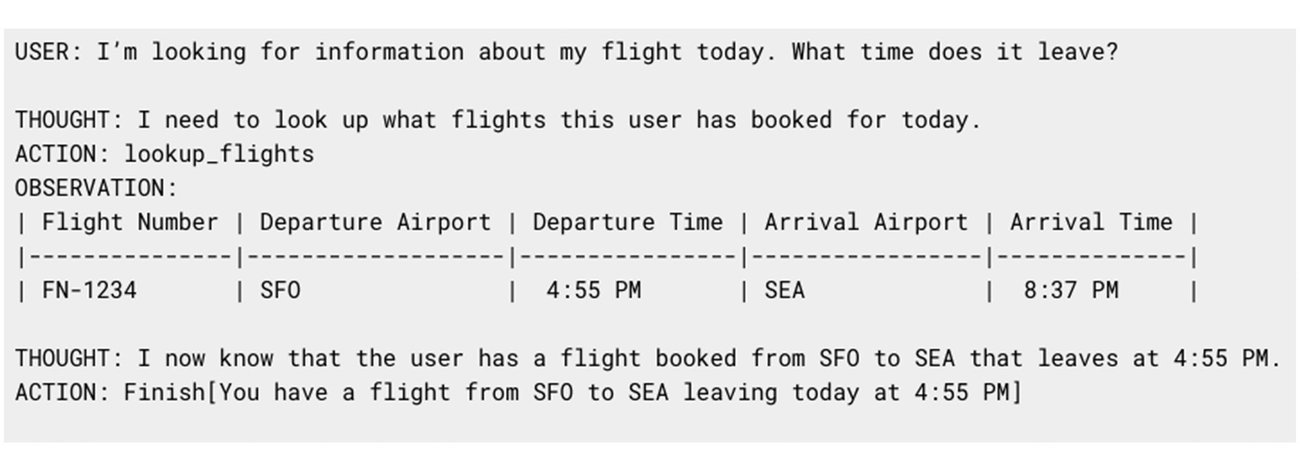
Many platforms support similar patterns to help extend your LLM’s capabilities: Vertex AI has Extensions, LangChain has Tools, and ChatGPT has plugins. The GenAI Databases Retrieval app can leverage this pattern to help an LLM understand what information it can access and decide when it needs to access it.
Running production-quality retrieval
While RAG + ReACT provides a pattern to provide an LLM with the data it needs, running in production can be a bit more work. There are several aspects you need to consider, such as security: how can you make sure your LLM doesn’t access data it shouldn’t? Another is scale – making sure your application can interact with the hundreds, thousands, or millions of users it needs to. There are many more factors to consider, including quality, latency, and cost as well.
One way to tackle these challenges is to run your extension as a separate service, and allow your LLM access through an API. This allows you to leverage best practices when connecting to your database (such as connection pooling or caching) and use existing frameworks or tools (like Oauth2) for things like user authentication. In the GenAI Database Retrieval app, the architecture looks something like this:
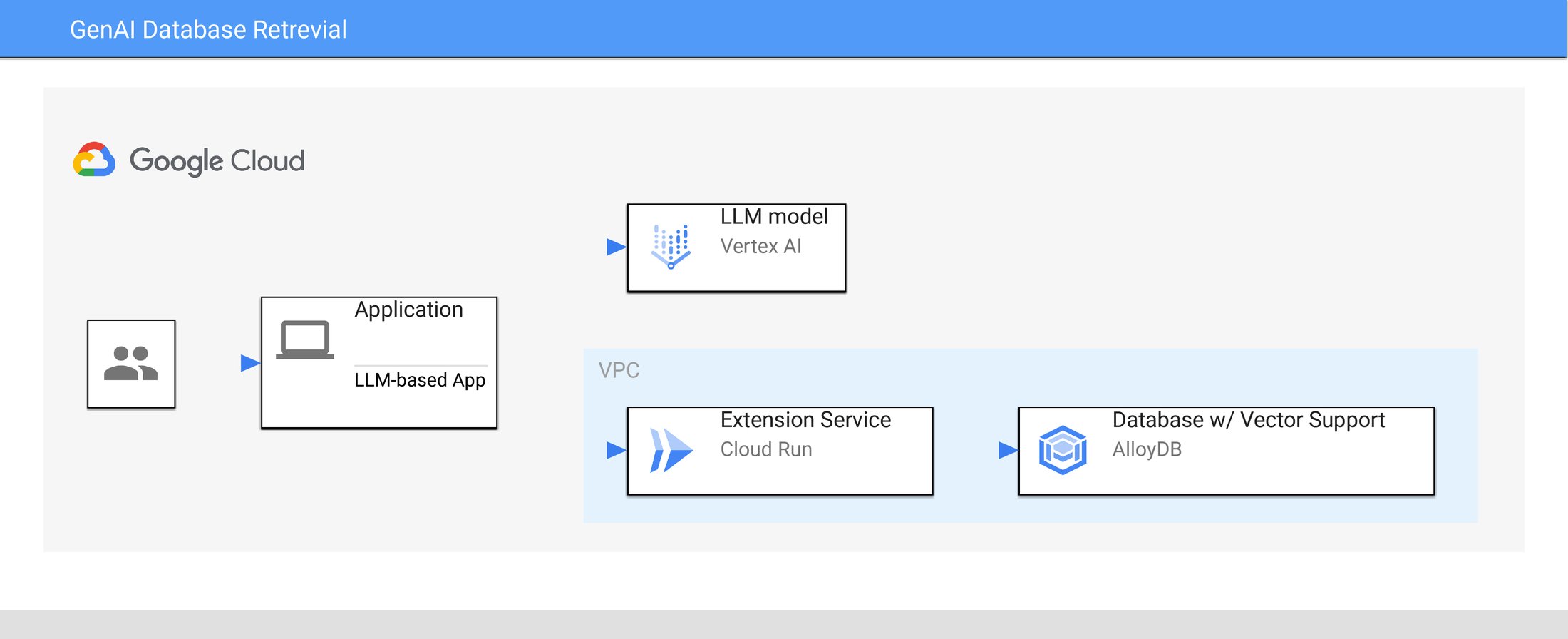
Our sample app handles the orchestration at the application level, using Vertex AI to host an LLM model, and based on the output of those prompts, triggering the retrieval service for additional information as required. Our retrieval service is backed by AlloyDB for PostgreSQL, offering enhanced PGVector performance for serving vector queries as well as the full range of enterprise database functionality.
Sample app: Airport Assistant
Our sample app wouldn’t be complete without a compelling, real-world narrative to help establish its effectiveness. We created a sample app, Airport Assistant, which accesses (synthetic) data such as airports, flights, and local amenities via AlloyDB. Pretend you're an imaginary passenger in San Francisco International Airport (SFO); Airport Assistant can help answer questions such as:
- Where can I get coffee near gate A6?
- Where can I find a gift for my friend?
- What flights are headed to New York City tomorrow?
We plan to grow this sample app over time, including expanding to more Google Cloud databases and more complicated journeys. The sample app is open source, and includes full instructions for setting it up and running yourself. Give it a try, and let us know what you think!
If you want to write your own extension, this sample app is a good starting point. You can check out the “Writing your own extension” section for more tips on customizing this app to use for your own applications.

