ScaNN for AlloyDB: The first PostgreSQL vector search index that works well from millions to billion of vectors
Alan Li
Software Engineer
Yannis Papakonstantinou
Distinguished Engineer, Databases, Google Cloud
Executive Summary - ScaNN for AlloyDB is the first Postgres-based vector search extension that supports vector indexes of all sizes, while providing fast index builds, fast transactional updates, small memory footprint, and accurate and fast search.
Many customers use AlloyDB for PostgreSQL to power sophisticated semantic search and generative AI use cases, performing vector search on 100 million to 1 billion+ vectors. At the same time, they want a large vector search index that works with the rest of their operational database, and the first place they look is the pgvector HNSW graph algorithm from the Postgres OSS community. pgvector extends the PostgreSQL SQL language to support combining SQL queries with filters and joins, together with vector search, an invaluable combination for modern applications.
We have supported the popular pgvector extension featuring HNSW in AlloyDB since 2023, and we are committed to continuing to do so. Over time we expect there to be multiple alternative vector indexing strategies and HNSW will be one of them. Currently pgvector HNSW does well on query performance for small datasets, for larger datasets the pgvector HNSW graph algorithm is not as effective. For workloads with very large numbers of vectors there can be challenges with the time and cost of building the index, the size of the resulting index, and the impaired performance of the index if it grows too large to fit in main memory. While there are situations in which pgvector is a good choice for vector indexing, for many AlloyDB workloads we needed to look for an alternative.
In that spirit, we released the ScaNN for AlloyDB extension in October 2024, providing a market-leading vector search solution for all use cases. ScaNN for AlloyDB incorporates ScaNN vector search technology developed by Google Research over the last 12 years. It is no surprise that ScaNN works well for large datasets since we use it in Google Search, YouTube, Ads, and other applications that involve hundreds of billions of vectors or more. It’s also a cost-effective and flexible option, providing an index that is pgvector-compatible, that works on all sizes, that has a 4x smaller memory footprint and has up to 4x better latency even for small datasets.
In the Benchmarks section of this blog, we show that ScaNN for AlloyDB builds indices for 1 billion vectors at up to 60x lower cost than other PostgreSQL systems. It also delivers up to 10x better latency when the indices (ScaNN and HNSW) don’t fit in main memory, since HNSW is a graph structure which can lead to expensive random access I/O when not in memory. We also show that ScaNN for AlloyDB is a competitive option for small sizes, offering up to 4x better latency than pgvector HNSW in addition to the faster index build time. Finally, in the Algorithms section, we provide the key reasons behind ScaNN for AlloyDB’s performance. Read on for more.
Benchmarks
For our performance tests, we experimented with two popular benchmark datasets: Glove-100 (~1 million vectors,100 dimensions) and BigANN-1B (1 billion vectors, 128 dimensions). We use the Glove-100 to show the performance of pgvector HNSW and of ScaNN for AlloyDB when the indices fit in main memory, and BigANN-1B when they do not. First, let’s take a look at search performance.
Search performance
We tested ScaNN for AlloyDB and pgvector HNSW 0.8.0 on OSS Postgres 15, both running on a 16 vCPU 128GB memory instance. We also tested pgvector HNSW 0.7.4 on a Cloud (we will refer to as Cloud Vendor X) on their 16 vCPU 128GB memory instance following the configuration and results published in a blog by Cloud Vendor X in early-2024. The indices fit in main memory for the Glove-100 benchmark but not for the BigANN-1B benchmark.
Naturally the performance of all the indices is much lower for BigANN-1B, where they don’t fit in main memory. However, the latency of pgvector HNSW is >4s (yes that is seconds!), which is unacceptable for online applications, while the ScaNN for AlloyDB delivers 10x better latency (431ms). This is important for use cases that require latency in the order of 100s of ms, but that also need to be cost-effective.
Note that given the generally much smaller footprint of ScaNN for AlloyDB, there are many use cases where the ScaNN for AlloyDB index fits in main memory while the pgvector HNSW index does not. For example, had we used an AlloyDB on a 64 vCPU 512GB memory instance, the BigANN-1B ScaNN for AlloyDB would deliver 30ms latency and thus ~2 orders magnitude of speedup over pgvector HNSW (which had a latency of >4 seconds)!

