Spanner and PostgreSQL at Prefab: Flexible, reliable, and cost-effective at any size
Jeff Dwyer
Founder & CEO Prefab
TL;DR: We use Spanner’s PostgreSQL interface at Prefab, and we’ve had a good time. It’s easy to set up, easy to use, and — surprisingly — less expensive than other databases we’ve tried for workloads that need the option to scale. We’re already impressed by the performance to date, and we’re nowhere close to its limits yet.
PostgreSQL is akin to a Swiss Army knife in the world of databases — a fabulous OLTP database, capable of fulfilling the same roles as Redis for real-time access, MongoDB for schema flexibility, and Elastic for data that doesn’t neatly fit into tables or SQL. Its transaction integrity is also impeccable, and whether you need it for analytics queries or JSON storage, PostgreSQL handles it all with grace.
On the opposite end of the database spectrum are NoSQL databases like HBase, Cassandra, and DynamoDB. Unlike PostgreSQL’s versatility, these databases are notoriously challenging to set up, understand, and work with. At the same time, their inflexibility is offset by their ability to scale infinitely. NoSQL databases can support vast volumes of data and high read/write throughput, making them the titans of web-scale databases.
But is there a database that can deliver versatility and incredible scale?
Our encounter with Spanner suggests that perhaps we can have our cake and eat it too.
Why Spanner’s PostgreSQL interface?
At Prefab, we help developers ship apps faster with feature flags, dynamic logging, and secrets management. We use Spanner as a datastore for our customers’ configurations, feature flags, and generated client telemetry, which lets us build critical features, such as evaluation charts, that help us operate, scale, and make our product better.
Here are some of the key capabilities that drew us to Spanner:
-
99.99% uptime by default (multi-availability zone) or up to 99.999% uptime if you run in multi-region
-
Strong ACID transactions
-
Horizontal scaling — even for writes
-
PostgreSQL schemas, queries, and clients
In other words, Spanner promises the resilience and uptime of a Google-scale, massively-replicated database with the simplicity and portability that makes PostgreSQL so appealing.
How Prefab uses Spanner
Prefab’s architecture is split into two parts, so it was very reasonable for us to have a different database for each side, allowing us to choose the best tool for the job. Here are the two sides of our architecture:
-
Our core Prefab APIs that developers can use to serve their own customers via our software development kits (SDKs).
-
A web application, which our customers use to manage their configurations and monitor their apps.
Our feature flag services need to be able to scale to meet the demands of the downstream customers of the developers while also delivering extremely low latency. Java and the Java virtual machine (JVM), backed by Spanner, are the right choice for this high throughput, low latency, and high scalability domain. Our application’s user interface (UI) also needs to let us move quickly to ship features to our customers, but it has significantly lower throughput. For this part of our architecture, we use Ruby on Rails, React, and PostgreSQL.

Spanner in action
One feature that uses Spanner today is the backend for the volume tracking of our dynamic logging. Our SDK sees log requests in our customer applications and sends the volume for each log level and logger to Spanner. We then use this data to help users figure out how many log statements will output to their log aggregator if they turn on logging at various levels using the Prefab UI.
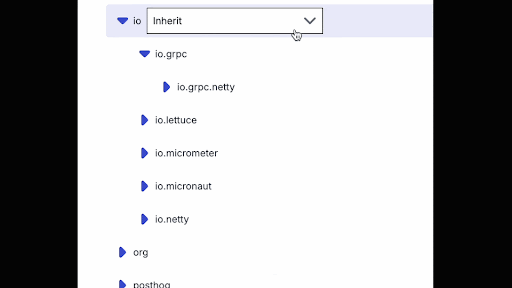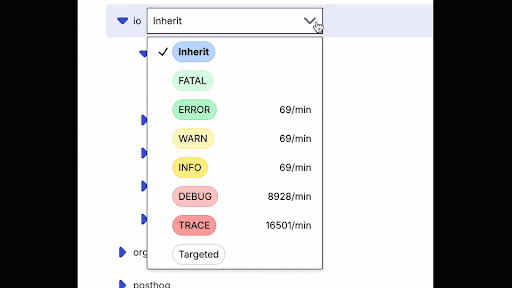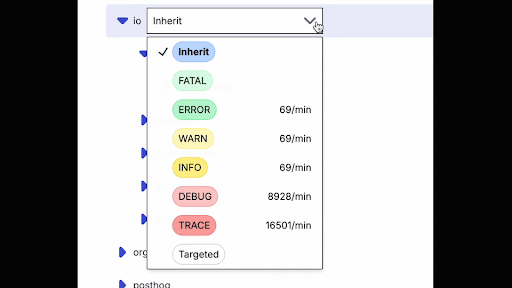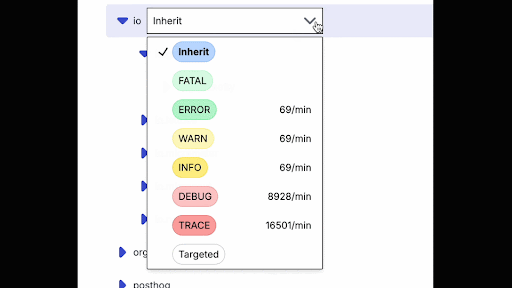
To enable this capture, we have a table of the following shape:
This table scales pretty quickly and unpredictably as clients report back the telemetry for our dynamic logging. Yes, you could also do this in a time series database or some smart things with windowing and removing old data. For the purposes of this post, though, this is an easy way to demonstrate how Spanner helps manage performance for a table that has a bunch of data.
So does it scale?
This example table is not a perfect benchmark here, but it does give you an idea of what easy vertical scaling looks like. I ran the query select project_env_id, count(id) from logger_rollup group by 1 over the table above, which had 37M rows and was around 11GB at the time.
I did this for a varying amount of Processing Units (PUs), giving Spanner about 30 seconds or so to reflect the changes.