Index build performance
Now let’s look at how long it took us to build our indices. Many customers correctly complain that pgvector HNSW is too slow when creating the index for large datasets. This becomes evident when building the pgvector HNSW index for BigANN-1B. Note that for both PostgreSQL and Cloud Vendor X, we were unable to build the index with the 16 vCPU 128GB memory machine. We then made multiple labor-intensive attempts with larger machines & configurations, and ultimately used extra-large instances to successfully build the pgvector HNSW indices within reasonable time. But with ScaNN for AlloyDB, we used the same 16 vCPU 128GB memory instance that lists for about 1/10th the cost of these extra-large instances. Customers appreciate the convenience of building the index quickly for lower cost.

Algorithms
We showed in the Benchmarks section that the performance difference between ScaNN for AlloyDB and pgvector HNSW is very much amplified when the two vector indices do not fit in main memory. Indeed, the weakness of the HNSW algorithm is well known in the pgvector community, e.g. in this ticket. Furthermore, we showed that ScaNN for AlloyDB has a 4x smaller memory footprint, which allows ScaNN for AlloyDB to fit in memory in cases where pgvector HNSW does not. Fundamental differences between the data organization and algorithms of the two indices explain these differences. To understand why, let’s start with an explanation of the memory footprint difference.
HNSW is a graph-based index, whereas ScaNN is a tree-quantization-based index. Generally, in graph-based indices the index is a graph and each vector corresponds to a node of the graph. Each node (i.e., each vector) is connected to nodes that correspond to selected neighboring nodes. A typical recommendation is to connect each node to about m=20 other nodes, where m is the maximum number of neighbors per graph node. Furthermore, HNSW features multiple, hierarchical layers, where the upper layers provide entry points for the lower ones.
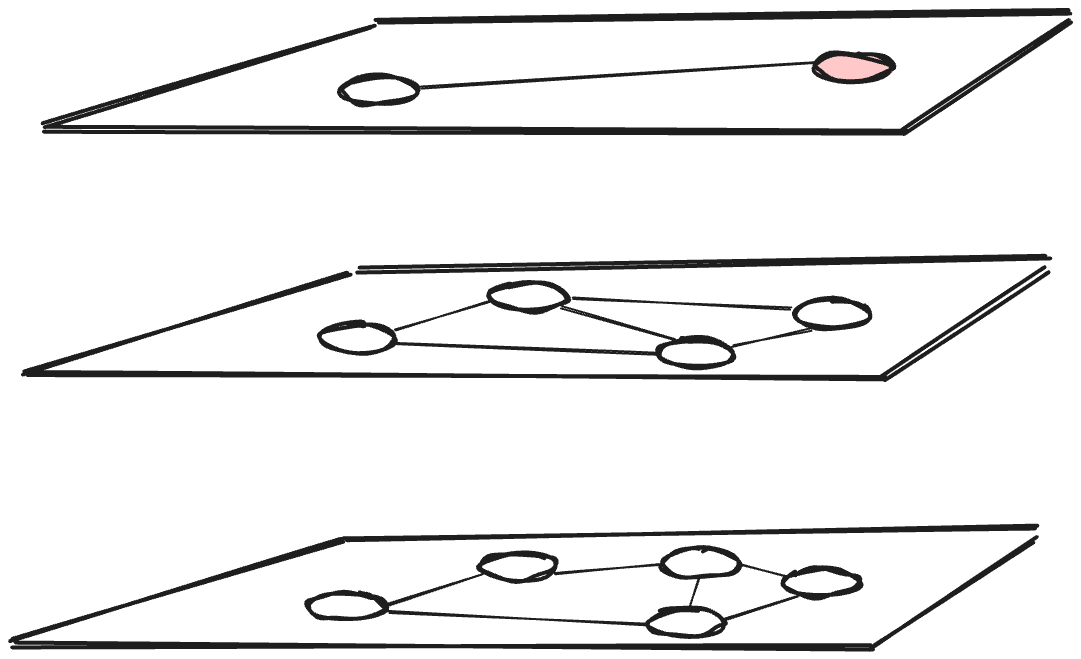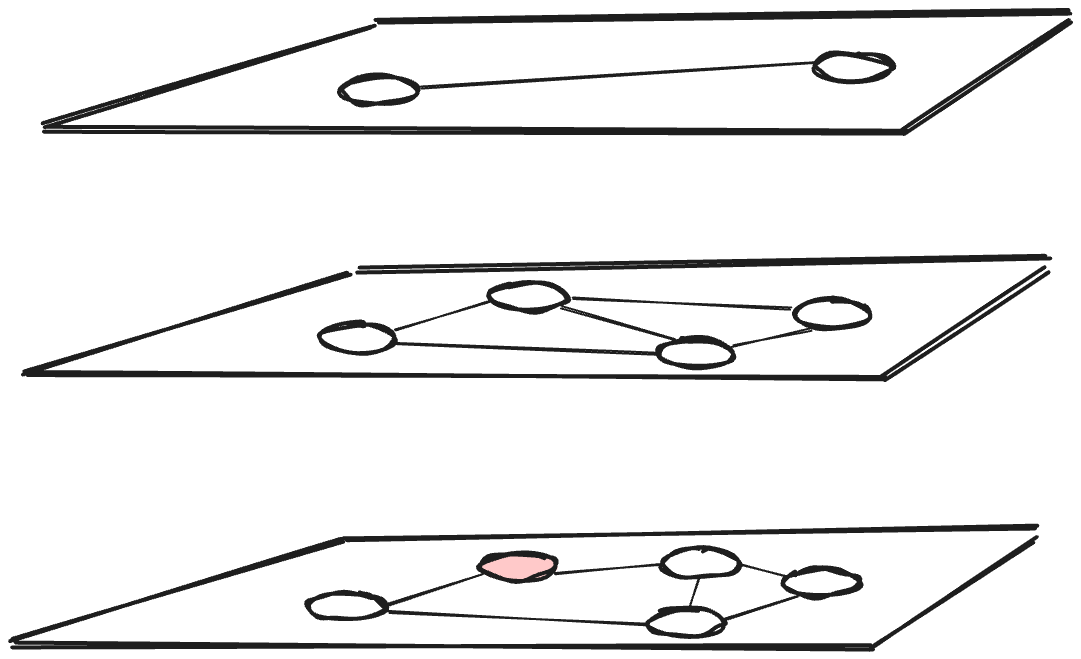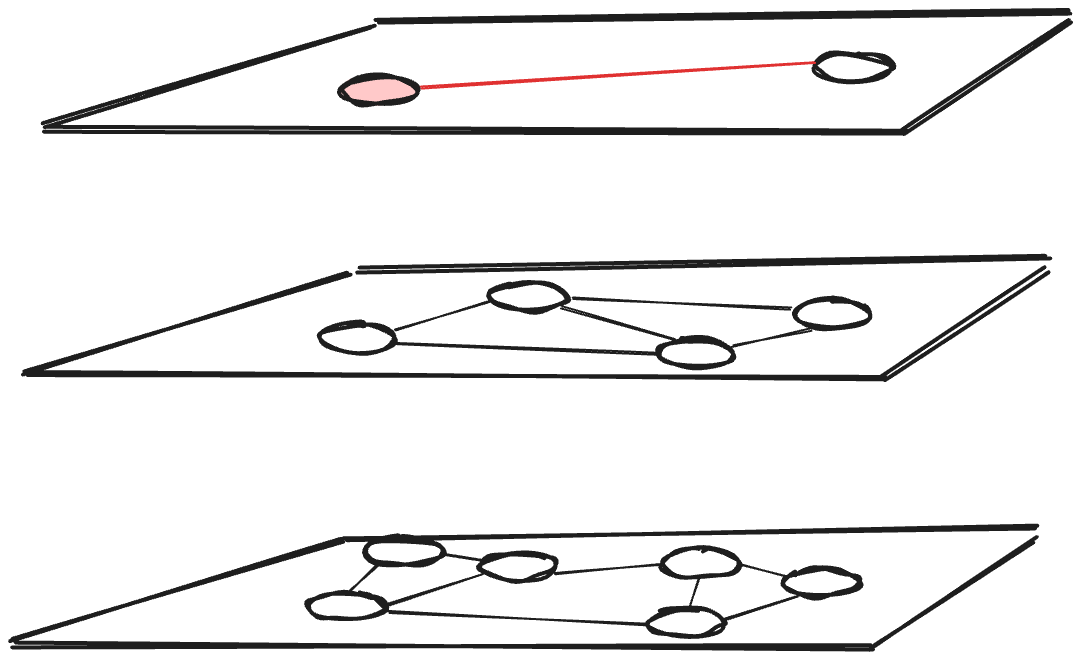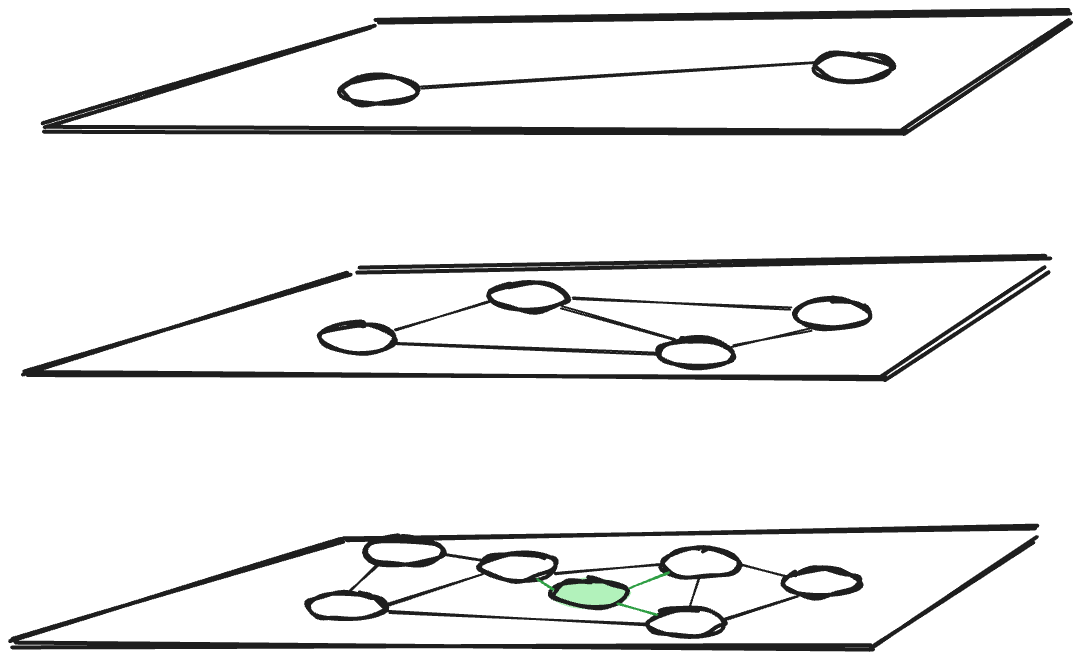
In contrast, ScaNN has a shallow-tree data structure, much like a B-tree. Each leaf node corresponds to a centroid and the leaf contains all the vectors that are close to this centroid. In effect, the centroids partition the space, as shown in the figure below depicting a two-level index. The memory footprint difference between ScaNN for AlloyDB and pgvector HNSW is due in large part to the fact that a tree has far fewer edges than a graph that connects the same number of nodes with 20 edges per node.

Next, let’s examine the difference in performance. Starting from the entry point, HNSW performs a greedy search in the top layer to find the nearest neighbors to the searched vector. The greedy search iteratively moves to the neighbors closest to the inserted vector until no closer neighbors can be found. It descends to the next lower layer and repeats the greedy search process until it reaches the bottom layer and the closest neighbors are returned.
Notice that with HNSW, the graph traversal access is random. Thus for a >100 million vector dataset where the graph nodes have to page in and out between buffer and disk, these random accesses cause a rapid deterioration of performance (see ticket #700). In contrast to HNSW’s random access, the ScaNN for AlloyDB index is cache-friendly, optimizes for block-based access when the index is in secondary storage and optimizes for efficient SIMD operations when the index is cached. As is often the case for out-of-memory database algorithms, sequential and block-based access outperforms random access.
Next steps
At Google, ScaNN vector search is integral to delivering the performance required for billion-user applications. And now, with ScaNN for AlloyDB, you can use it to power your own vector-based search applications. To learn more about the ScaNN for AlloyDB index, check out our introduction to the ScaNN for AlloyDB index, or read our ScaNN for AlloyDB whitepaper for an introduction to vector search at large, and then a deep dive into the ScaNN algorithm and how we implemented it in PostgreSQL and AlloyDB.
ScaNN for AlloyDB is generally available in AlloyDB. To get started with it, follow our quickstart guide to creating an AlloyDB instance, then read the documentation for some fast and easy vector queries. You can also now try AlloyDB for free with our 30-day free trials.
This post reflects the work of the AlloyDB semantic search team: Bohan Liu, Yingjie He, Bin Song, Peiqin Zhao, Jessica Chan. Thanks to the AlloyDB performance engineering team and others who contributed to the benchmarking results: Shrikant Awate, Rajeev Rastogi, Mohit Agarwal, Rishwitha Gunuganti, Hardik Shah, Jahnavi Malhotra, Hari Jeyamani. And a special thanks to the ScaNN team for their research.