The real key here is that scaling this was extremely easy; you can change the number of PUs, from 100 to 500 or even 4000, and Spanner handles the rest — zero downtime and virtually instantaneous at this scale.
100X more storage and no maintenance downtime for ⅓ of the cost
In production, we need to replicate Prefab’s database across multiple zones. Reliability is paramount for feature flags and dynamic configuration systems as they are single points of failure due to their very nature.
We take a belt and suspenders approach here, but multi-availability zone replication and Spanner’s uptime SLA ensures our “belt” is very strong. To achieve this with PostgreSQL on its own, you would need to triple the bill of a single instance. However, Spanner pricing includes replication and automatic failover out of the box. You also get a ton of storage capacity with each node — up to 10TB with Spanner’s recent updates — and you only pay for the bytes you actually use. For us, this makes the comparison look like this:

At a small scale, the best practice of having a database instance per environment can start to be annoyingly expensive. When I first investigated Spanner a few years ago, this was a sticking point because the smallest instance size was one node, or 1,000 PUs. Since then, Spanner’s scale has evolved to scale down to less than a full node, making an easy choice an even easier decision for us. It also gives us the option to scale up whenever we need it, without downtime or expensive rearchitecture in our applications.
Recent improvements to Spanner and the Google Cloud ecosystem
We initially had some bumps in the road using the PostgreSQL interface for Spanner. However, Google Cloud is constantly innovating and improving its products and services, so we’ve been super excited that most of the original things we encountered have been addressed.
Some of our favorite updates include:
- Query editor: It’s darn convenient to have a query editor right in the Google Cloud console, which allows us to investigate and tune any queries that exhibit poor performance.

- Key Visualizer: If you’re looking at big volume NoSQL databases with HBase, row keys become pretty important to understand. The Key Visualizer allows us to analyze Spanner data access patterns over time and diagnose common issues that cause hotspots. I’m excited to see that there are nice tools included to help understand key distribution.

Looking forward, we plan to explore how we can use Ruby on Rails directly on Spanner. In particular, we believe Spanner could be an intriguing option for new projects, especially those with tables likely to scale significantly — like audit logs or histories — Spanner could be an intriguing option.
Summary
We have a lot of previous experience using HBase and PostgreSQL, but we’re pretty excited about our decision to adopt Spanner as the horizontally scalable operational database of choice for Prefab. We’ve found it to be easy to use for our needs, delivering all the same scaling properties as HBase, without the headaches of doing it ourselves. Fewer points of potential failure and fewer things to manage save us time and money.
If you have some big tables that scare you, but you haven’t looked beyond PostgreSQL, you might consider expanding your horizons. Spanner’s PostgreSQL interface gives you the portability and ease-of-use of PostgreSQL with the proven reliability and scale of Spanner and Google Cloud.
Plus atomic clocks! How cool is that?
Get Started
You can get started with Spanner today for free for 90 days or as little as $65/month after that. We’d also be happy to connect with you and love it if you’d explore the product we’ve built on top of Spanner by learning more about our Feature Flags, Dynamic Logging and Secret Management.

